# Churn Detection AI Blueprint - deprecated from 11/2024
# Batch-Predict
Churn detection applies metrics to identify customers or clients who may be thinking of leaving one company for another. Essentially attrition, churn is the percentage of consumers who stopped using a provider’s products or services during a certain time period. Reducing churn rates is an important business goal and applying metrics to detect potential churners is an effective way to achieve these churn reductions.
# Purpose
Use this batch blueprint to run in batch mode a pretrained tailored model that predicts whether a customer or client is likely to churn. The model can be trained using this counterpart’s training blueprint, after which the trained model can be uploaded to the S3 Connector.
To run this blueprint, replace the model (optional) and data preprocessing artifacts (such as scalers and encoders) in the S3 Connector’s churn_data directory by providing a list of files (artifacts and test file) and modifying the parameters in YAML file accordingly:
- -churn.csv
- -columns_list.csv
- -mis_col_type.csv
- -my_model.sav
- -one_hot_encoder
- -ordinal_enc
- -processed_col.csv
- -std_scaler.bin
# Deep Dive
The following flow diagram illustrates this batch-predict blueprint’s pipeline:
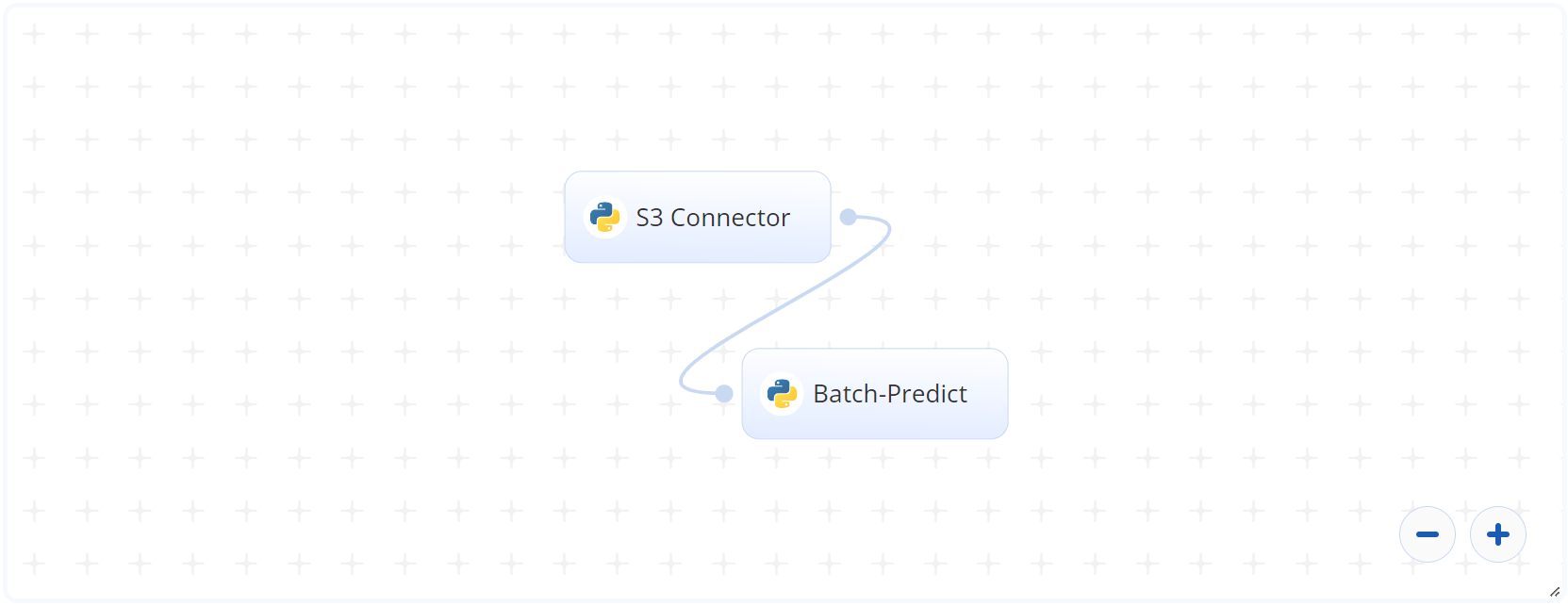
# Flow
The following list provides a high-level flow of this blueprint’s run:
- In the S3 Connector, the user provides the directory path where the churn data is stored.
- In the Batch Predict task, the user provides the S3 paths for parameters such as
datafile,model_dir, andcolumns_list. - This blueprint outputs a CSV file with customers/clients and their churn likelihood probabilities.
# Arguments/Artifacts
For more information on this blueprint’s tasks, its inputs, and outputs, click here.
# Inputs
--recommendation_fileis file that contains recommendations for the algorithm to use--original_col.csvis the original file column names and average/random values as a single row--data_df.csvis the processed file (after one hot encoding, label encoding, missing value treatment)--processed_col.csvis the processed file (after one hot encoding, label encoding, missing value treatment) but with only 1 row (for batch predict)--recommendation.csvis the file that contains recommendations for the algorithm to use--std_scaler.binis the standard scaler saved object after fitting scaler on training data
# Outputs
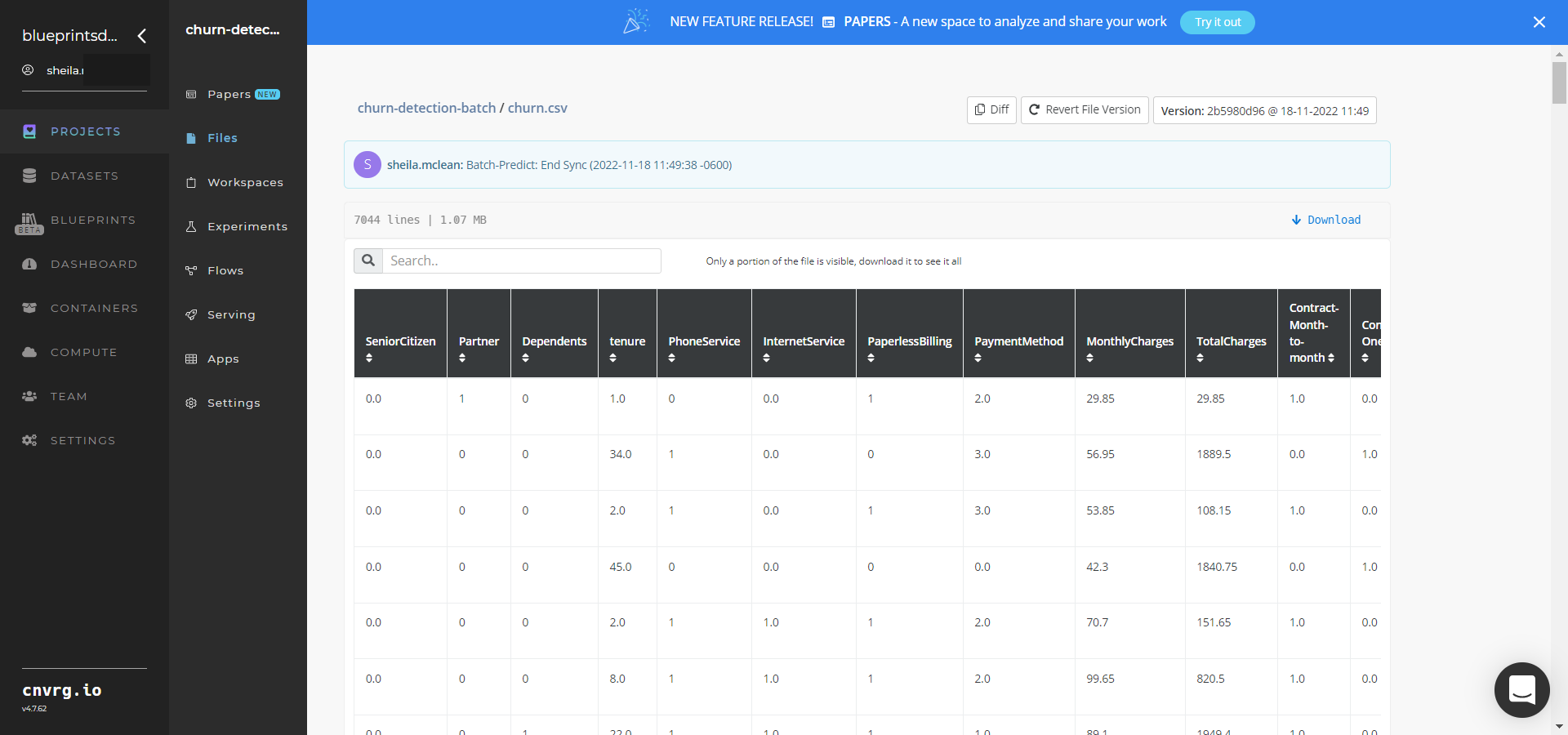
--churn.csvis the file name containing the customers/clients and their churn likelihood probabilities.
# Instructions
NOTE
The minimum resource recommendations to run this blueprint are 3.5 CPU and 8 GB RAM.
Complete the following steps to run the churn-dectector model in batch mode:
- Click the Use Blueprint button. The cnvrg Blueprint Flow page displays.
- Click the S3 Connector task to display its dialog.
- Within the Parameters tab, provide the following Key-Value information:
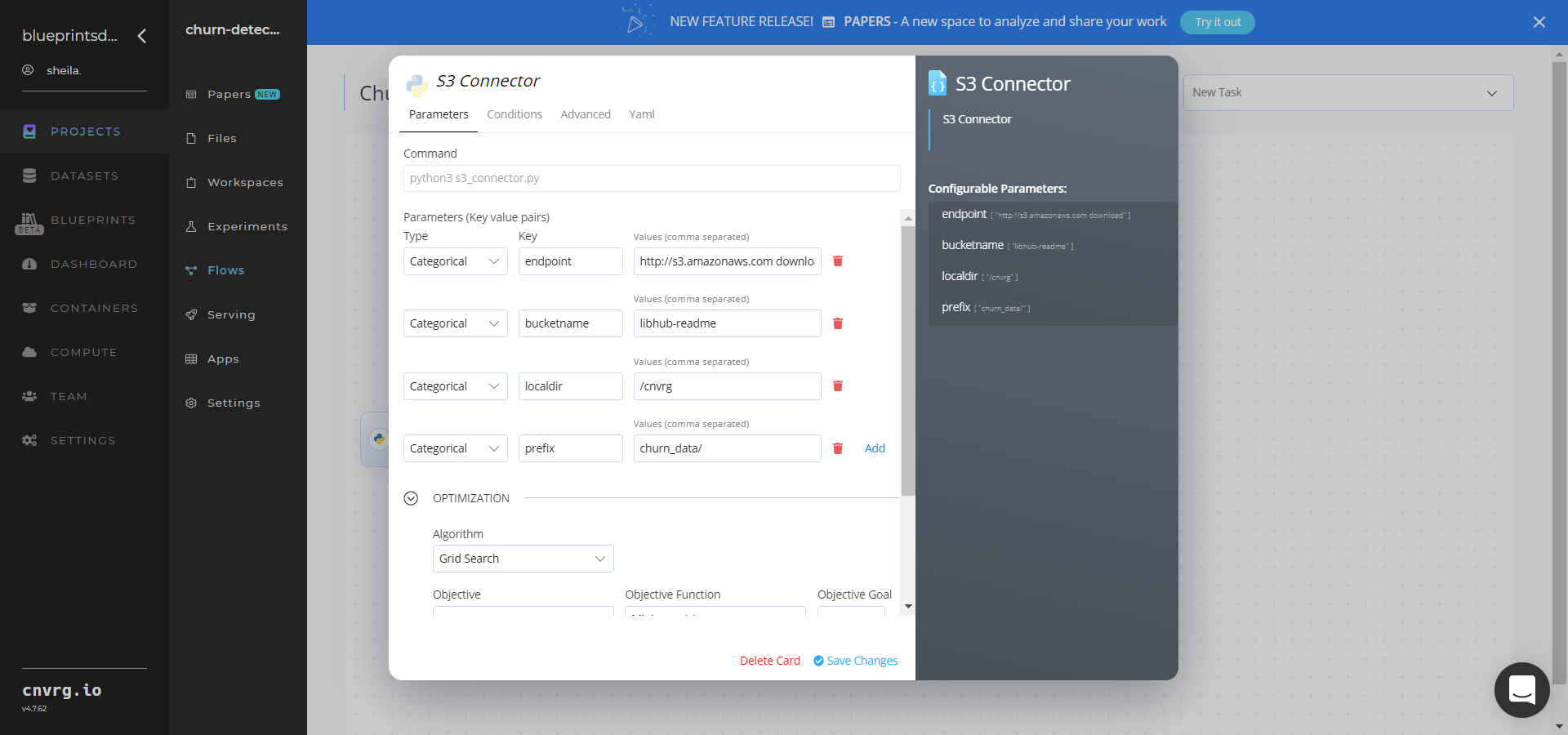
- Key:
bucketname− Value: provide the data bucket name - Key:
prefix− Value: provide the main path to the data folders
- Key:
- Click the Advanced tab to change resources to run the blueprint, as required.
- Within the Parameters tab, provide the following Key-Value information:
- Click the Batch-Predict task to display its dialog.
Within the Parameters tab, provide the following Key-Value pair information:
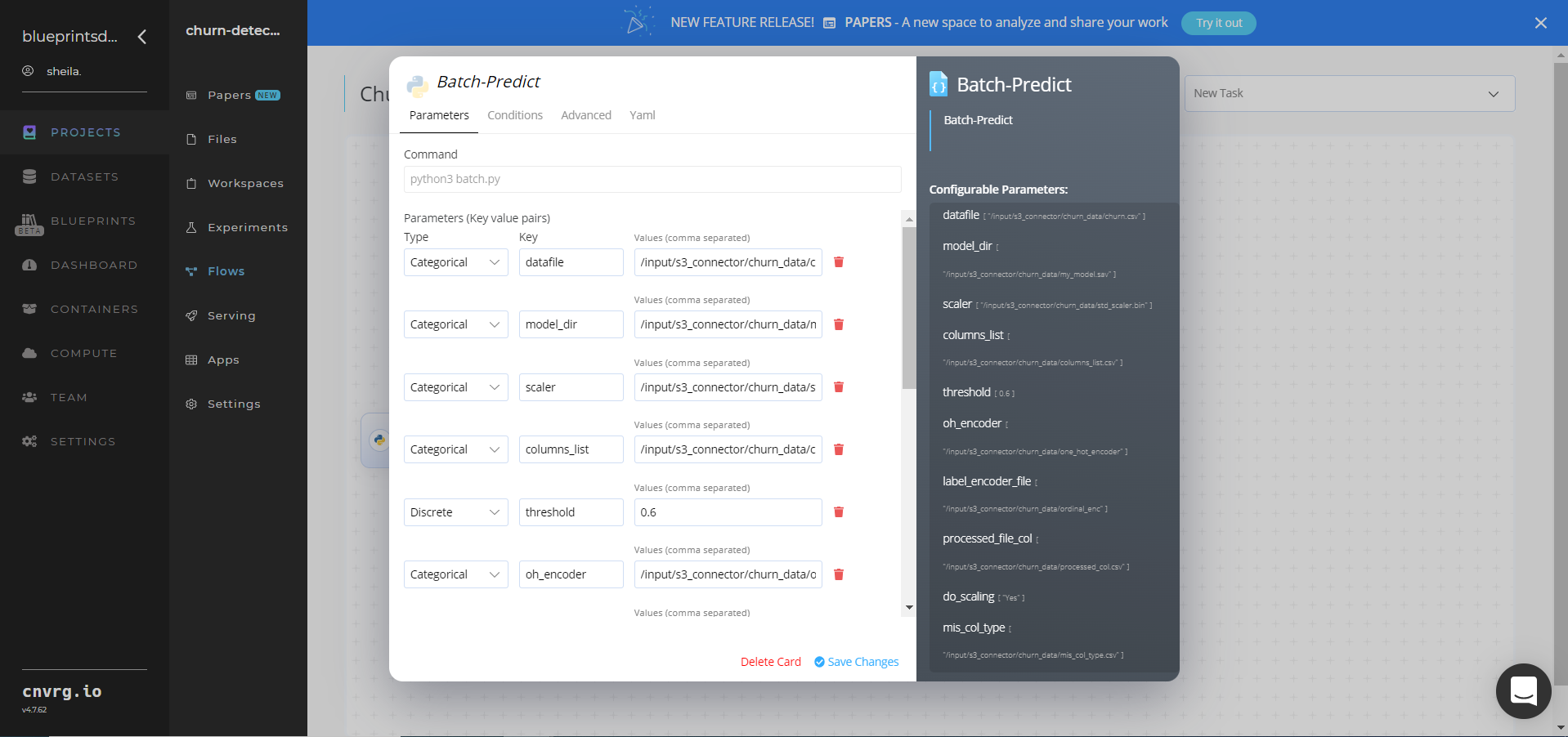
- Key:
datafile− Value: provide the S3 path to the churn data file in the following format:/input/s3_connector/churn_data/churn.csv - Key:
model_dir− Value: provide the S3 pagh to the saved model in the following format:/input/s3_connector/churn_data/my_model.sav - Key:
scaler− Value: provide the S3 path to the scaler in the following format:/input/s3_connector/churn_data/std_scaler.bin - Key:
columns_list− Value: provide the S3 path to the columns list in the following format:/input/s3_connector/churn_data/columns_list.csv - Key:
oh_encoder− Value: provide the S3 path to the one hot encoder in the following format:/input/s3_connector/churn_data/one_hot_encoder - Key:
label_encoder_file− Value: provide the S3 path to the label encoder file in the following format:/input/s3_connector/churn_data/ordinal_enc - Key:
processed_file_col− Value: provide the S3 path to the processed file column in the following format:/input/s3_connector/churn_data/processed_col.csv - Key:
mis_col_type− Value: provide the S3 path to the missed column type in the following format:/input/s3_connector/churn_data/mis_col_type.csv
NOTE
You can use the prebuilt data example paths provided.
- Key:
Click the Advanced tab to change resources to run the blueprint, as required.
- Click the Run button.
 The cnvrg software deploys a churn-detector model that predicts churn likelihood probabilities for customers and clients.
The cnvrg software deploys a churn-detector model that predicts churn likelihood probabilities for customers and clients. - Select Batch Predict > Experiments > Artifacts and locate the batch output CSV file.
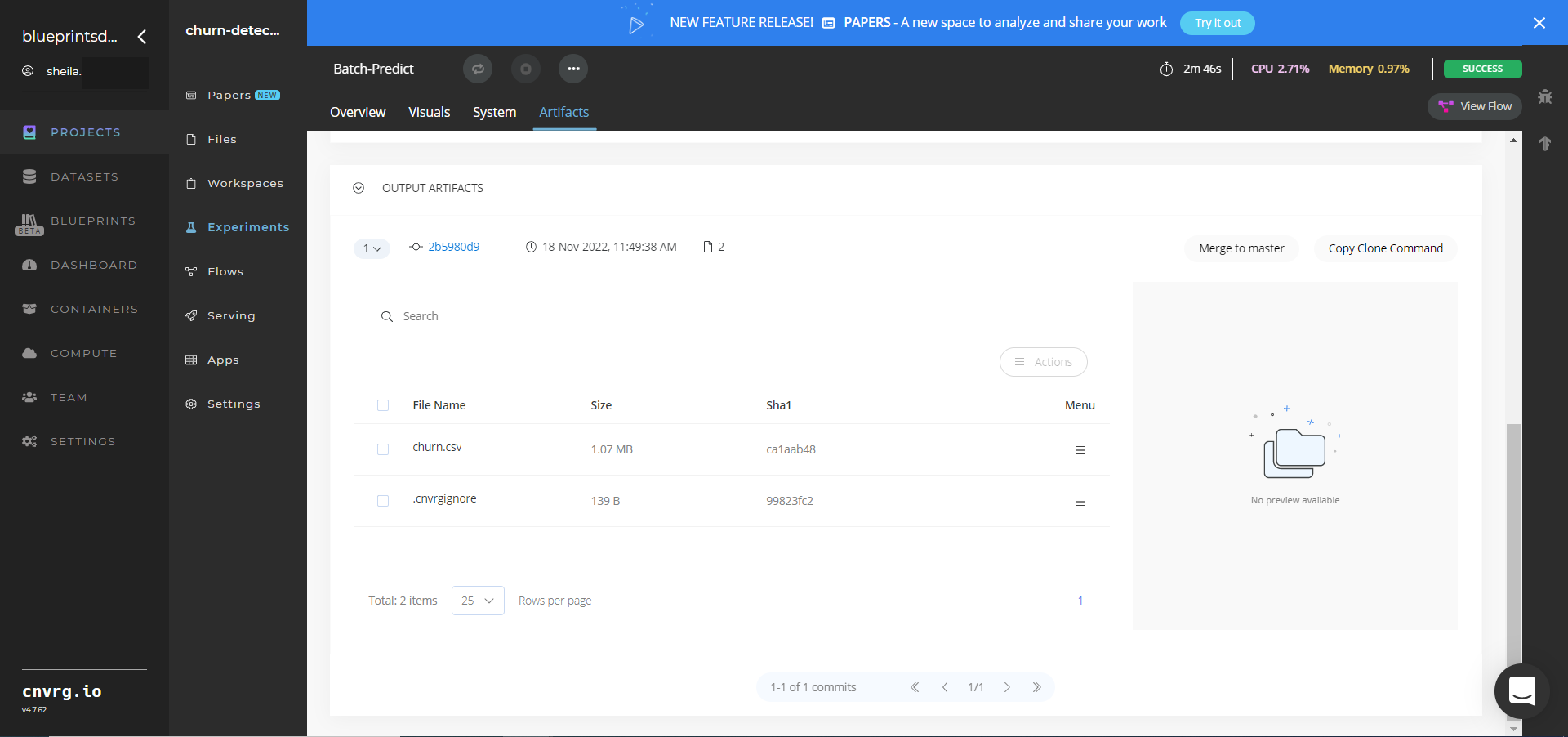
- Select the churn.csv File Name, click the Menu icon, and select Open File to view the output CSV file.
A custom churn-detector model that can predict churn likelihood probabilities for customers and clients has now been deployed in batch mode. For information on software version and release details, click here.
# Connected Libraries
Refer to the following libraries connected to this blueprint:
# Related Blueprints
Refer to the following blueprints related to this batch blueprint:
- Churn Detection Training
- Churn Detection Inference
- Sentiment Analysis Train
- Sentiment Analysis Inference
- Virtual Agent Train
- Virtual Agent Inference
# Inference
Churn detection applies metrics to identify customers or clients who may be thinking of leaving one company for another. Essentially attrition, churn is the percentage of consumers who stopped using a provider’s products or services during a certain time period. Reducing churn rates is an important business goal and applying metrics to detect potential churners is an effective way to achieve these churn reductions.
# Purpose
Use this inference blueprint to immediately predict results for whether a customer or client is likely to churn. To use this pretrained churn-detector model, create a ready-to-use API-endpoint that can be quickly integrated with your data and application.
This inference blueprint’s model was trained using telecom customer data. To use custom churn data according to your specific business, run this counterpart’s training blueprint, which trains the model and establishes an endpoint based on the newly trained model.
# Instructions
NOTE
The minimum resource recommendations to run this blueprint are 3.5 CPU and 8 GB RAM.
Complete the following steps to deploy this churn-detector API endpoint:
- Click the Use Blueprint button.
- In the dialog, select the relevant compute to deploy the API endpoint and click the Start button.
- The cnvrg software redirects to your endpoint. Complete one or both of the following options:
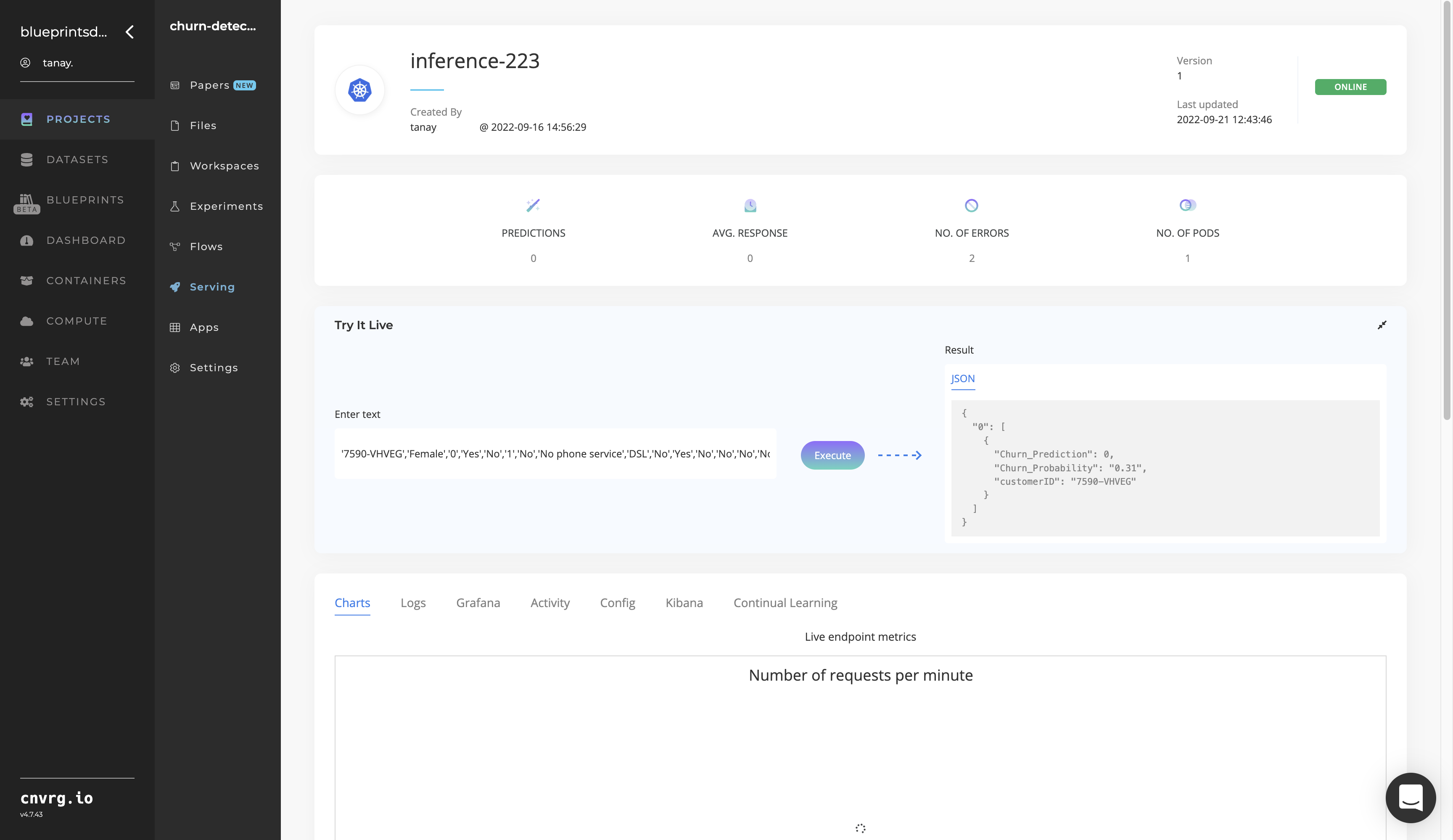
- Use the Try it Live section with a relevant user ID to check the model’s prediction accuracy.
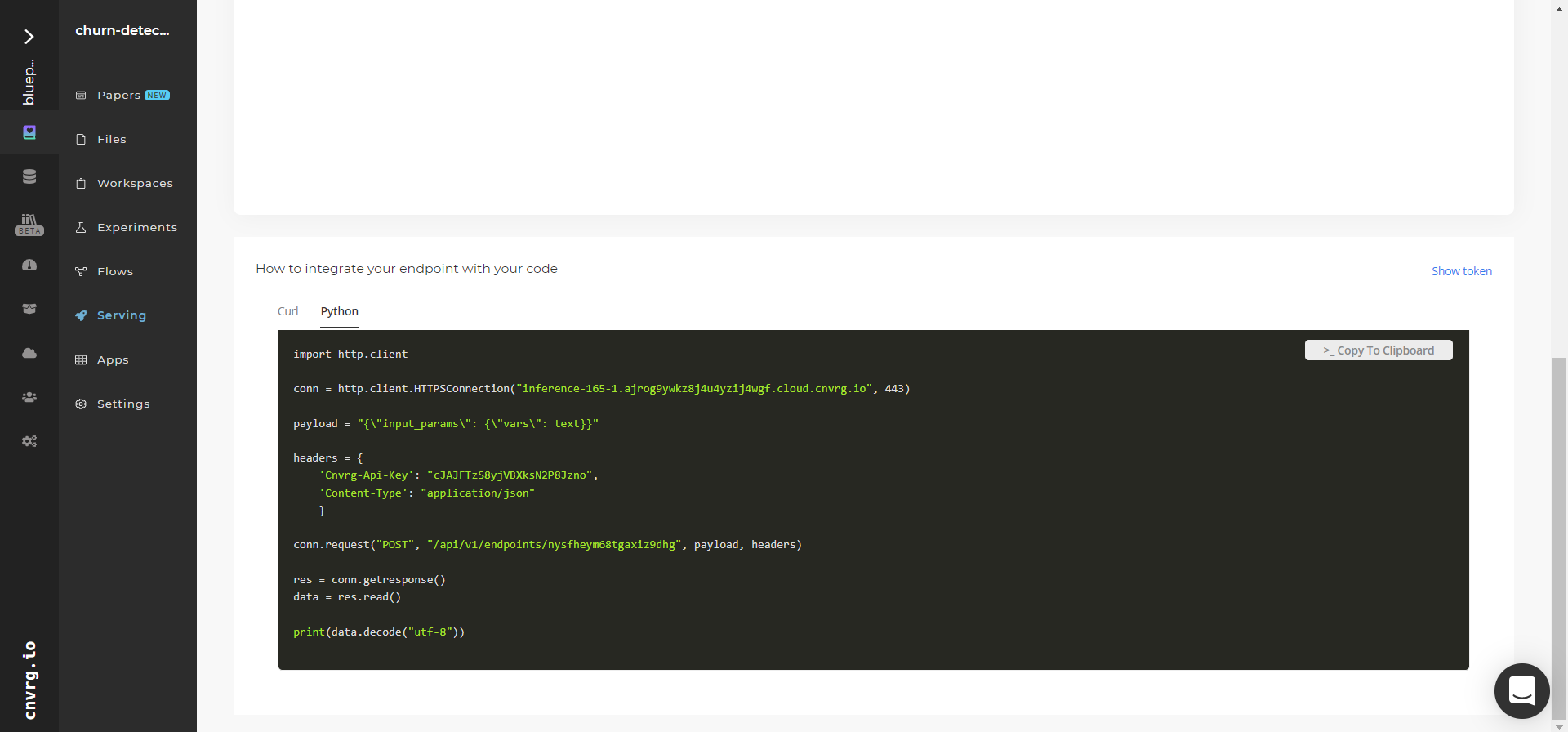
- Use the bottom integration panel to integrate your API with your code by copying in your code snippet.
- Use the Try it Live section with a relevant user ID to check the model’s prediction accuracy.
An API endpoint that detects about-to-churn customers among a larger customer pool has now been deployed. For information on this blueprint's software version and release details, click here.
# Related Blueprints
Refer to the following blueprints related to this inference blueprint:
- Churn Detection Train
- Churn Detection Batch
- Sentiment Analysis Train
- Sentiment Analysis Inference
- Virtual Agent Train
- Virtual Agent Inference
# Training
Churn detection applies metrics to identify customers or clients who may be thinking of leaving one company for another. Essentially attrition, churn is the percentage of consumers who stopped using a provider’s products or services during a certain time period. Reducing churn rates is an important business goal and applying metrics to detect potential churners is an effective way to achieve these churn reductions.
# Overview
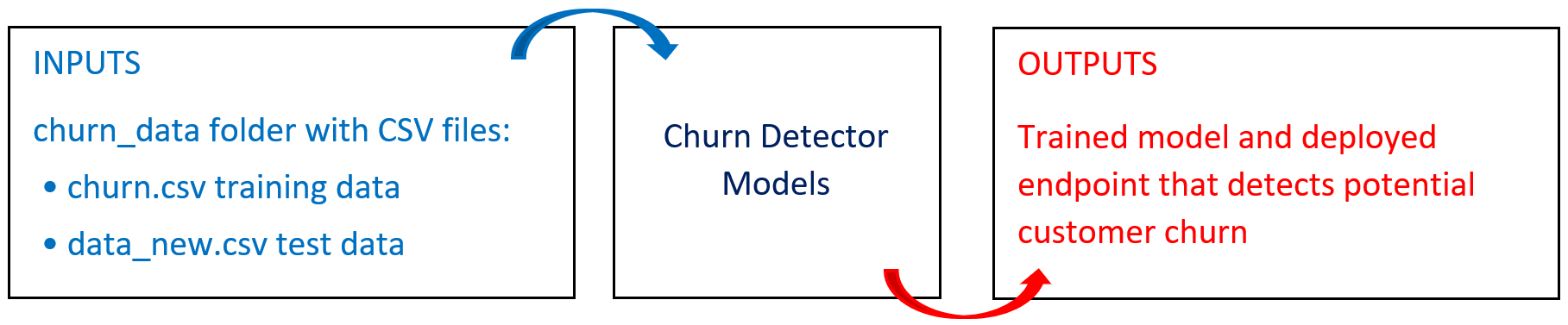
The following diagram provides an overview of this blueprint's inputs and outputs.
# Purpose
Use this training blueprint to clean and validate customized data, train multiple models using a preprocessed dataset, and deploy a new API endpoint that predicts whether a customer or client is likely to churn.
To clean the data, the following is required:
--churn_data− user-uploaded raw data to the platform--id_column− user-provided ID column name--label_encoding_cols− user label-encoded list of columns--scaler− user-selected type of scaler--do_scaling− user-enabled scaling (or not)
To train this model with your data, the following is required:
- S3 folder − one folder in the S3 Connector to store the data
churn_data− the folder containing thechurn.csvtraining data to train the model and thedata_new.csvtest data file to make predictions
# Deep Dive
The following flow diagram illustrates this blueprint's pipeline:
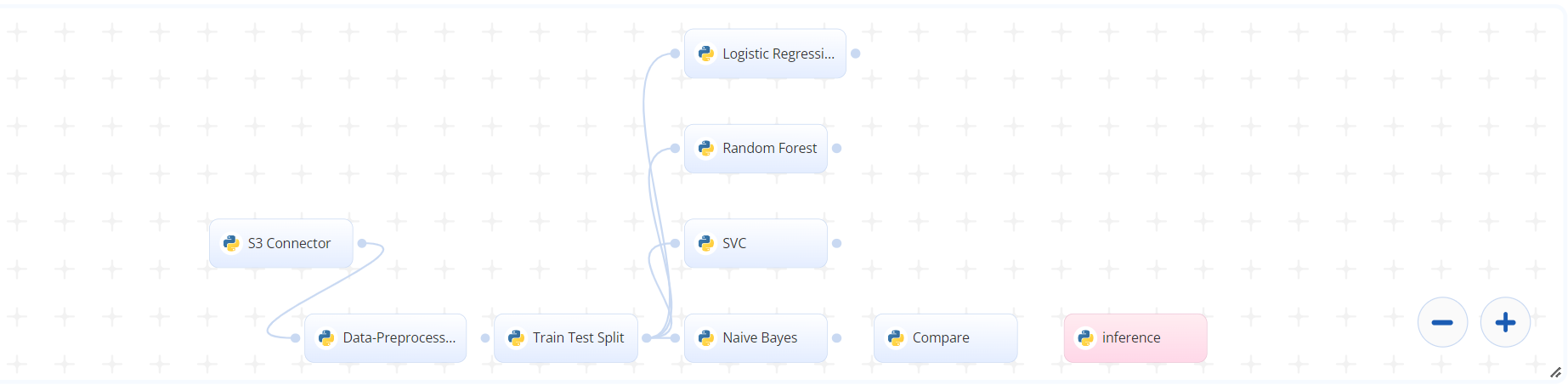
# Flow
The following list provides a high-level flow of this blueprint’s run:
- In the S3 Connector, provide the data bucket name and directory path to the churn data CSV file
- In the Data Preprocessing task, provide the path to the CSV file including the S3 prefix
- In the Train Test Split task, provide the path to the CSV file in the Data Preprocessing task
- In the Compare task, set the metric conditions information, with possible settings being
accuracy_score,--f1_score,--recall_score, and--precision
# Arguments/Artifacts
For more information and examples of this blueprint's tasks, its inputs and outputs, click here.
# Data Preprocessing
# Inputs
--churn_data(/input/s3_connector/churn_data/churn.csv) – the uploaded raw data to the platform--id_column(customerID) – the name of the customer ID--label_encoding_cols(PaymentMethod,InternetService) – the label-encoded list of columns--scaler(MinMax) − the type of scaler to be used--do_scaling− whether to perform scaling
# Outputs
--recommendation file− the file containing recommendations algorithm usage--original_col.csv− the original file column names and average/random values as a single row--data_df.csv− a processed file (after one hot encoding, label encoding, missing value treatment)--processed_col.csv− a processed file (after one hot encoding, label encoding, missing value treatment) but with only one row (for displaying average values/data types of all columns, used in batch predict)--ordinal_enc− the label/ordinal encoder-saved file after fitting the encoder on training data--one_hot_encoder− one hot encoder-saved file after fitting the encoder on training data--columns_list.csv− a three-column table: first hot encoded, second label encoded, and third IDs--mis_col_type.csv− columns categorized based on kind of missing value treatment they received, mean, median, or random value--std_scaler.bin− a standard scaler-saved object after fitting scaler on training data
# Train/Test/Split
# Inputs
--preprocessed_data− preprocessed and cleaned data from the data preprocessing block
# Outputs
--X_train.csv− a train dataset of independent variables--X_test.csv− a test dataset of independent variables--y_train.csv− a train dataset of dependent variables--y_test.csv− a test dataset of dependent variables
# Compare
The Compare task is used to compare multiple algorithms on an accuracy score basis to select the best model, which can be changed based on user requirements by selecting the following supported metrics.
# Metrics
accuracy_score− the accuracy, either the fraction (default) or the count (normalize=false) of correct predictions. Accuracy represents the number of correctly classified data instances compared to the total data instances.precision− the model’s performance based on the percentage of pertinent results. Ideally, precision should be 1 for it to be considered high and a good classifier.recall_score− the model’s performance based on the percentage of correct classifications of relevant results. Also known as sensitivity, recall should also be 1 for it to be considered high and an ideal classifier.f1_score− a statistical measure to rate a model's performance. Defined as the harmonic mean of precision and recall, the F1 score is considered a better measure than accuracy. The F1 score becomes 1 only when precision and recall are both 1.
# Outputs
--eval_1− recommendation evaluation metrics--churn_output.csv− churn predictions from the best model
# Instructions
NOTE
The minimum resource recommendations to run this blueprint are 3.5 CPU and 8 GB RAM.
Complete the following steps to train the churn-detector model:
Click the Use Blueprint button. The cnvrg Blueprint Flow page displays.
In the flow, click the S3 Connector task to display its dialog.
- Within the Parameters tab, provide the following Key-Value pair information:
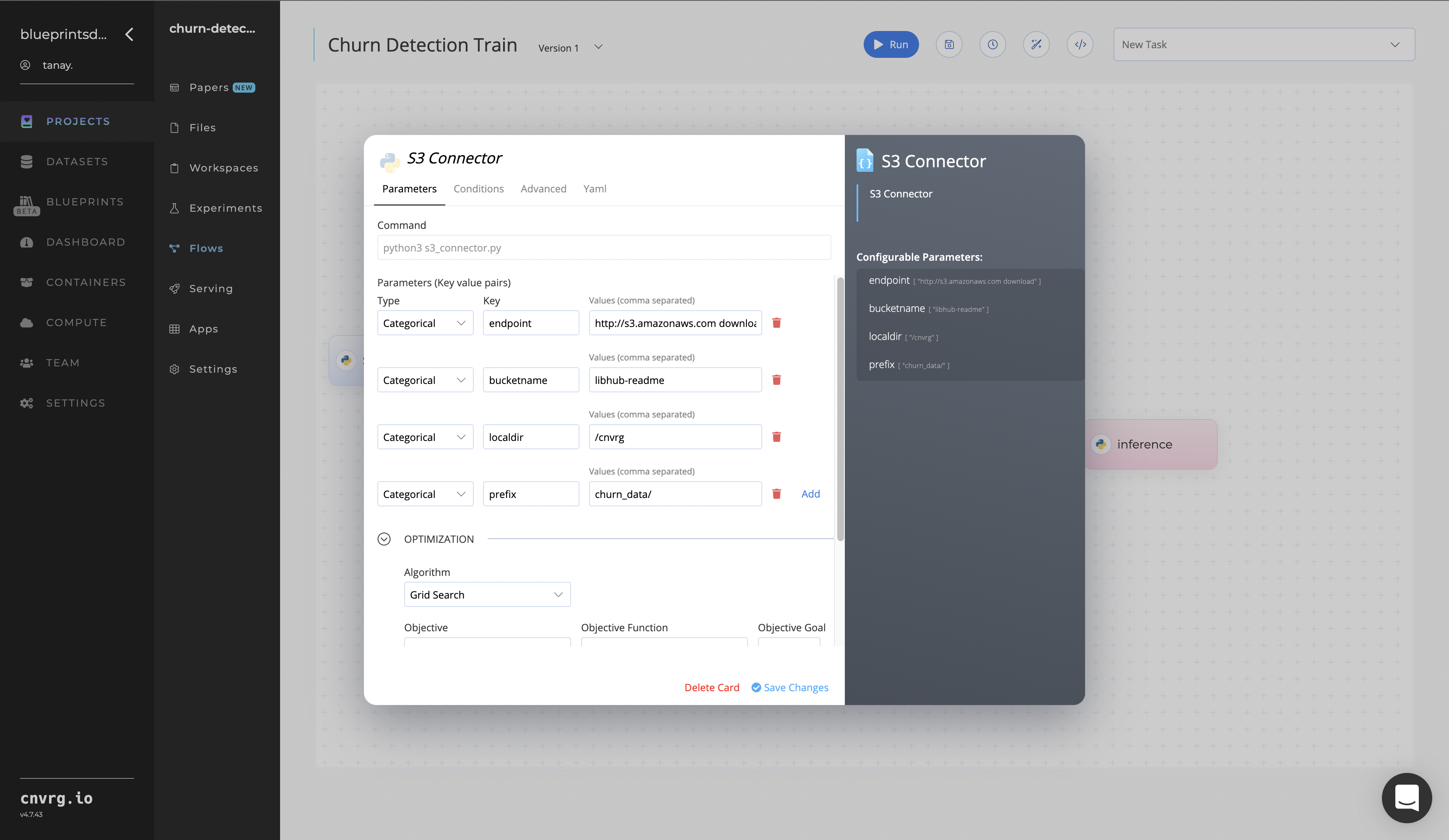
- Key:
bucketname- Value: enter the data bucket name - Key:
prefix- Value: provide the main path to the CSV file folder
- Key:
- Click the Advanced tab to change resources to run the blueprint, as required.
- Within the Parameters tab, provide the following Key-Value pair information:
Return to the flow and click the Data Preprocessing task to display its dialog.
Within the Parameters tab, provide the following Key-Value pair information:
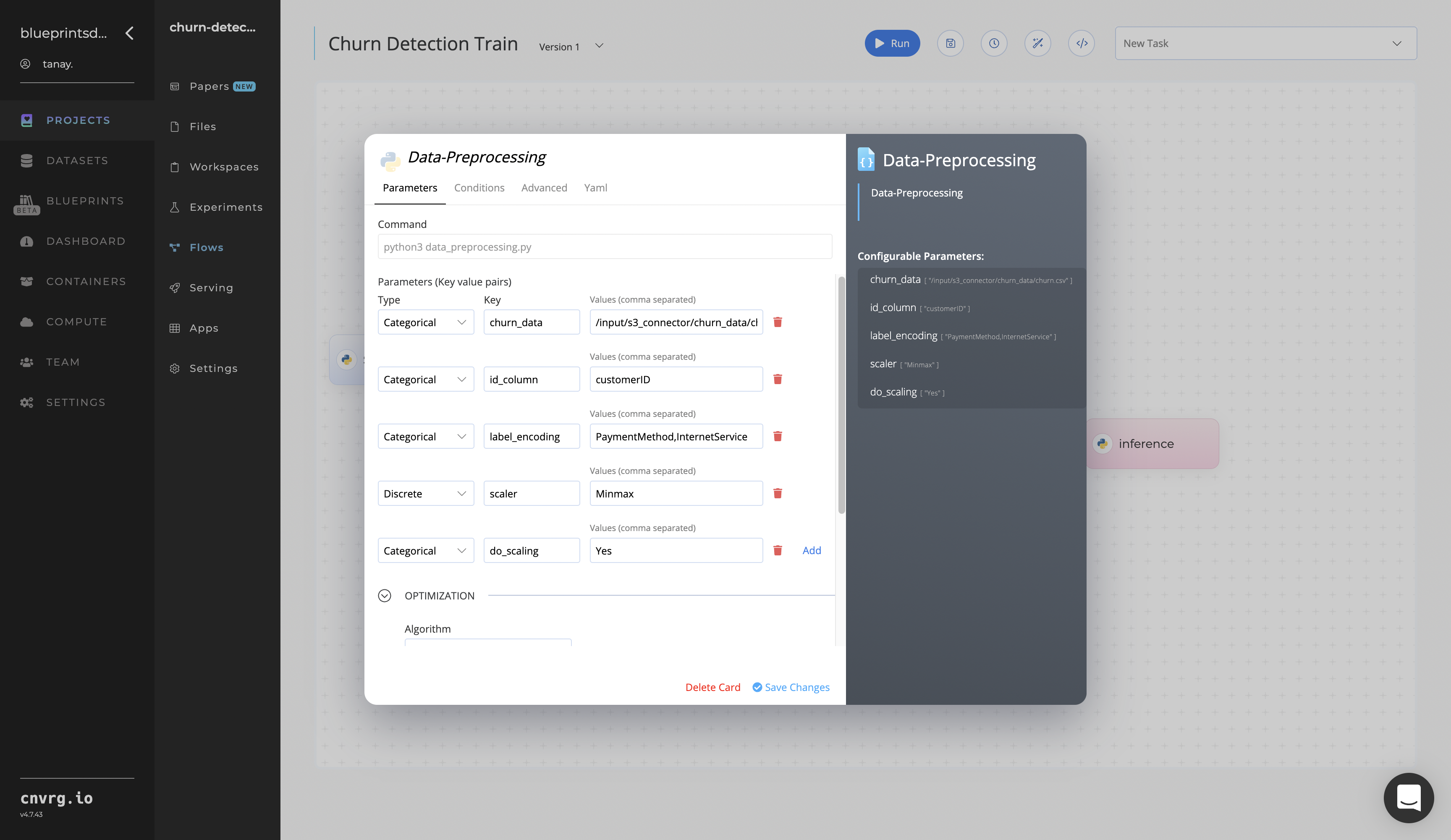
- Key:
churn_data– Value: provide the path to the CSV file including the S3 prefix /input/s3_connector/<prefix>/churn_data− ensure the CSV file path adheres this format
NOTE
You can use prebuilt data example paths already provided.
- Key:
Click the Advanced tab to change the resources to run the blueprint, as required.
Click the Train Test Split task to display its dialog.
Within the Parameters tab, provide the following Key-Value pair information:
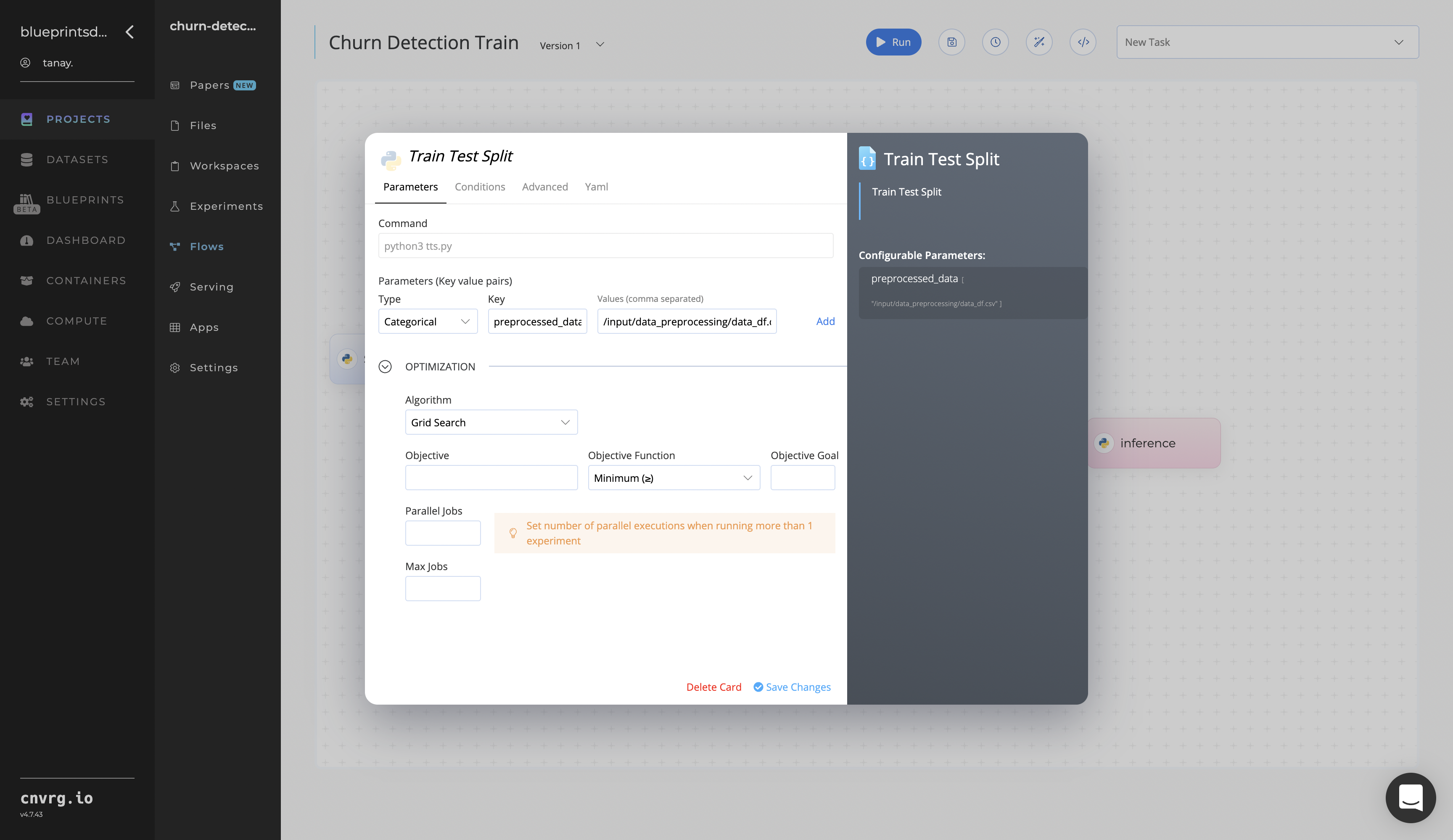
- Key:
--preprocessed_data– Value: provide the path to the CSV file from the Data Preprocessing task /input/data_preprocessing/data_df.csv− ensure the data path adheres this format
NOTE
You can use prebuilt data example paths already provided.
- Key:
Click the Advanced tab to change resources to run the blueprint, as required.
Click the Compare task to display its dialog.
- Click the Conditions tab to set the following metric conditions information:
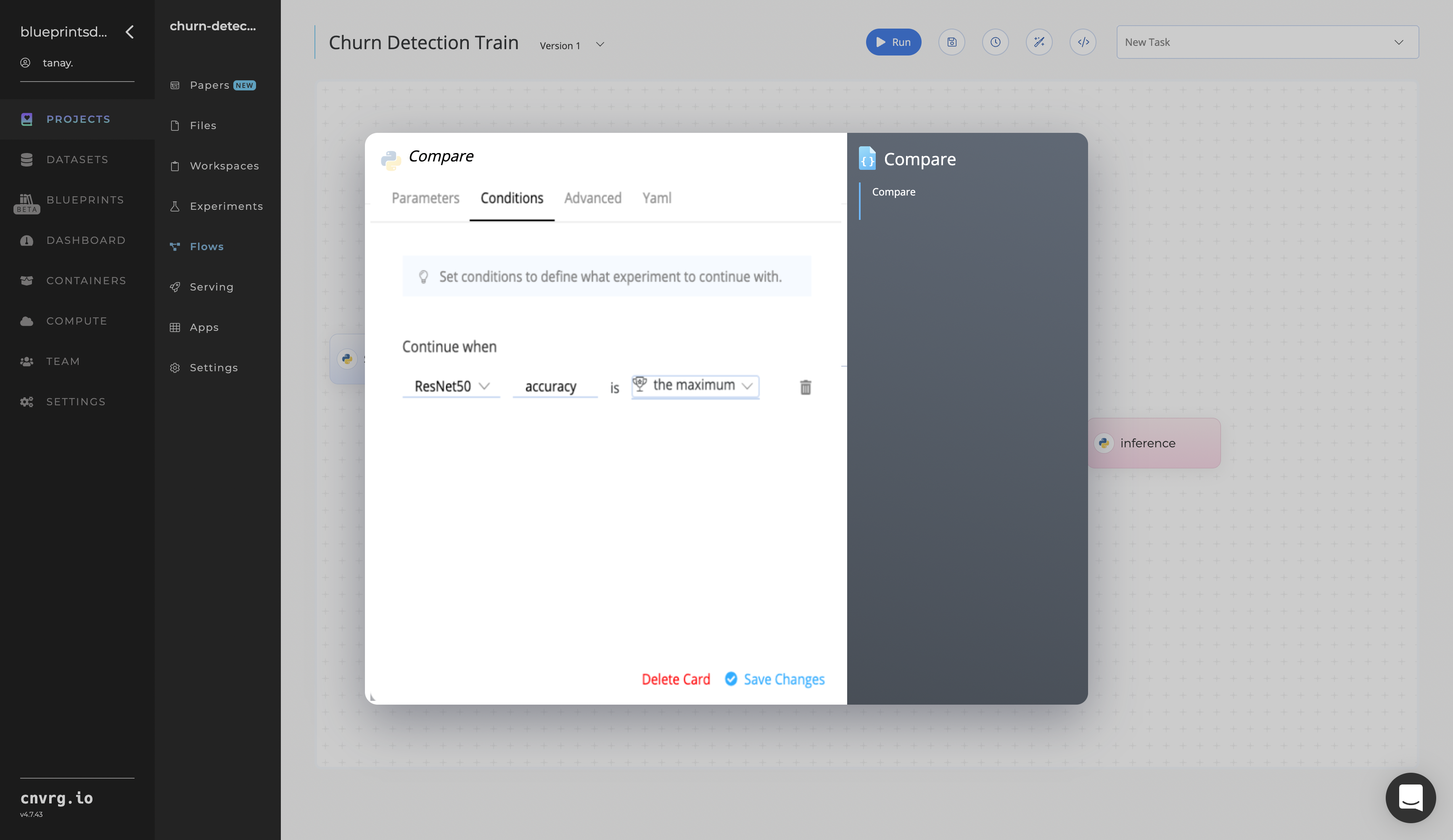
--accuracy_score− see Compare Metrics--f1_score− see Compare Metrics--recall_score− see Compare Metrics--precision− see Compare Metrics
- Click the Advanced tab to change resources to run the blueprint, as required.
- Click the Conditions tab to set the following metric conditions information:
Click the Run button.
 The cnvrg software launches the training blueprint as set of experiments, generating a trained churn-detector model and deploying it as a new API endpoint.
The cnvrg software launches the training blueprint as set of experiments, generating a trained churn-detector model and deploying it as a new API endpoint.NOTE
The time required for model training and endpoint deployment depends on the size of the training data, the compute resources, and the training parameters.
For more information on cnvrg endpoint deployment capability, see cnvrg Serving.
Track the blueprint's real-time progress in its Experiments page, which displays artifacts such as logs, metrics, hyperparameters, and algorithms.
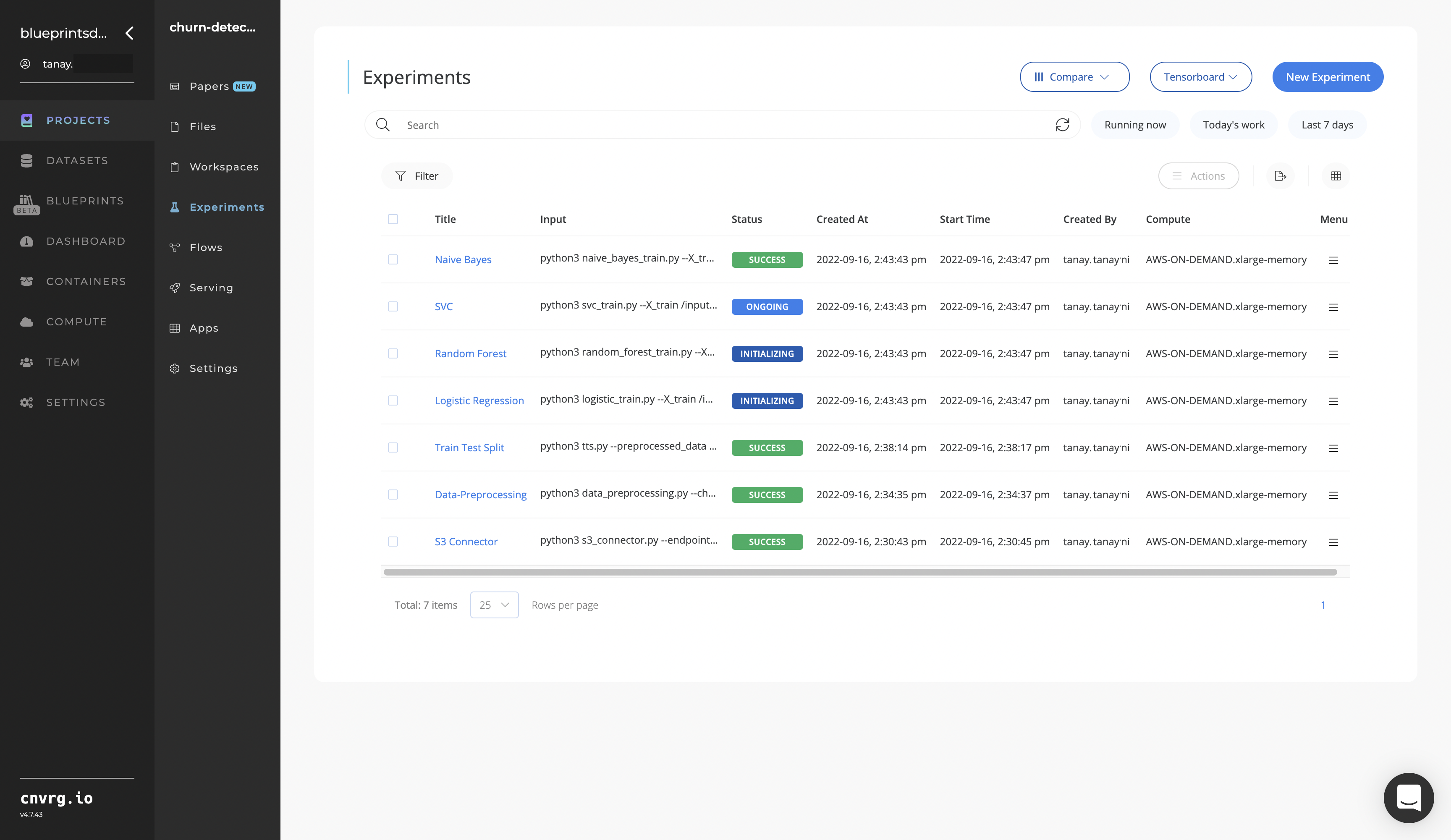
Click the Serving tab in the project and locate your endpoint.
Complete one or both of the following options:
- Use the Try it Live section with a relevant user ID to check the model’s prediction accuracy.
- Use the bottom integration panel to integrate your API with your code by copying in your code snippet.
- Use the Try it Live section with a relevant user ID to check the model’s prediction accuracy.
A custom model and an API endpoint, which can detect about-to-churn customers from among a larger customer pool, have been trained and deployed. For information on this blueprint's software version and release details, click here.
# Connected Libraries
Refer to the following libraries connected to this blueprint:
# Related Blueprints
Refer to the following blueprints related to this training blueprint: