# Document Classification AI Blueprint - deprecated from 11/2024
# Batch-Predict
Document classification involves the process of classifying the content of documents to facilitate their filtering, management, organization, and searchability.
# Purpose
Use this batch blueprint to classify text from document files in .pdf, .txt, .docx, and .doc formats. The blueprint skips other documents formats.
The blueprint’s input files are placed in a directory and its output is stored in CSV format. Provide the path containing folders with the specified-formatted document files. Also, provide as CSV the tags or labels to associate with these files. The blueprint outputs a result.csv in including each tag’s probability for each file.
# Deep Dive
The following flow diagram illustrates this batch-predict blueprint’s pipeline:
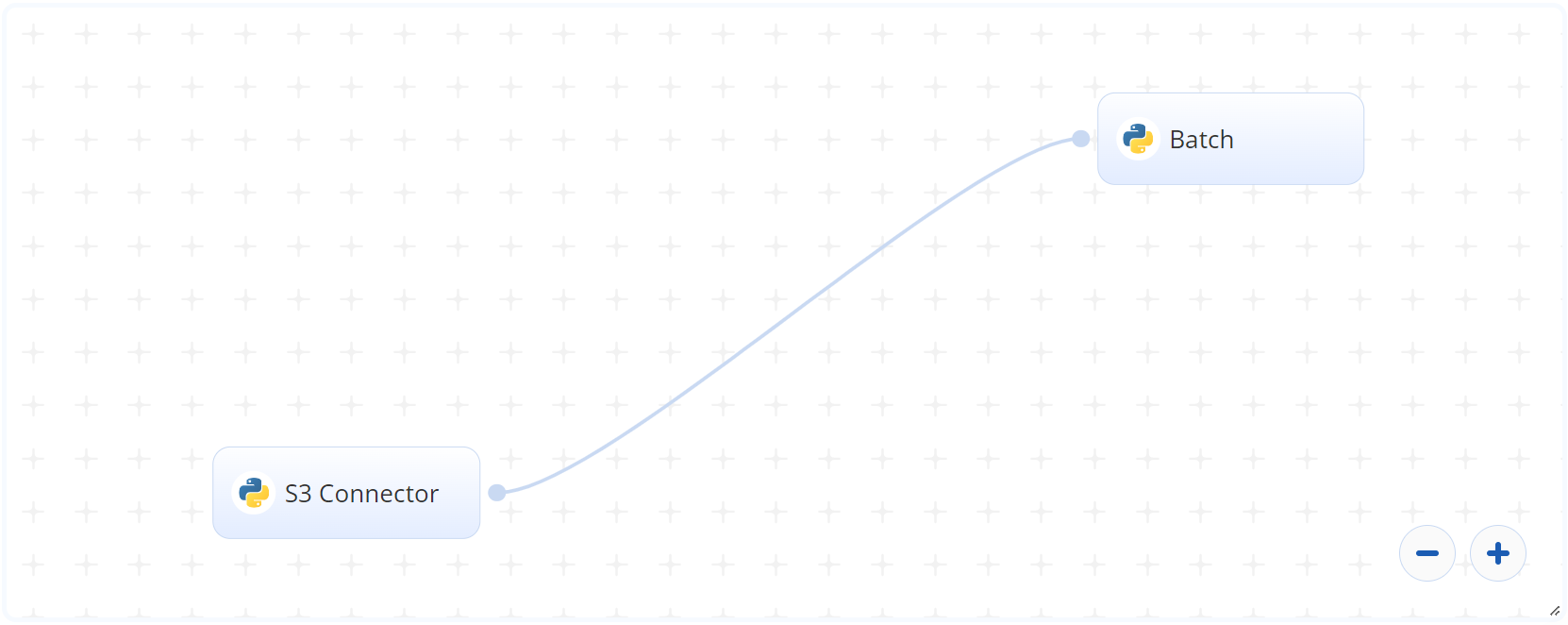
# Flow
The following list provides a high-level flow of this blueprint’s run:
- In the S3 Connector, the user provides the data bucket name and the directory path where the files are located.
- In the Batch task, the user provides the
dirpath to the S3 Connector’s document files folders. - The blueprint outputs a
result.csvCSV file with document classifications.
# Arguments/Artifacts
For more information and examples on this blueprint’s inputs and outputs, click here.
# Inputs
--diris the path to the folder containing all folders storing the target files--labelsare the target labels whose values are provided in quotes without spaces; for example: "value1,value2". NOTE: Provide the following two inputs to use your own trained model and eliminate this--labelsinput.--trained_modelis the path tomodel.ptfile trained with this blueprint’s training counterpart. To access, download the file from the output artifacts of the Train task of the Document Classification Train Blueprint.--trained_classesID is the path toclasses.jsonfile, required if using your own trained model. Download this file from the output artifacts of the Train task of the Document Classification Train Blueprint.
# Output
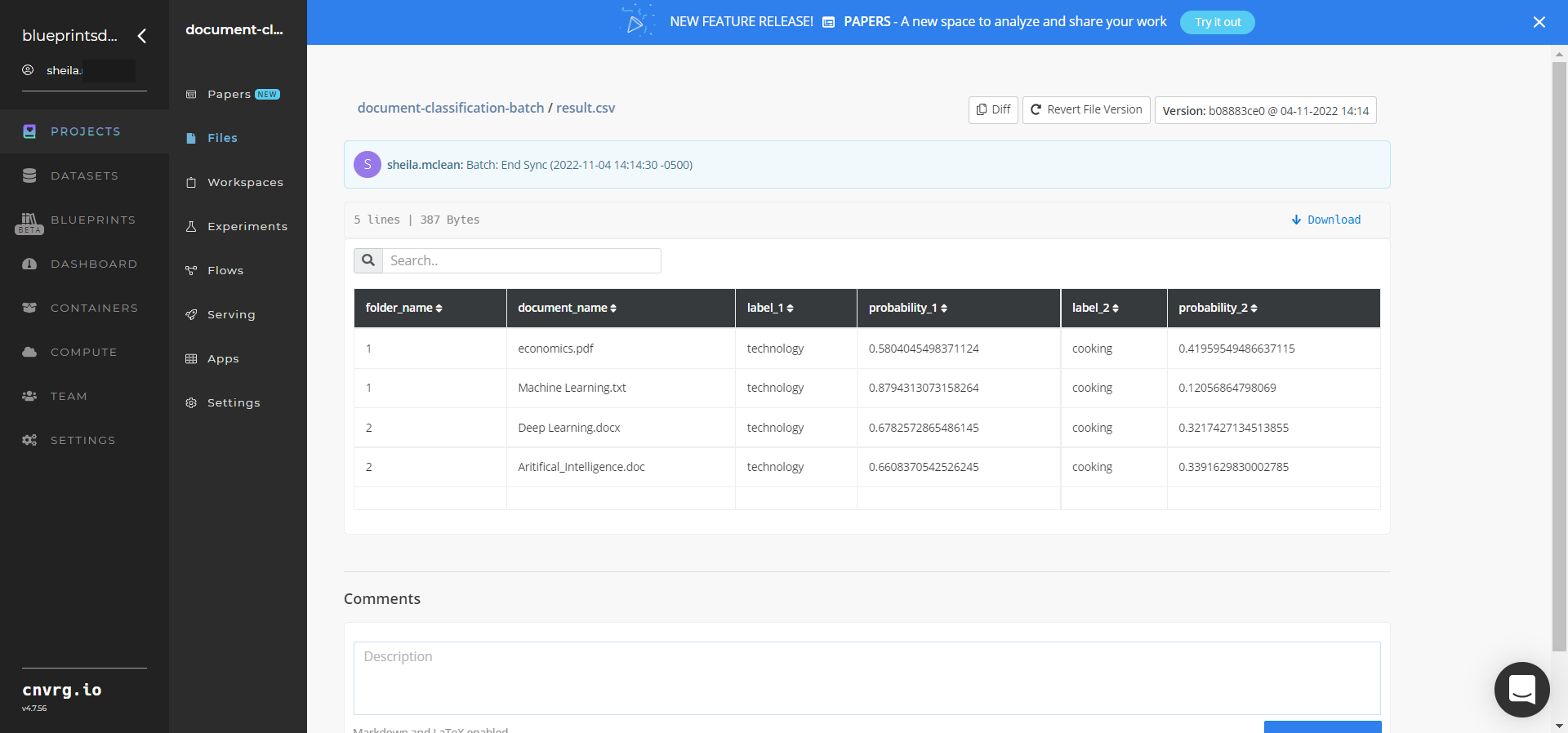
result.csvis the blueprint’s output that includes the document file names, their labels, and each label’s probability for each file.
# Instructions
NOTE
The minimum resource recommendations to run this blueprint are 3.5 CPU and 8 GB RAM.
NOTE
This blueprint’s performance can benefit from using GPU as its compute.
Complete the following steps to run the document-classifier model in batch mode:
- Click the Use Blueprint button. The cnvrg Blueprint Flow page displays.
- Click the S3 Connector task to display its dialog.
- Within the Parameters tab, provide the following Key-Value information:
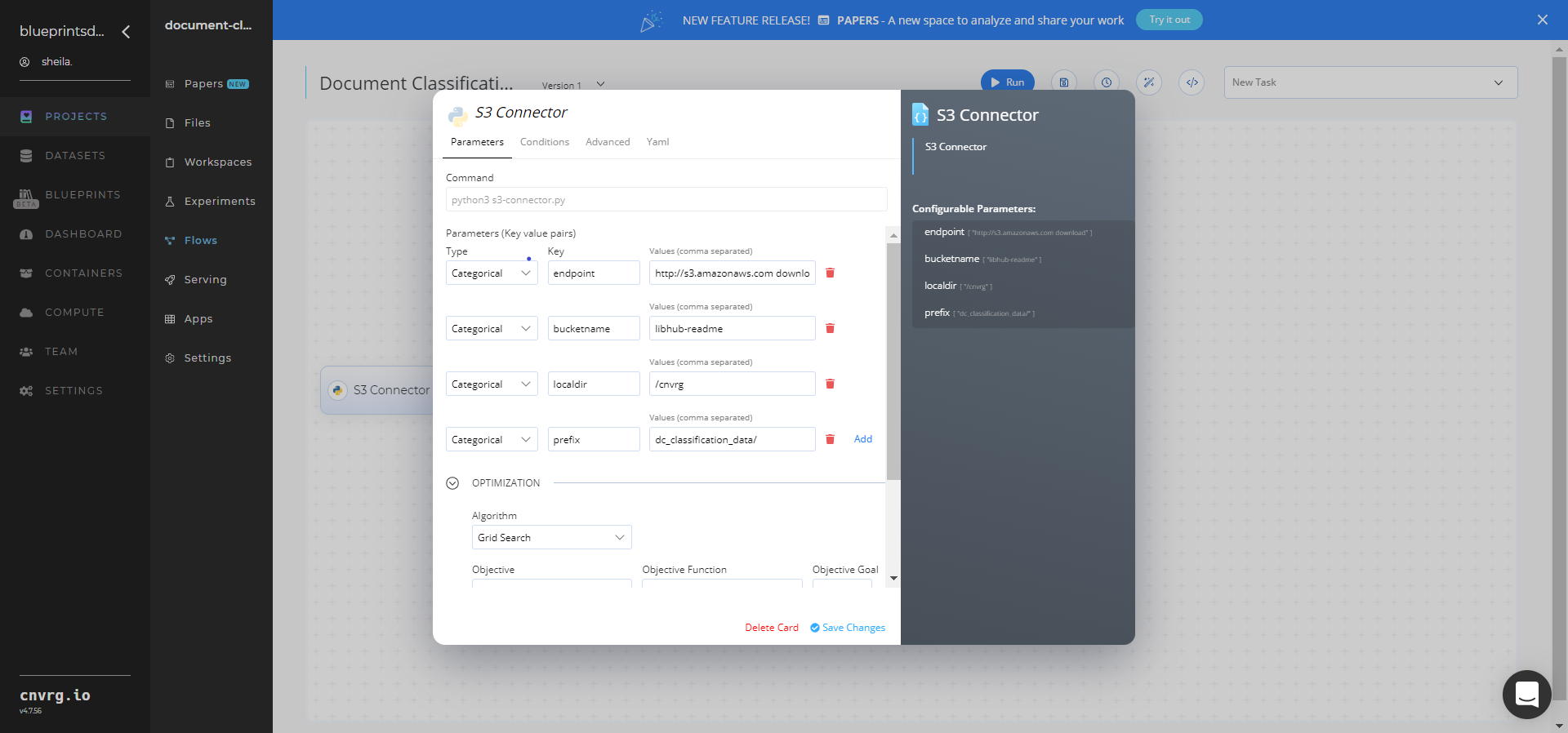
- Key:
bucketname− Value: provide the data bucket name - Key:
prefix− Value: provide the main path to the files folders
- Key:
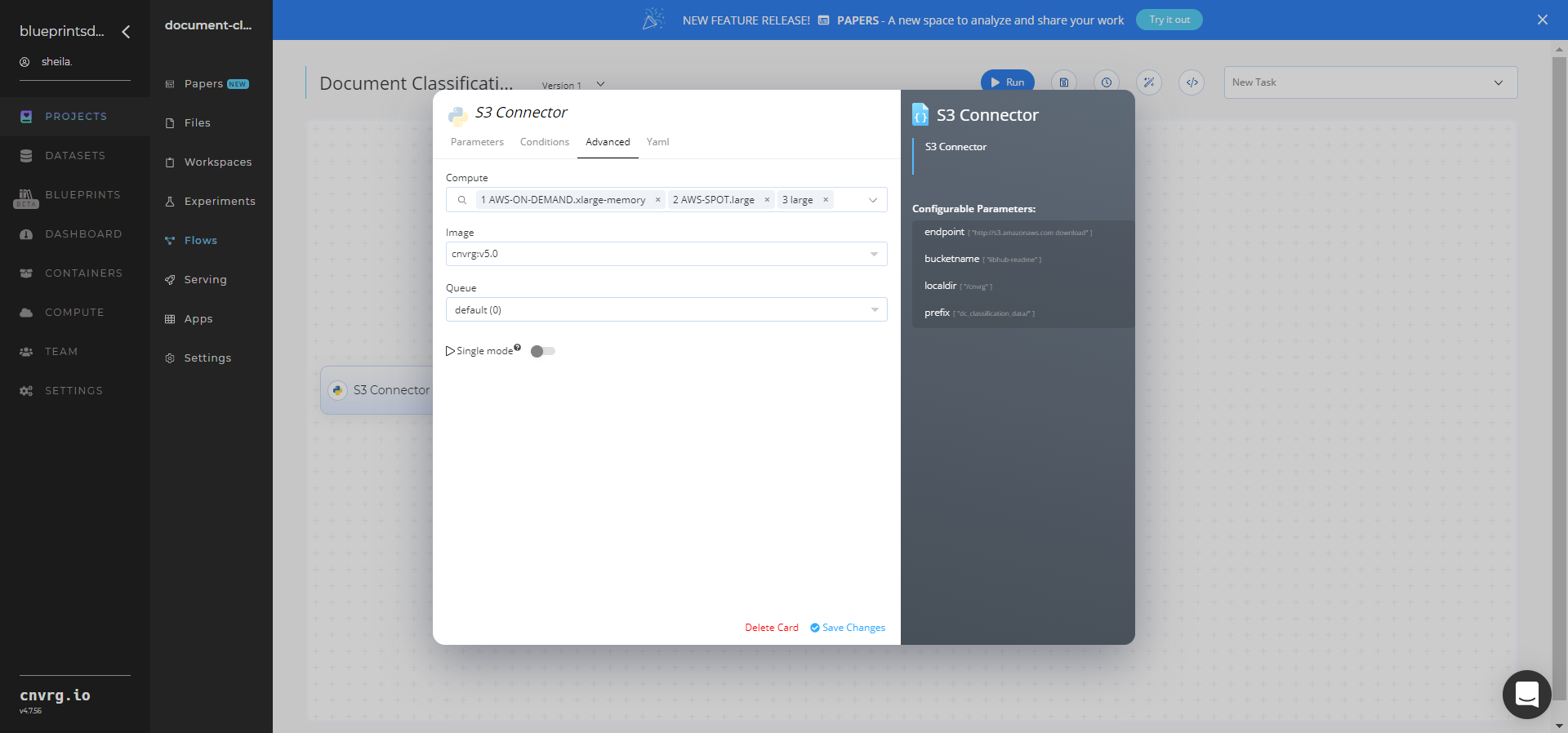
- Click the Advanced tab to change resources to run the blueprint, as required.
- Within the Parameters tab, provide the following Key-Value information:
- Click the Batch task to display its dialog.
Within the Parameters tab, provide the following Key-Value pair information:
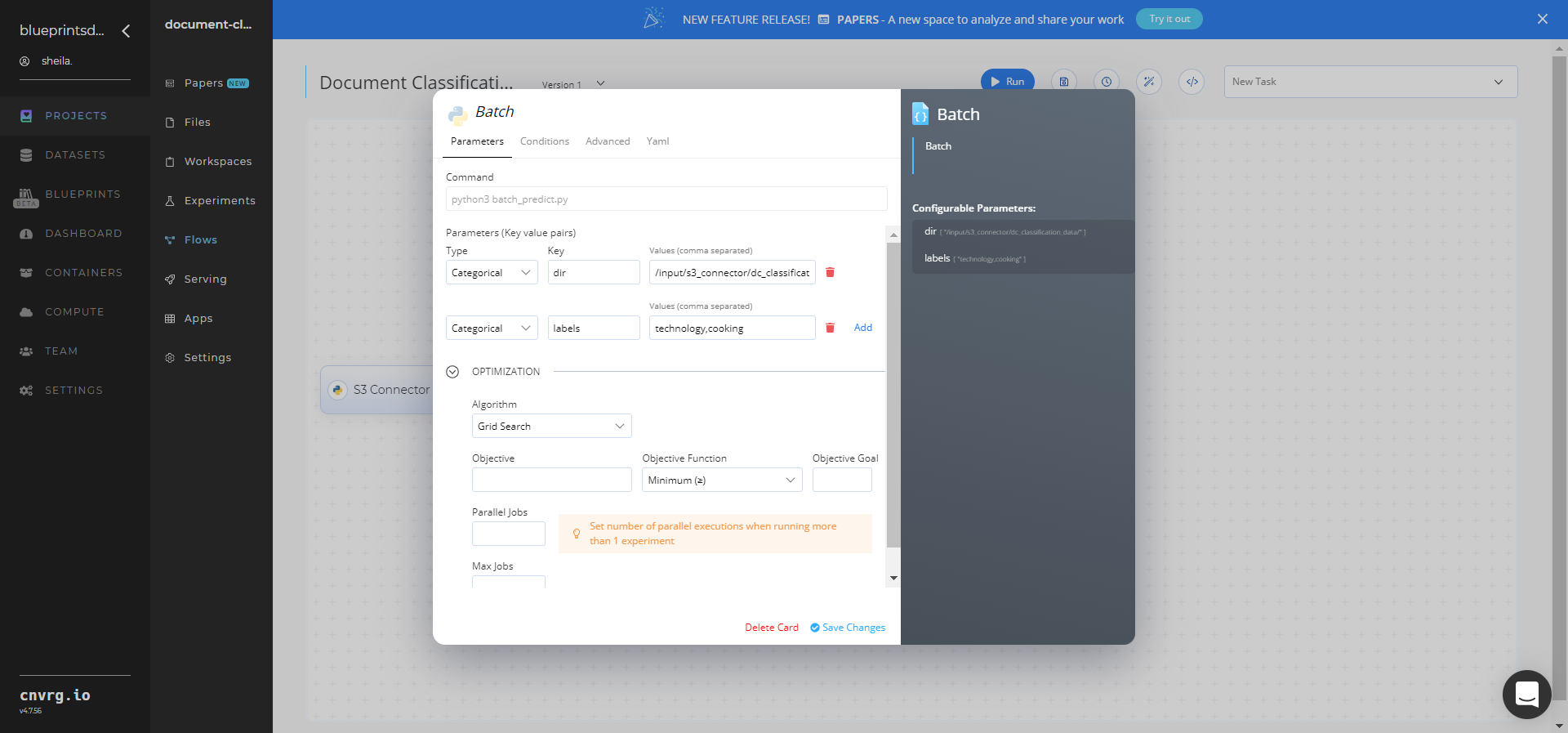
- Key:
--dir− Value: provide the S3 path to the folder containing the folders storing the target files in the following format:/input/s3_connector/dc_classification_data/; see Batch Inputs for more information. - Key:
--labels− Value: provide the target labels in quotes as CSVs without spaces; see Batch Inputs for more information.
NOTE
You can use the prebuilt data example paths provided.
- Key:
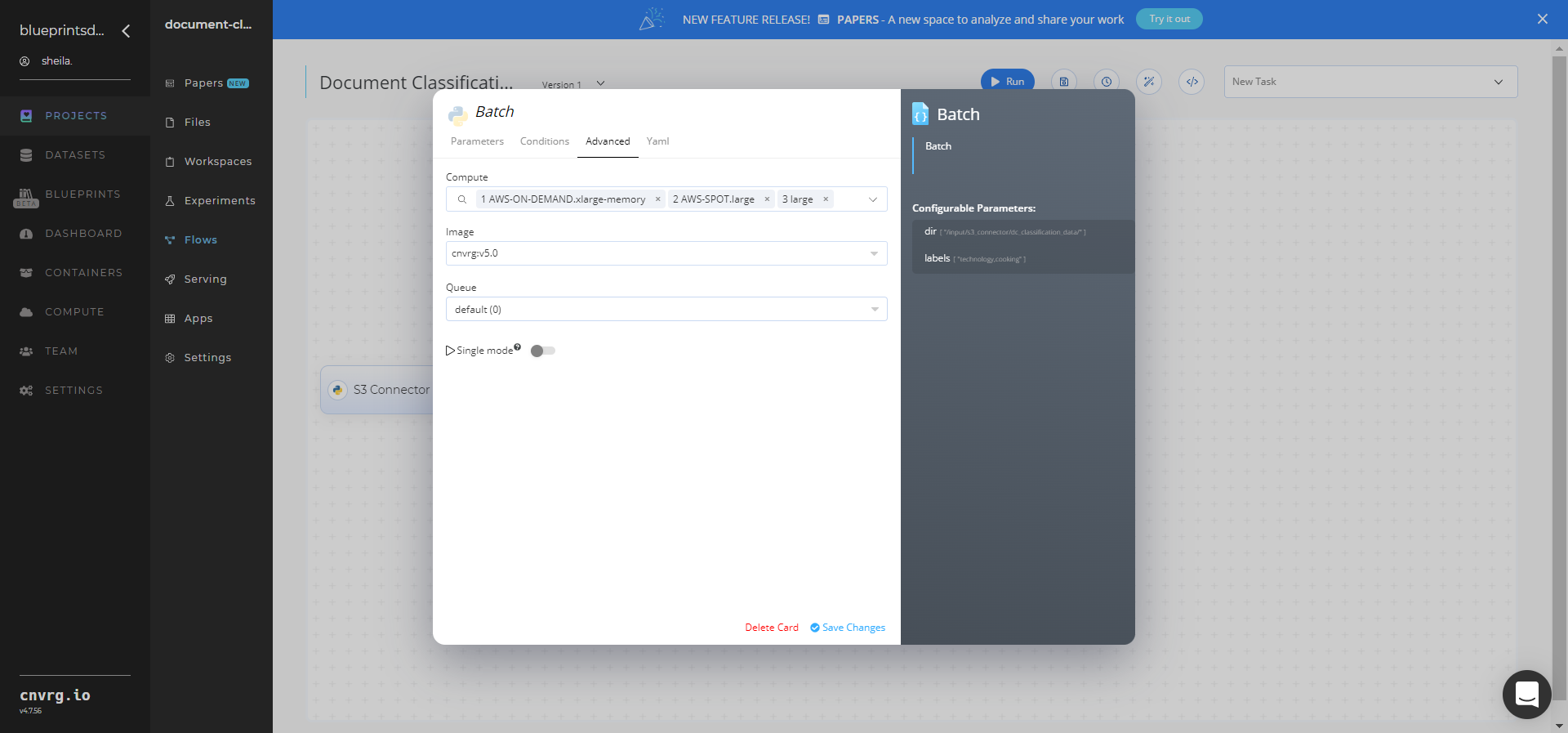
Click the Advanced tab to change resources to run the blueprint, as required.
- Click the Run button.
 The cnvrg software deploys a document-classifier model that classifies text in a batch of files and outputs a CSV file with the document classifications.
The cnvrg software deploys a document-classifier model that classifies text in a batch of files and outputs a CSV file with the document classifications. - Select Batch > Experiments > Artifacts and locate the batch output CSV file.
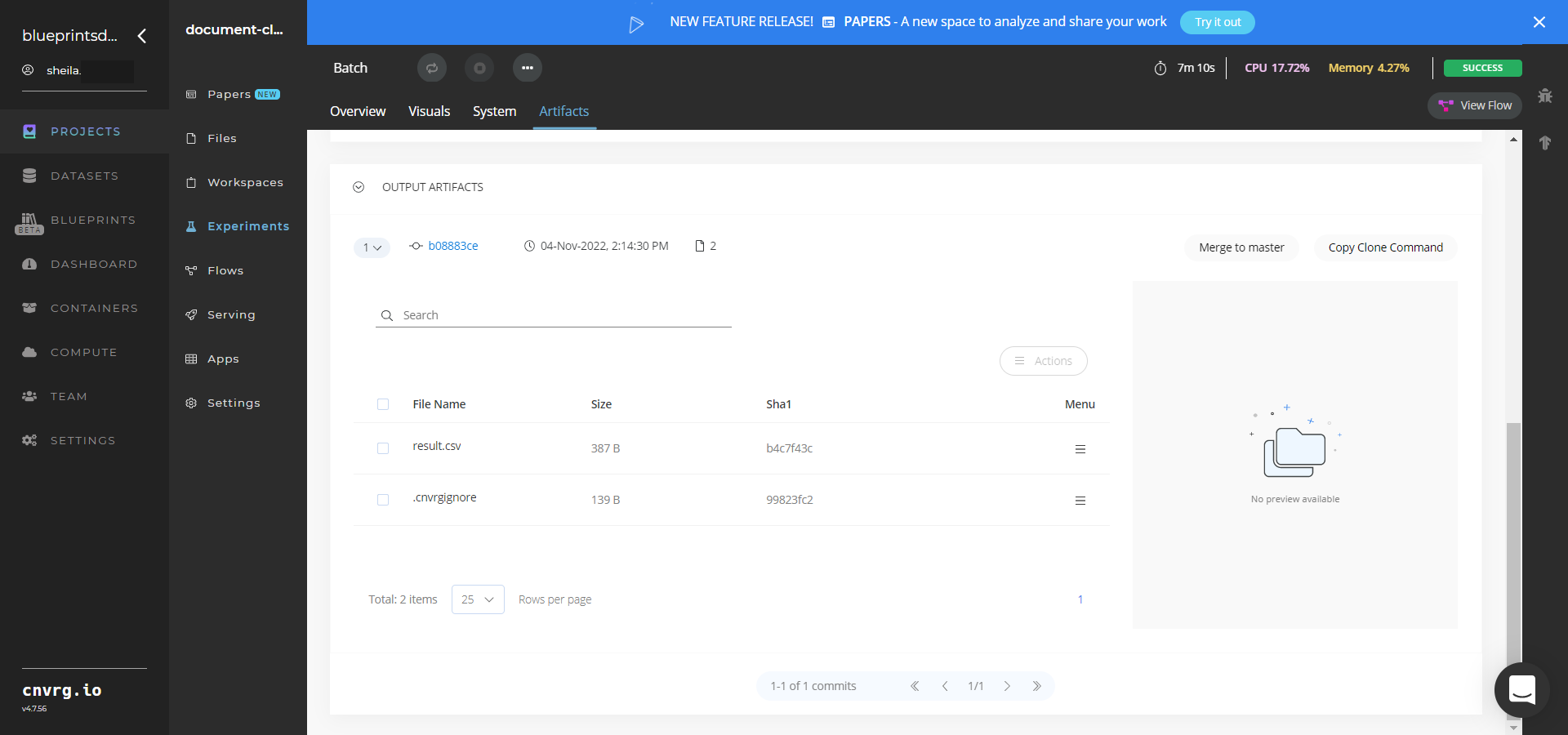
- Select the result.csv File Name, click the Menu icon, and select Open File to view the output CSV file.
A custom model that classifies text in different formatted document files has been deployed in batch mode. For information on this blueprint’s software version and release details, click here.
# Connected Libraries
Refer to the following libraries connected to this blueprint:
# Related Blueprints
Refer to the following blueprints related to this batch blueprint:
# Inference
Document classification involves the process of classifying the content of documents to facilitate their filtering, management, organization, and searchability.
# Purpose
Use this inference blueprint to deploy a document-classifier model and its API endpoint. To use this pretrained document-classifier model, create a ready-to-use API-endpoint that is quickly integrated with your input data in the form of raw text along with custom label names, returning for each label an associated probability value.
This inference blueprint’s model was trained using Hugging Face multi_nli datasets. To use custom document data according to your specific business, run this counterpart’s training blueprint, which trains the model and establishes an endpoint based on the newly trained model.
# Instructions
NOTE
The minimum resource recommendations to run this blueprint are 3.5 CPU and 8 GB RAM.
NOTE
This blueprint’s performance can benefit from using GPU as its compute.
Complete the following steps to deploy this document-classifier endpoint:
- Click the Use Blueprint button.
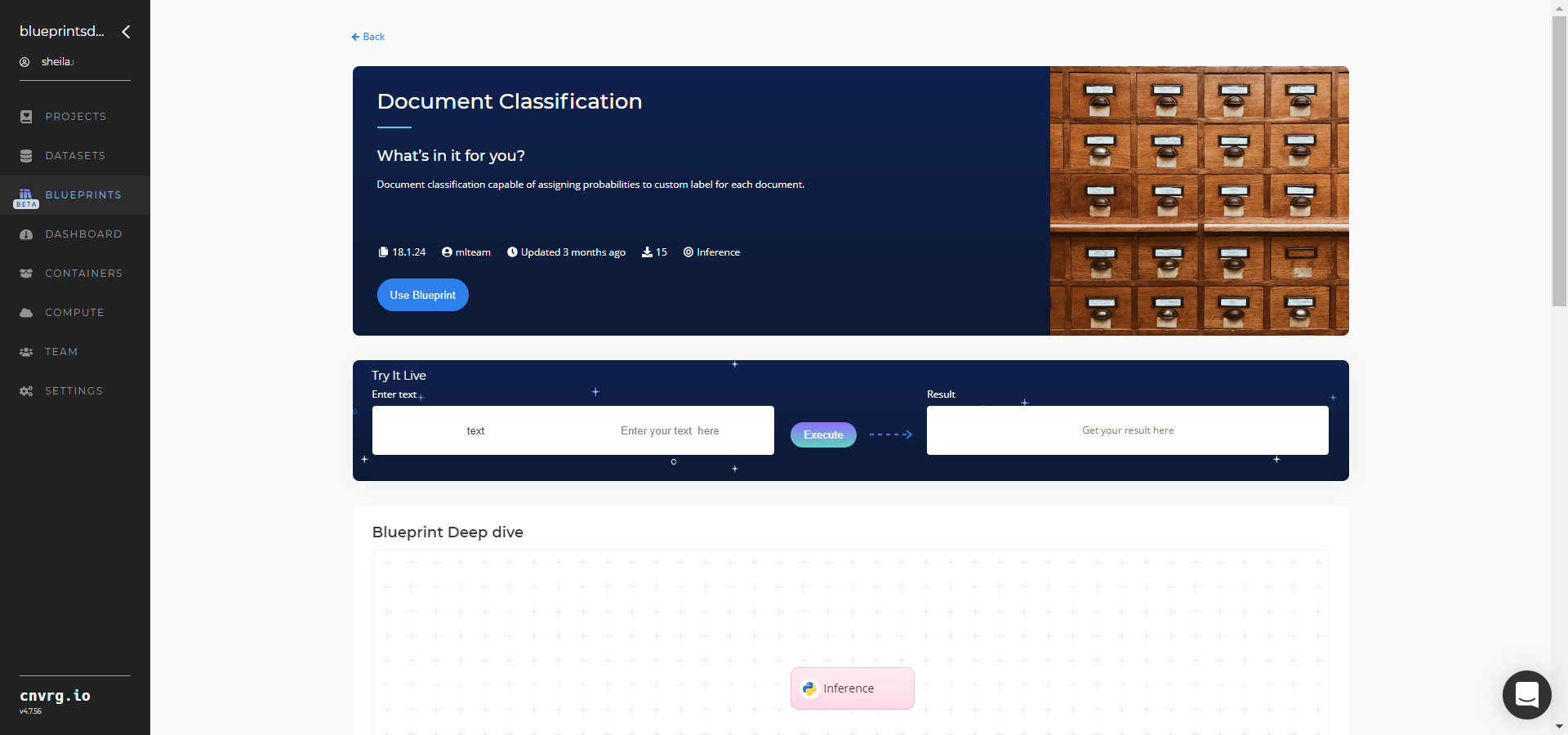
- In the dialog, select the relevant compute to deploy the API endpoint and click the Start button.
- The cnvrg software redirects to your endpoint. Complete one or both of the following options:
- Use the Try it Live section with any document file or link to be classified.
- Use the bottom integration panel to integrate your API with your code by copying in the code snippet.
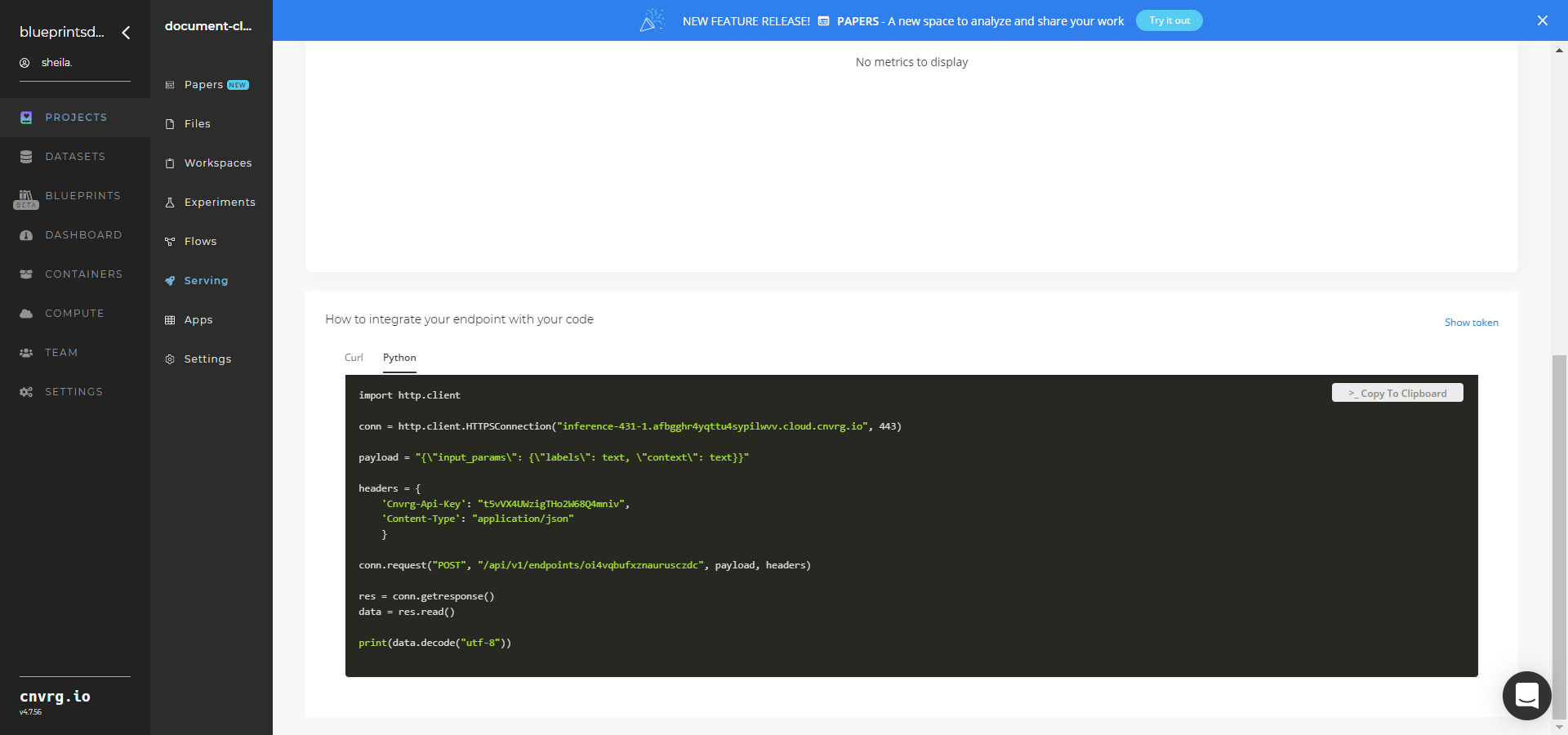
- Use the Try it Live section with any document file or link to be classified.
An API endpoint that classifies documents has now been deployed. For more information on this blueprint’s software version and release details, click here.
# Related Blueprints
Refer to the following blueprints related to this inference blueprint:
# Training
Document classification involves the process of classifying the content of documents to facilitate their filtering, management, organization, and searchability.
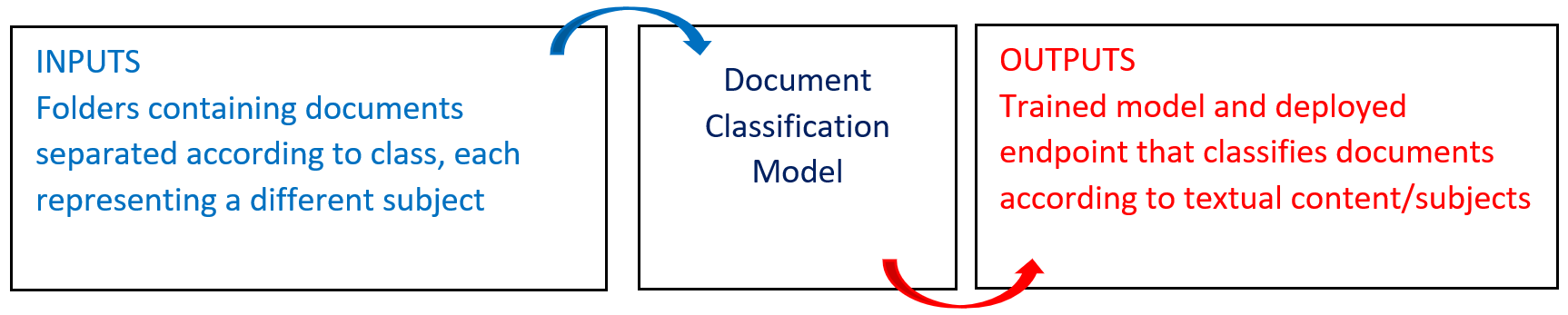
# Overview
The following diagram provides an overview of this blueprint's inputs and outputs.
# Purpose
Use this training blueprint to train a custom model on textual content within a set of documents. This blueprint also establishes an endpoint that can be used to classify documents based on the newly trained model.
To train this model with your data, provide in S3 a documents_dir dataset directory with multiple subdirectories containing the different classes of documents. The blueprint supports document files in .pdf, .txt, .docx, and .doc formats. Other documents formats are skipped.
# Deep Dive
The following flow diagram illustrates this blueprint's pipeline:
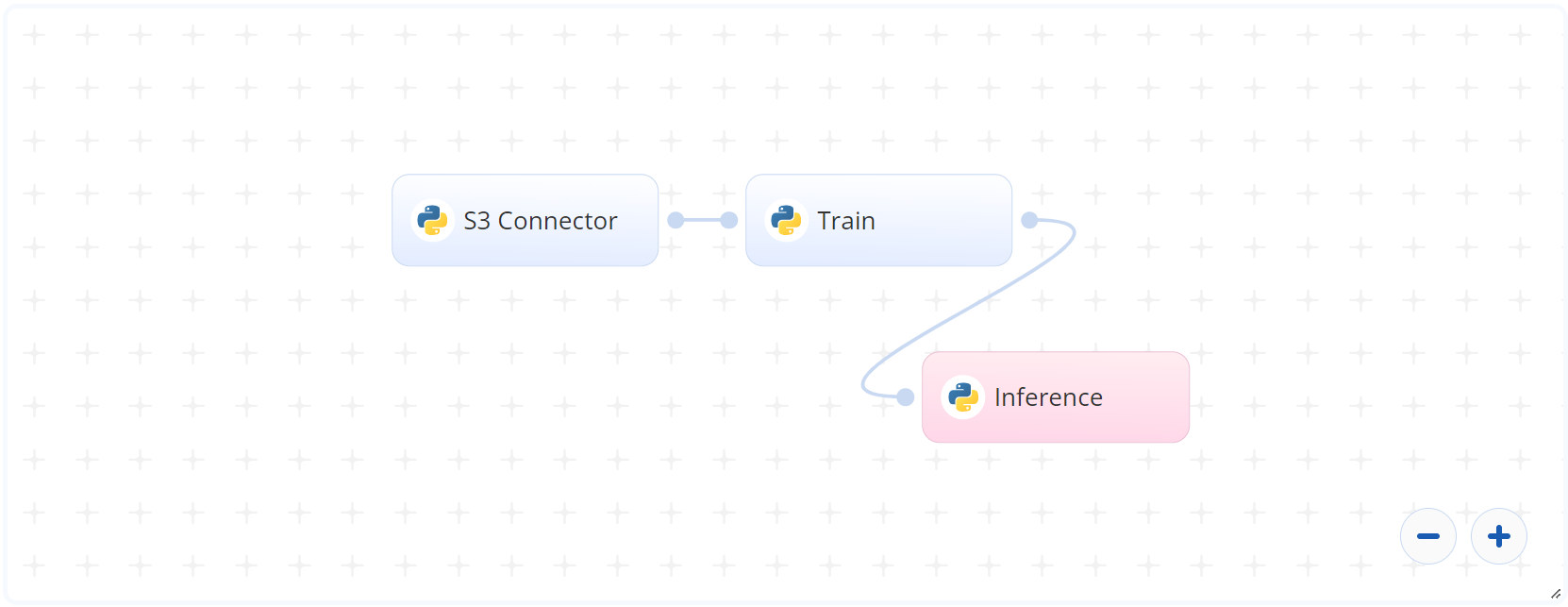
# Flow
The following list provides a high-level flow of this blueprint’s run:
- In the S3 Connector, the user provides the data bucket name and the directory path containing the training documents, divided into class subfolders inside the main folder. Also provided is a single CSV file containing document names and their mappings to their respective classes.
- In the Train task, the user provides the
documents_dirpath to the documents directory including the previous S3 prefix. - The blueprint trains the model on the given dataset and produces a model output file.
- The user uses the deployed endpoint to classify personalized business documents.
# Arguments/Artifacts
For information and examples of this task’s inputs and outputs, click here.
# Train Inputs
--documents_diris path to the main folder containing the training document to be used for training, which is divided into class subfolders inside this main folder.--labels pathis the path to the CSV file containing mapping of document names to their classes. This two-column CSV file contains the document names and their classes/labels, the first column called document with the document names present in the training folder and second column called class with the classes/labels the model is to learn so future documents can be associated to them with certain level of confidence. For an example CSV file, click here.--epochsis number of training iterations for the model, which can be increased if the loss is high at the end of training. Default:200.
# Train Outputs
model.ptis the file containing the retrained model, which can be used later for detecting the intent of a customer’s message.classes.jsonis the file containing all the unique classes found in the training dataset.
# Instructions
NOTE
The minimum resource recommendations to run this blueprint are 3.5 CPU and 8 GB RAM.
NOTE
This blueprint’s performance can benefit from using GPU as its compute.
Complete the following steps to train the document-classifier model:
Click the Use Blueprint button. The cnvrg Blueprint Flow page displays.
In the flow, click the S3 Connector task to display its dialog.
- Within the Parameters tab, provide the following Key-Value pair information:
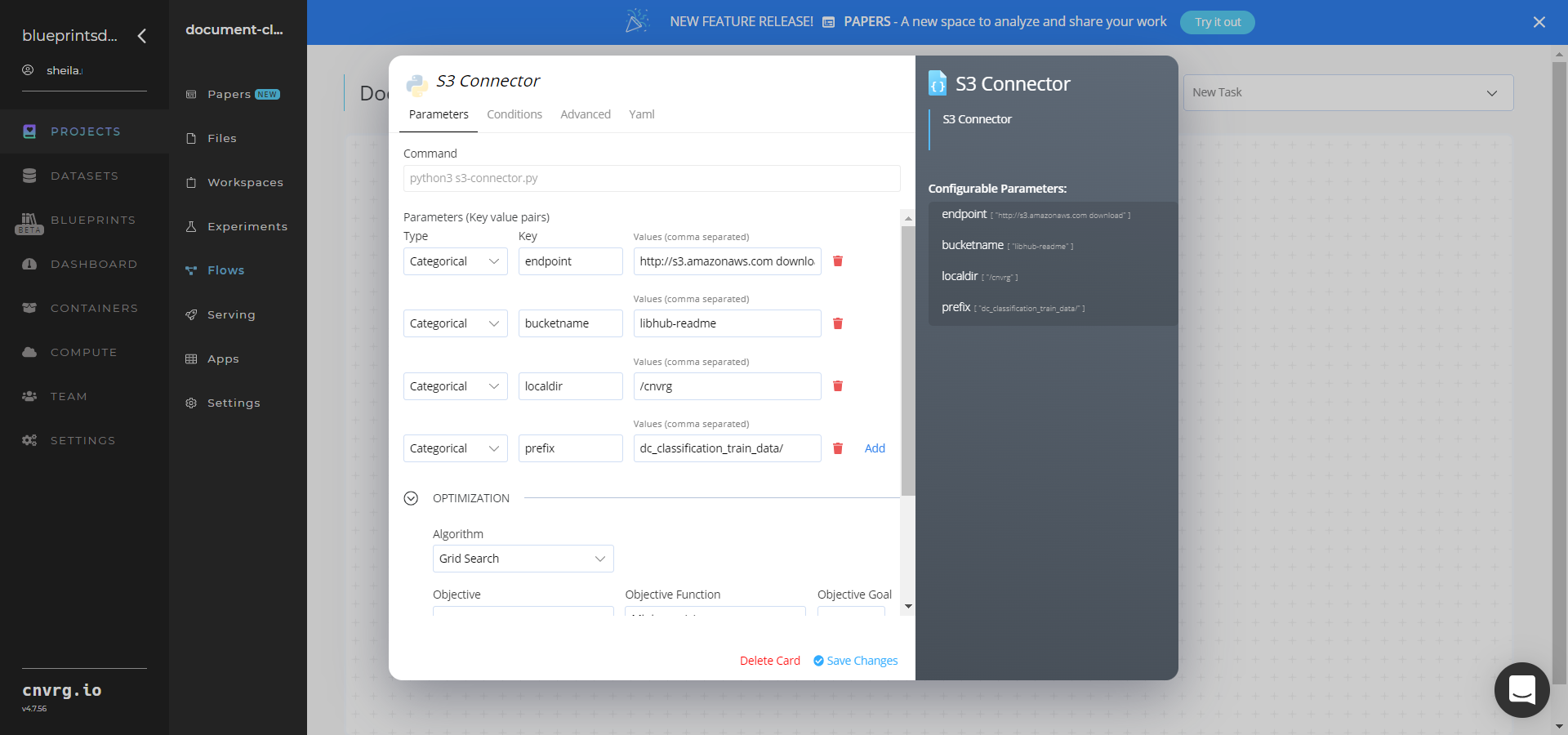
- Key:
bucketname- Value: enter the data bucket name - Key:
prefix- Value: provide the main path to the images folder
- Key:
- Click the Advanced tab to change resources to run the blueprint, as required.
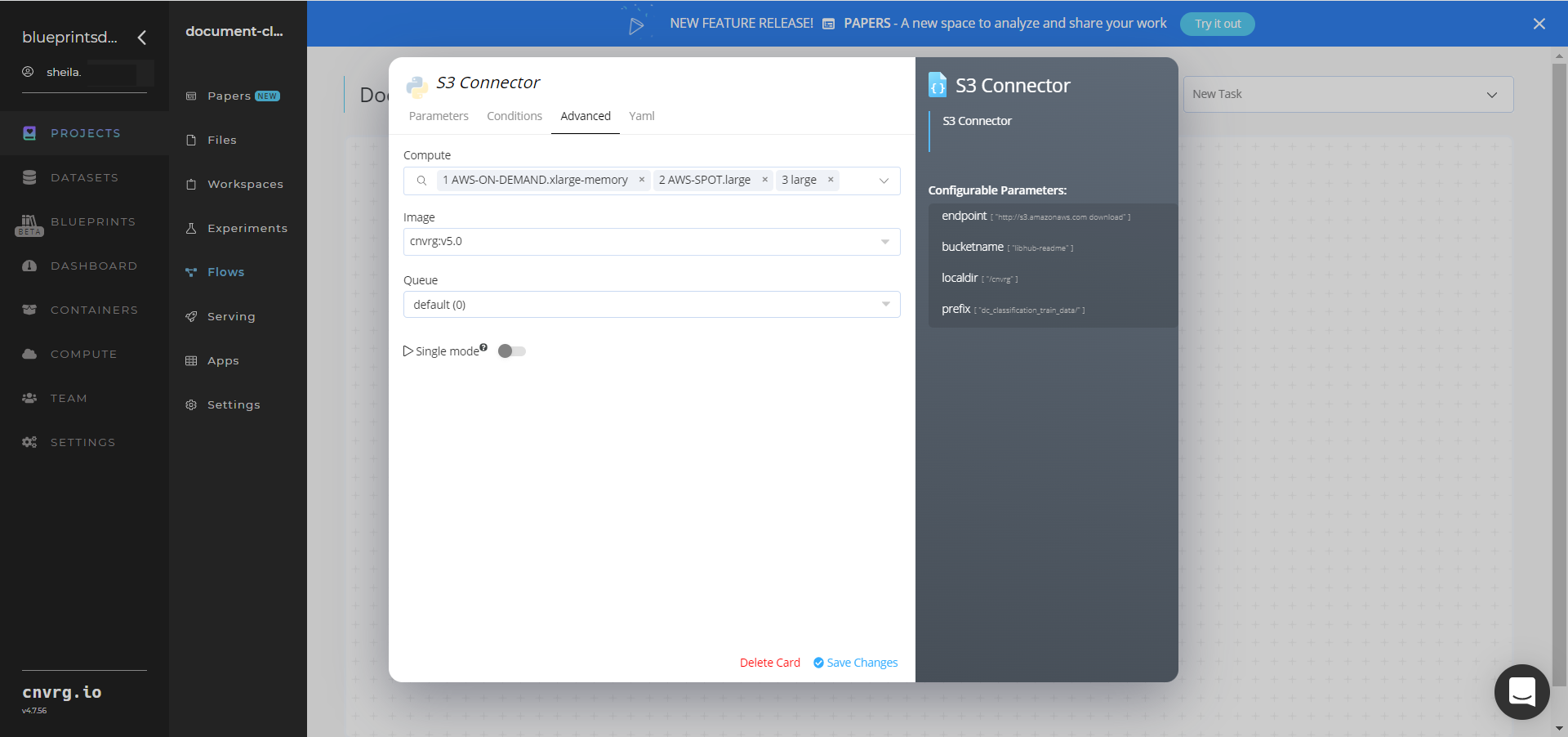
- Within the Parameters tab, provide the following Key-Value pair information:
Return to the flow and click the Train task to display its dialog.
Within the Parameters tab, provide the following Key-Value pair information:
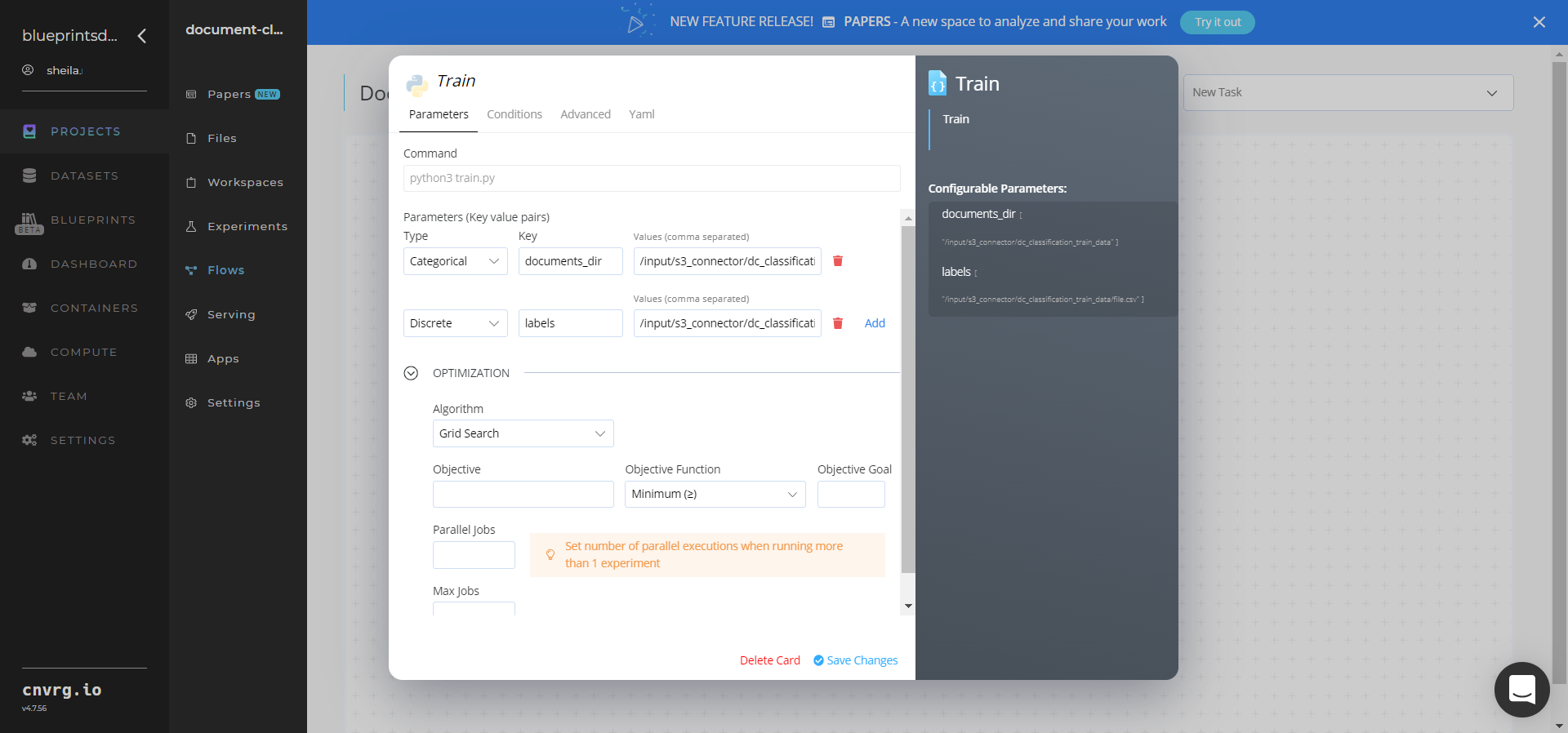
- Key:
documents_dir− Value: provide the path to the directory including the S3 prefix in the following format:/input/s3_connector/dc_classification_train_data - Key:
labels path− Value: provide the path to the CSV file containing mapping of document names to their classes in the following format:/input/s3_connector/dc_classification_train_data/file.csv - Key:
epochs− Value: provide the number of training iterations for the model.
NOTE
You can use the prebuilt example data paths provided.
- Key:
Click the Advanced tab to change resources to run the blueprint, as required.
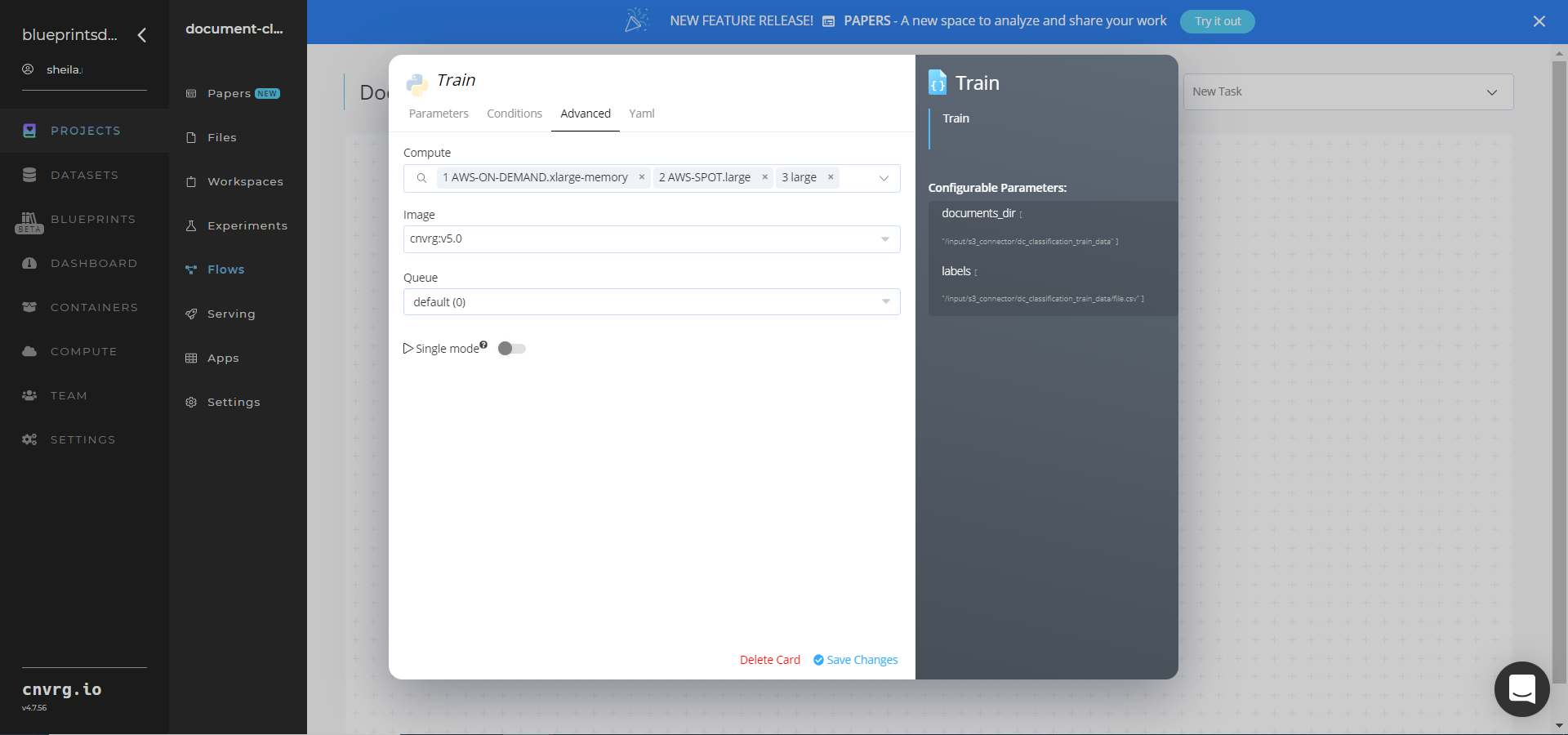
Click the Run button.
 The cnvrg software launches the training blueprint as set of experiments, generating a trained document-classifier model and deploying it as a new API endpoint.
The cnvrg software launches the training blueprint as set of experiments, generating a trained document-classifier model and deploying it as a new API endpoint.NOTE
The time required for model training and endpoint deployment depends on the size of the training data, the compute resources, and the training parameters.
For more information on cnvrg endpoint deployment capability, see cnvrg Serving.
Track the blueprint's real-time progress in its Experiment page, which displays artifacts such as logs, metrics, hyperparameters, and algorithms.
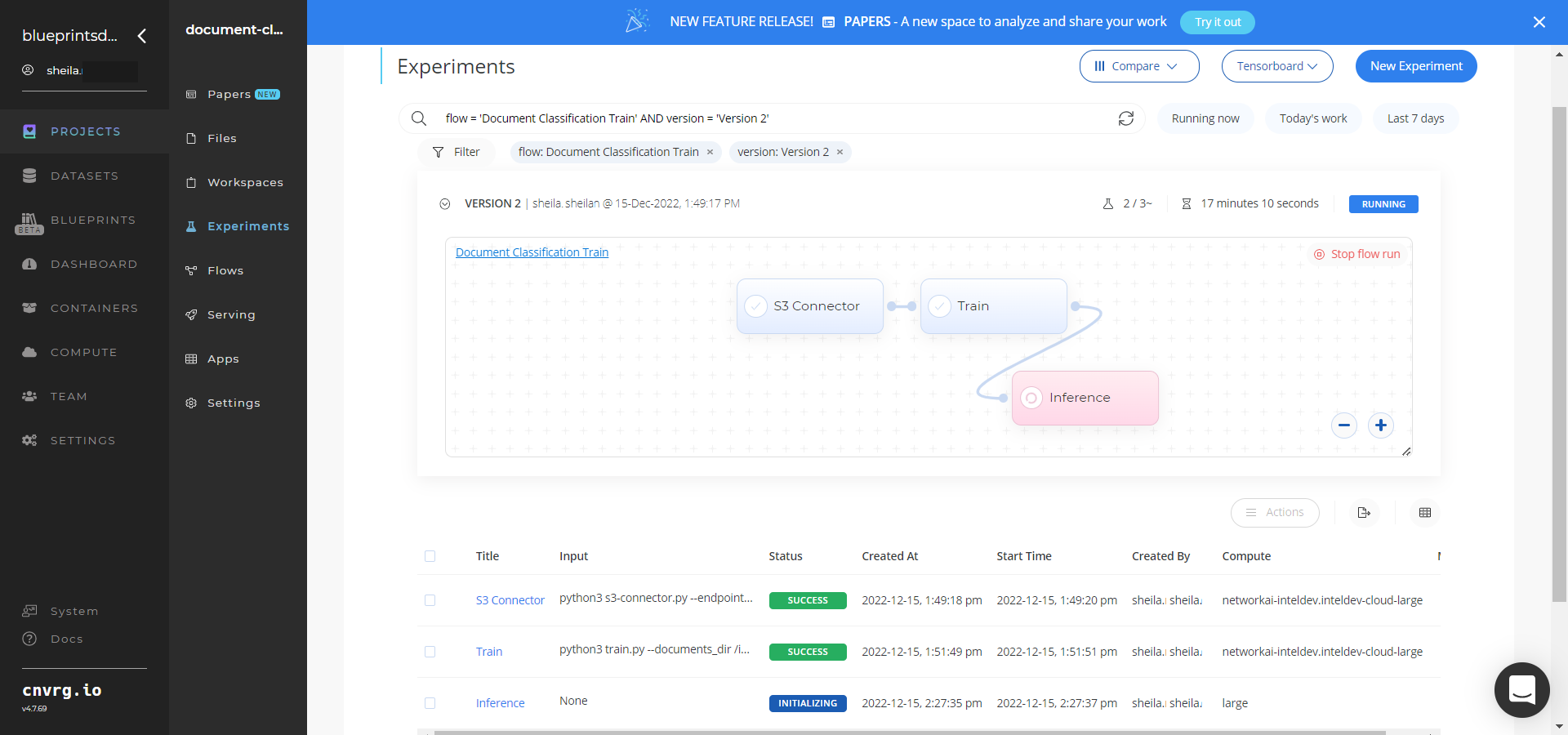
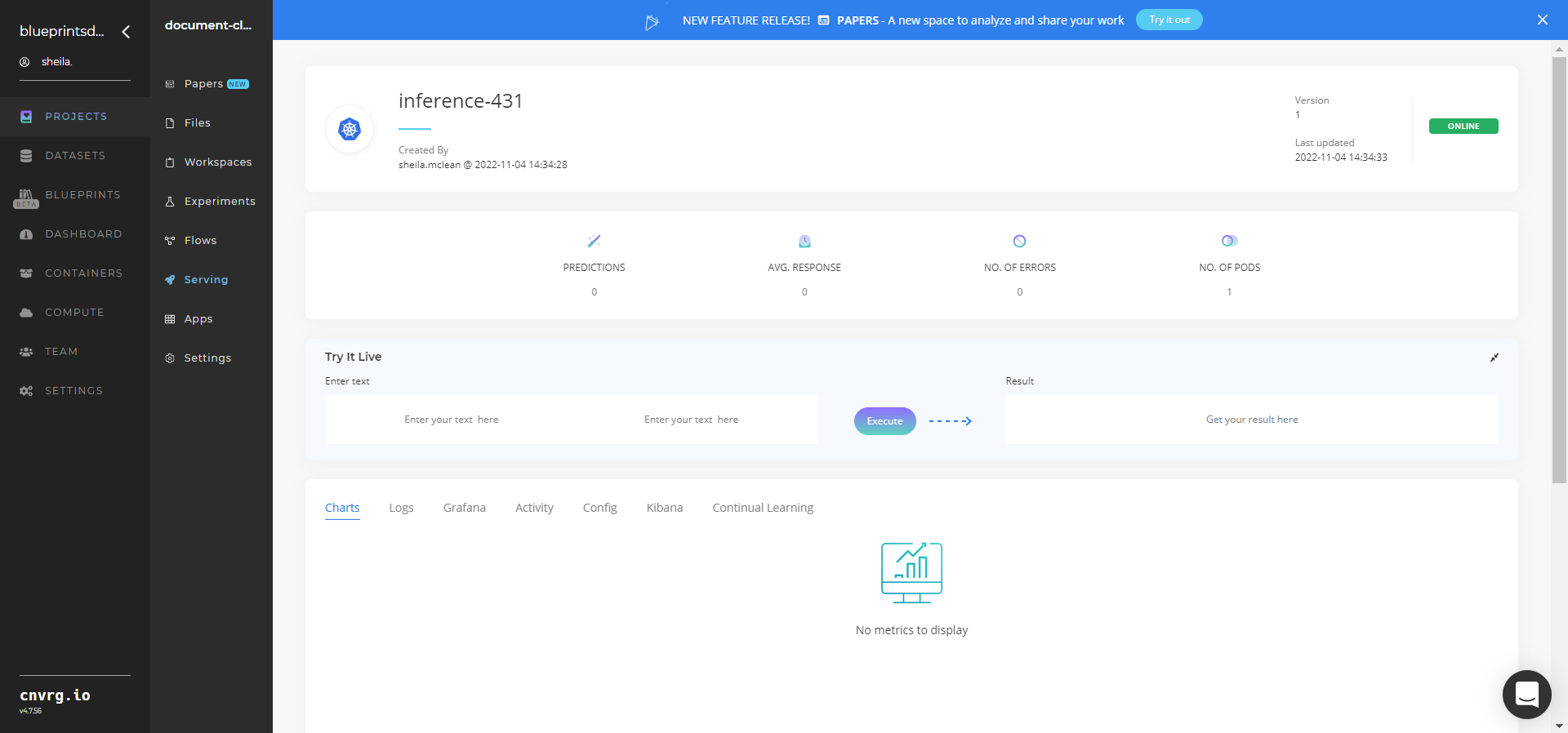
Click the Serving tab in the project and locate your endpoint.
Complete one or both of the following options:
- Use the Try it Live section with any document file or link to be classified.
- Use the bottom integration panel to integrate your API with your code by copying in the code snippet.
- Use the Try it Live section with any document file or link to be classified.
A custom model and API endpoint, which can classify a document’s textual content, have now been trained and deployed. For information on this blueprint’s software version and release details, click here.
# Connected Libraries
Refer to the following libraries connected to this blueprint:
# Related Blueprints
Refer to the following blueprints related to this training blueprint: