# NCF-Recommender AI Blueprint- deprecated from 11/2024
# Training
A recommender system is a set of algorithms that assesses people’s choices and generates responses for recommending similar items to them. The responses are based on a person’s selections from among a set list of items, and are specifically tailored to not repeat items the person has already viewed and rated.
# Overview
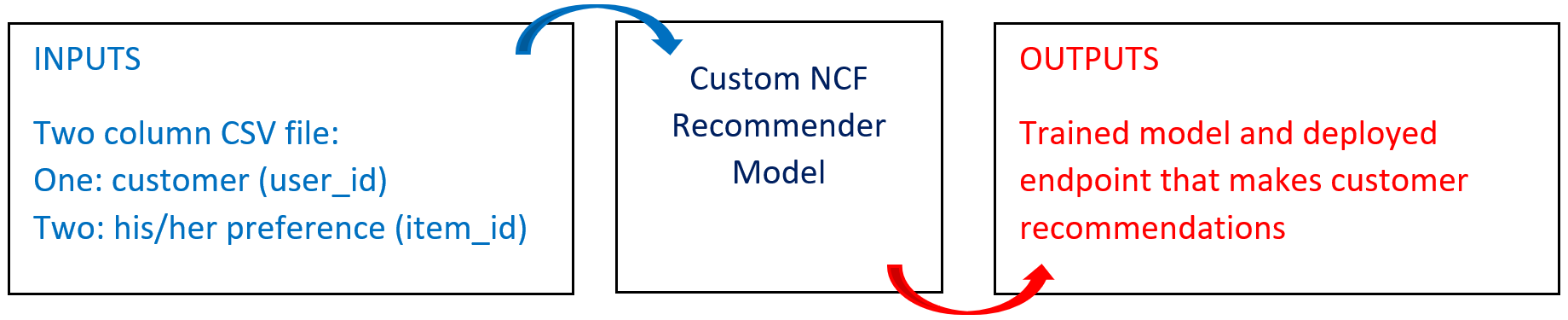
The following diagram provides an overview of this blueprint's inputs and outputs.
# Purpose
Use this training blueprint to train a custom neural network recommender model, which can recommend similar items to customers according to their behaviors. For the model to learn each customer’s choices and predict recommendations, the blueprint requires data in the form of a customer’s preference on current items. Model predictions are based directly on scores, which are essentially predicted ratings for all items rather than just the ones the customer has already viewed and rated. This blueprint also establishes an endpoint that recommends similar items according to customer behavior based on the newly trained model.
To train this model with your data, provide one folder in the S3 Connector with a CSV file that includes two columns: user_id and item_id. The model can also be trained on weighted data. To do so, include an extra column named 'weight' in the training data CSV file.
# Deep Dive
The following flow diagram illustrates this blueprint's pipeline:
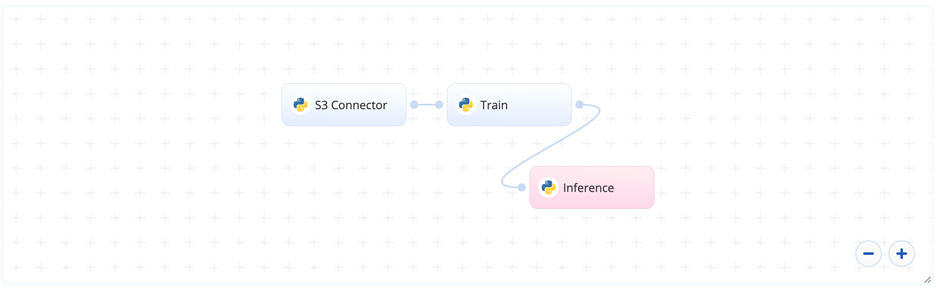
# Flow
The following list provides a high-level flow of this blueprint’s run:
- In the S3 Connector, the user provides the data bucket name and the directory path where the CSV file is located.
- In the Train task, the user provides the path to the CSV file directory including the previous S3 prefix.
- The blueprint trains the model with the user-provided custom data and deploys an endpoint that recommends similar items to customers according to their behavior.
# Arguments/Artifacts
# Inputs
--filenameis the training dataset.--epochsis the number of epochs in the train process.--batch_size(int) is the number of times the model evaluates in each epoch. Default:256.
# Outputs
items_list.jsonis a JSON file containing a list of the item numbers.model.ptis the trained model.
# Instructions
NOTE
This blueprint requires resources of 1 GPU, 4 CPU, and 32 GB RAM to run.
NOTE
This blueprint’s performance can benefit from using GPU as its compute.
Complete the following steps to train this NCF-recommender model:
Click the Use Blueprint button. The cnvrg Blueprint Flow page displays.
In the flow, click the S3 Connector task to display its dialog.
- Within the Parameters tab, provide the following Key-Value pair information:
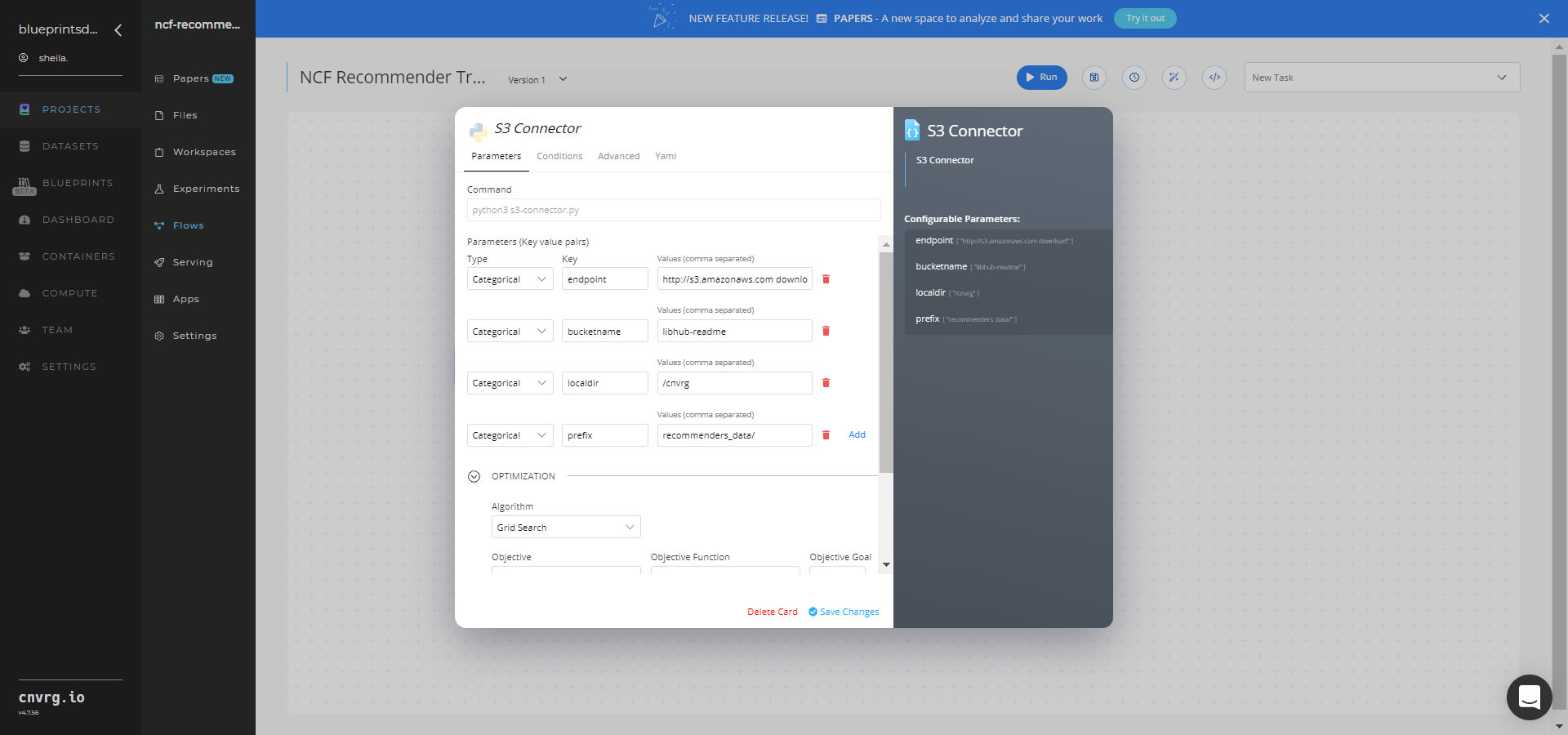
- Key:
bucketname- Value: enter the data bucket name - Key:
prefix- Value: provide the main path to the CVS file folder
- Key:
- Click the Advanced tab to change resources to run the blueprint, as required.
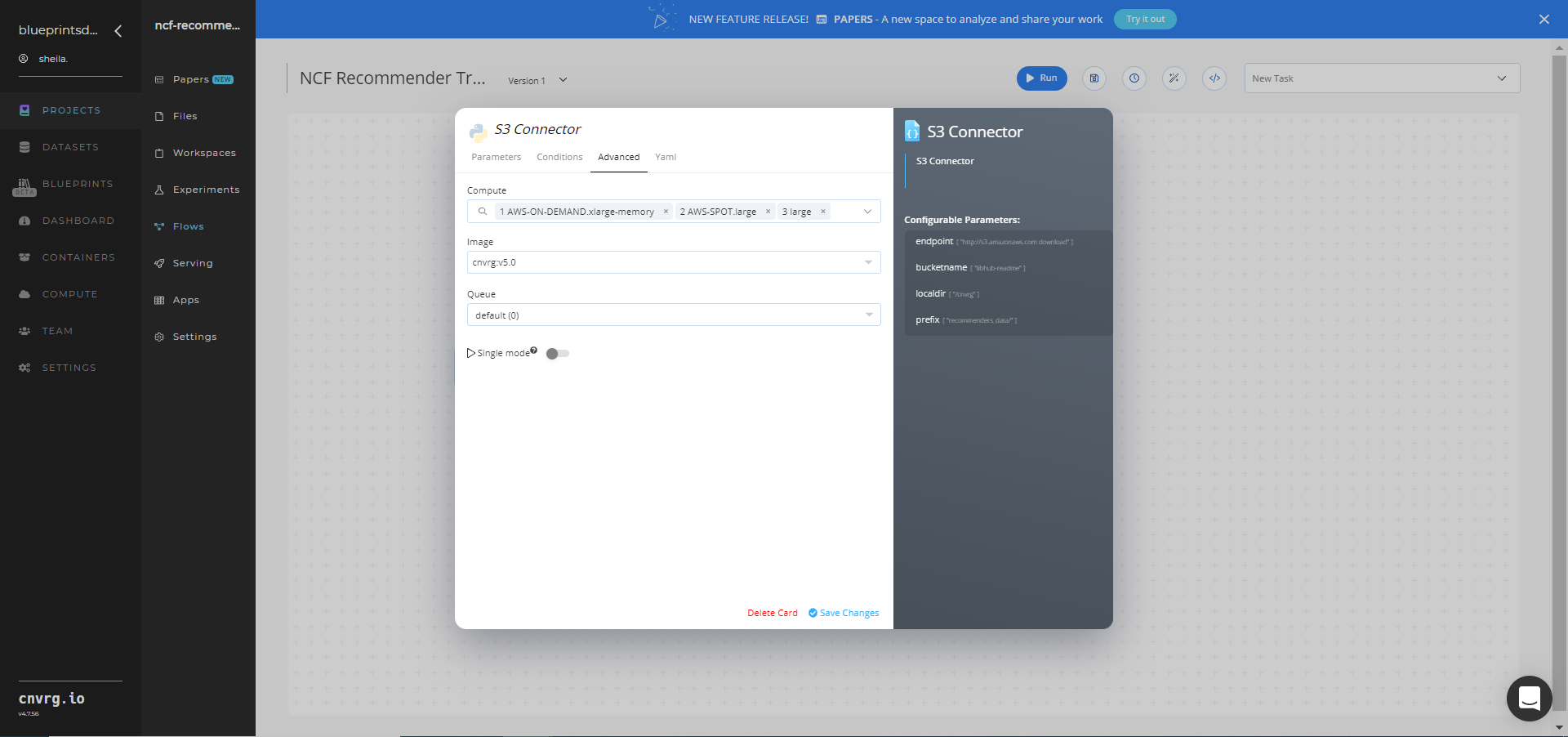
- Within the Parameters tab, provide the following Key-Value pair information:
Return to the flow and click the Train task to display its dialog.
Within the Parameters tab, provide the following Key-Value pair information:
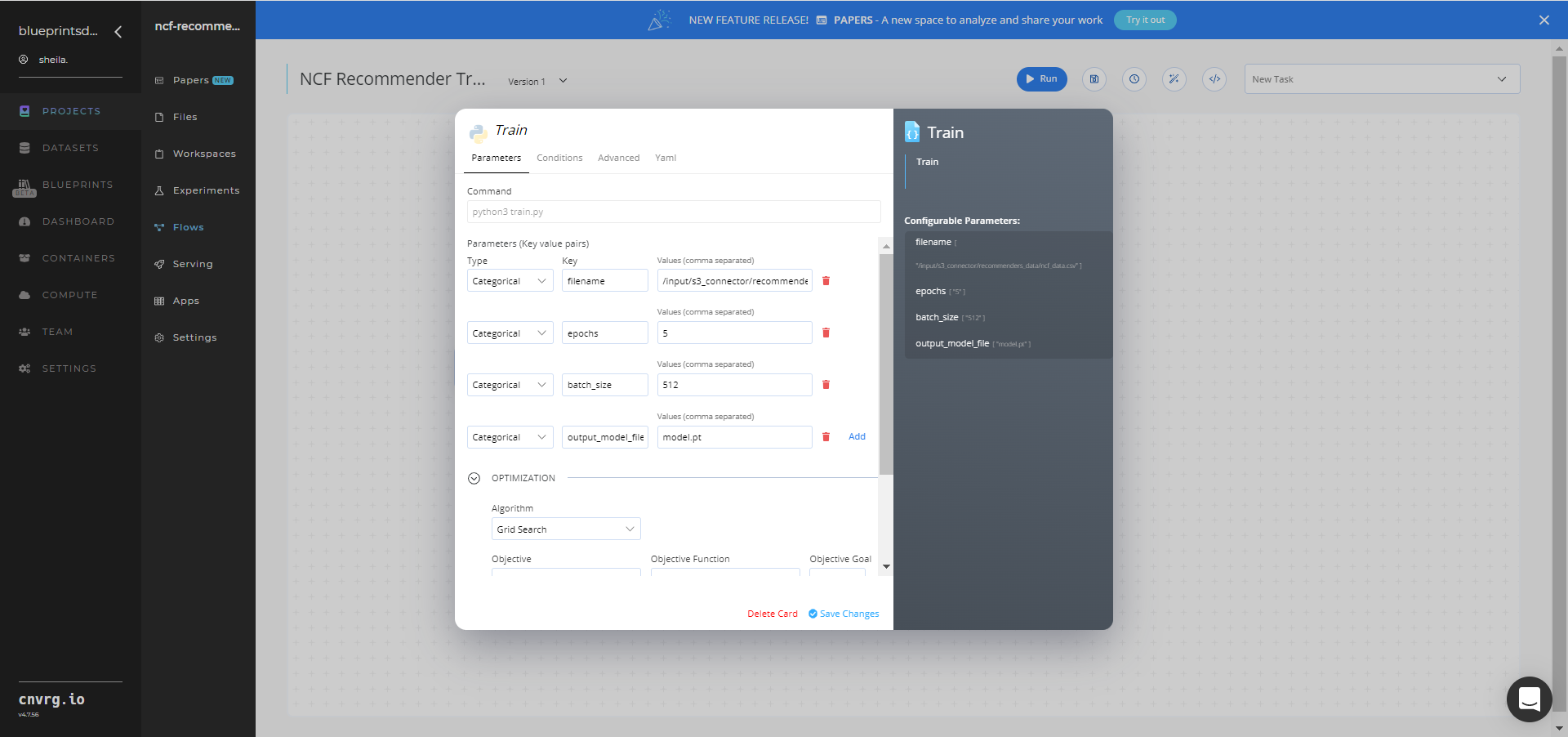
- Key:
filename− Value: provide the path to the CSV file including the S3 prefix in the following format:/input/s3_connector/<prefix>/<csv file> - Key:
epochs− Value: set the number of times the model passes over the dataset - Key:
batch_size− Value: set the number of times the model evaluates in each epoch
NOTE
You can use the prebuilt example data paths provided.
- Key:
Click the Advanced tab to change resources to run the blueprint, as required.
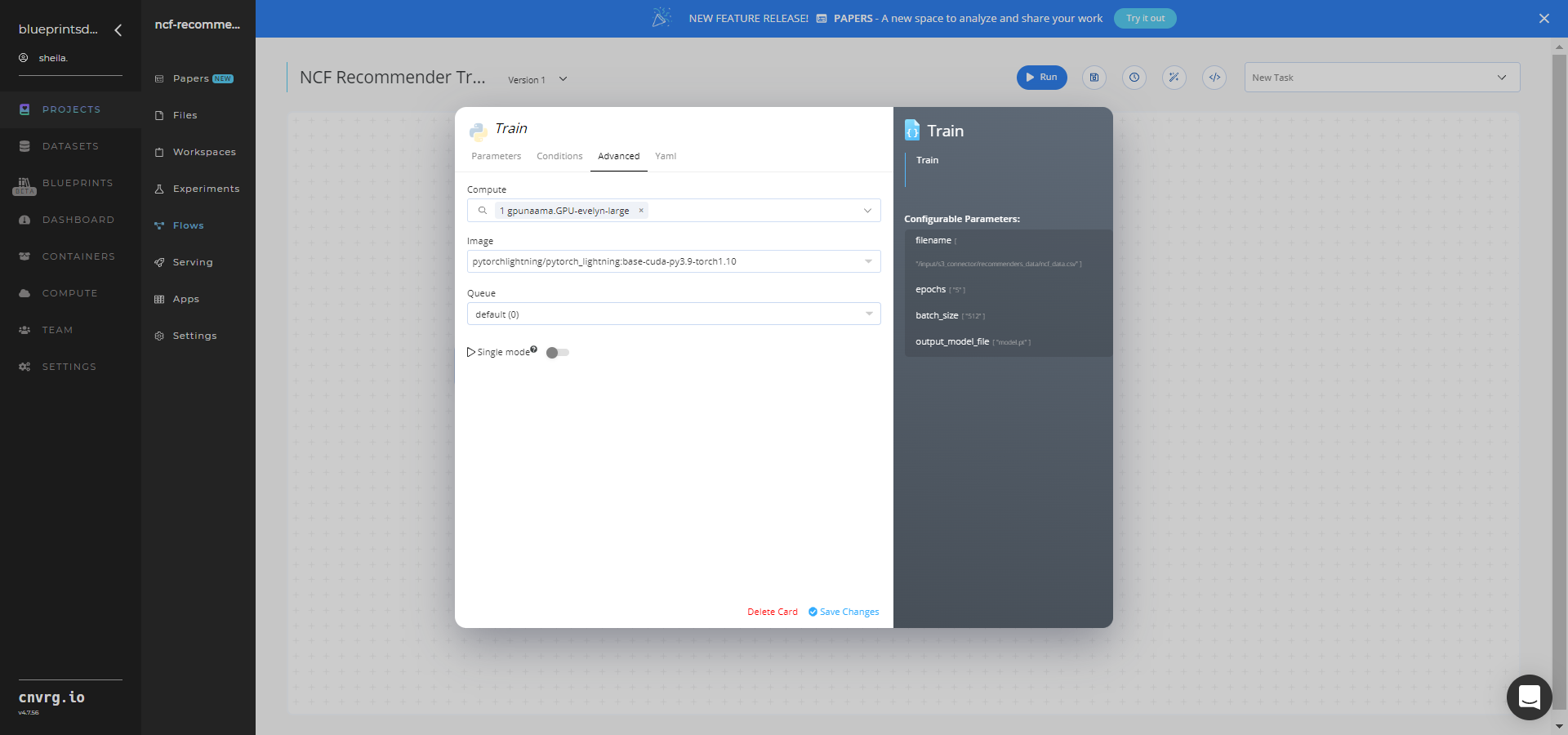
Click the Run button.
 The cnvrg software launches the training blueprint as set of experiments, generating a trained NCF-recommender model and deploying it as a new API endpoint.
The cnvrg software launches the training blueprint as set of experiments, generating a trained NCF-recommender model and deploying it as a new API endpoint.NOTE
The time required for model training and endpoint deployment depends on the size of the training data, the compute resources, and the training parameters.
For more information on cnvrg endpoint deployment capability, see cnvrg Serving.
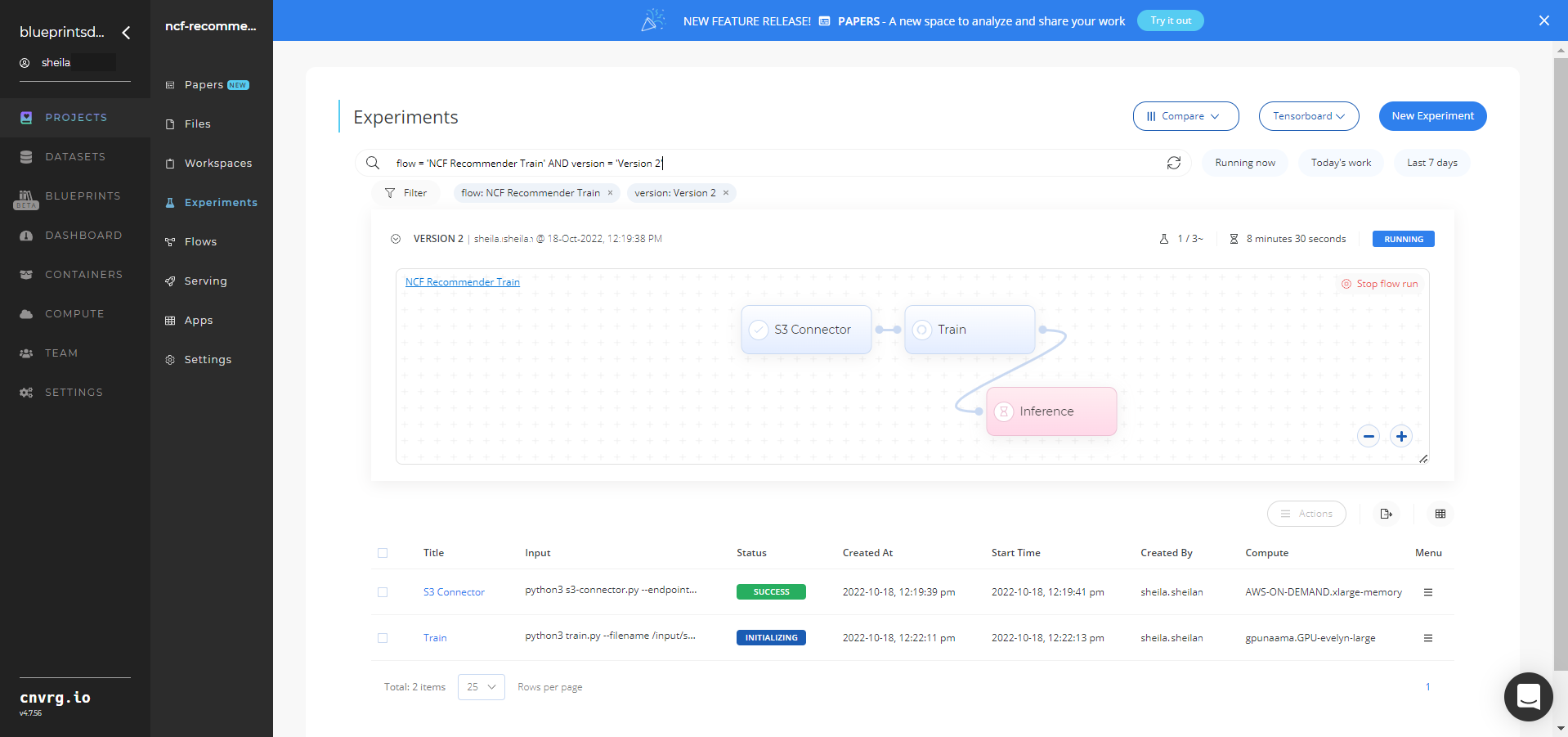
Track the blueprint's real-time progress in its Experiments page, which displays artifacts such as logs, metrics, hyperparameters, and algorithms.
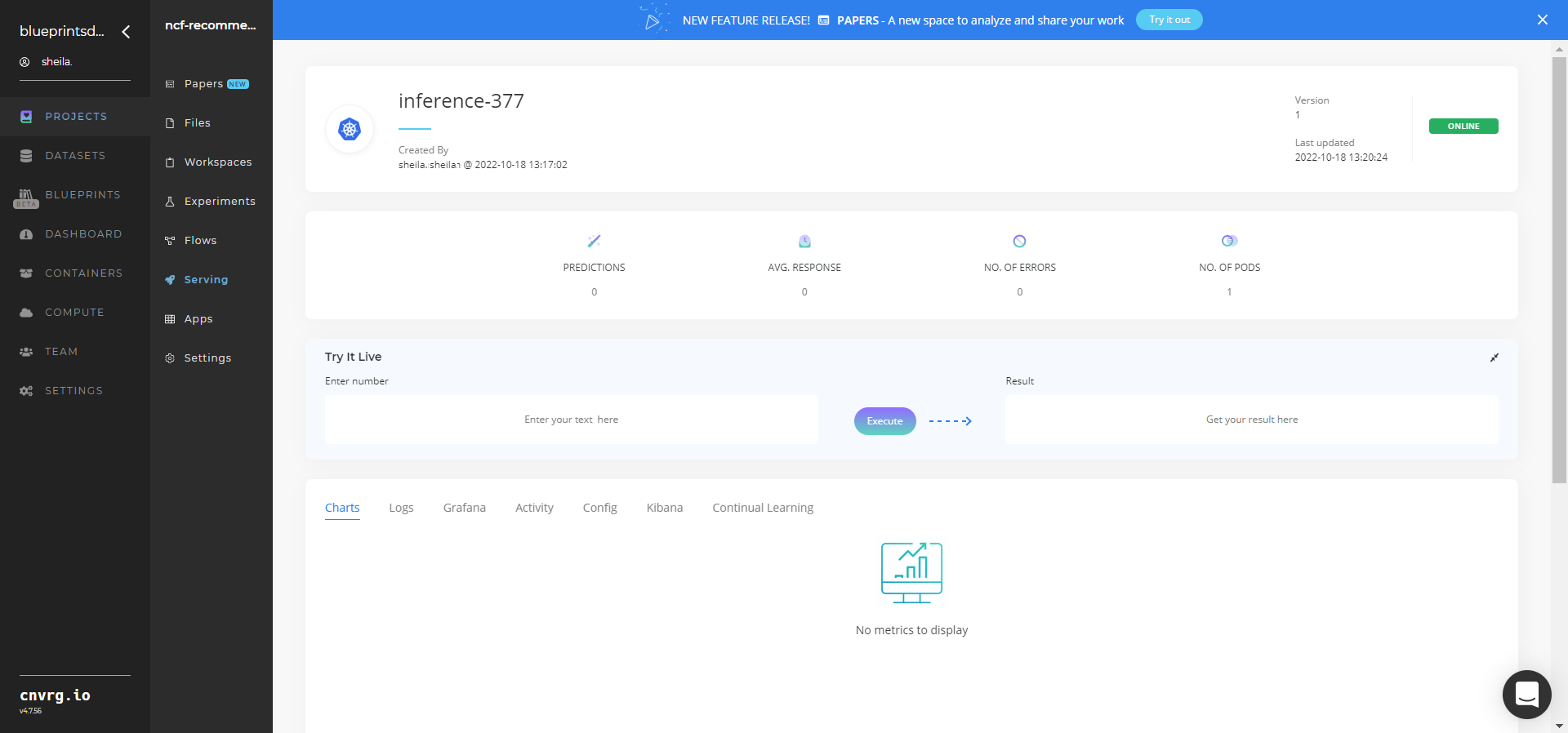
Click the Serving tab in the project and locate your endpoint.
Complete one or both of the following options:
- Use the Try it Live section with a relevant user ID to check the model's predictions.
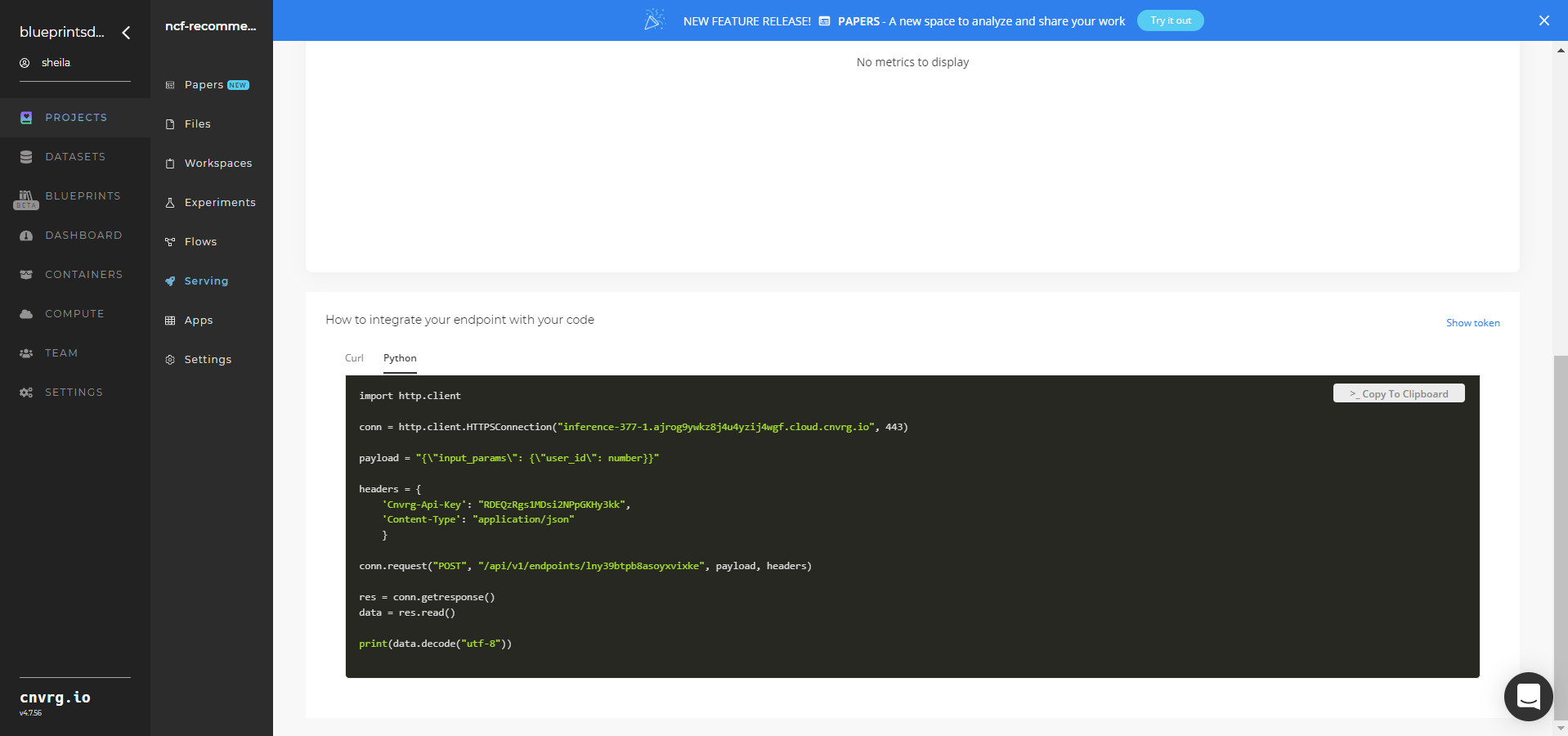
- Use the bottom integration panel to integrate your API with your code by copying in your code snippet.
- Use the Try it Live section with a relevant user ID to check the model's predictions.
A custom NCF-recommender model and an API endpoint, which can recommend similar items to customers according to their behavior, have now been trained and deployed. For information on this blueprint’s software version and release details, click here.
# Connected Libraries
Refer to the following libraries connected to this blueprint:
# Related Blueprints
Refer to the following blueprints related to this training blueprint: