# QnA AI Blueprint - deprecated from 11/2024
# Inference
Question and answer (QnA) generation is the task of generating pairs of questions and answers based on input text. A QnA generator is a NLP-based model that uses text sections to answer questions. A trained QnA generator can provide immediate, brief responses to customer questions.
# Purpose
Use this inference blueprint to deploy a QnA-generator API endpoint. To use this pretrained QnA-generator model, create a ready-to-use API-endpoint that is quickly integrated with your raw text data as input and is returned as pairs of questions and answers as output.
This inference blueprint’s model was trained using the Stanford Question Answering Dataset (SQuAD) v1.0. To use custom QnA data according to your specific business, run this counterpart’s training blueprint, which trains the model and establishes an endpoint based on the newly trained model.
# Instructions
NOTE
The minimum resource recommendations to run this blueprint are 3.5 CPU and 8 GB RAM.
NOTE
This blueprint’s performance can benefit from using GPU as its compute.
Complete the following steps to deploy a QnA-generator API endpoint:
- Click the Use Blueprint button. The cnvrg Blueprint Flow page displays.
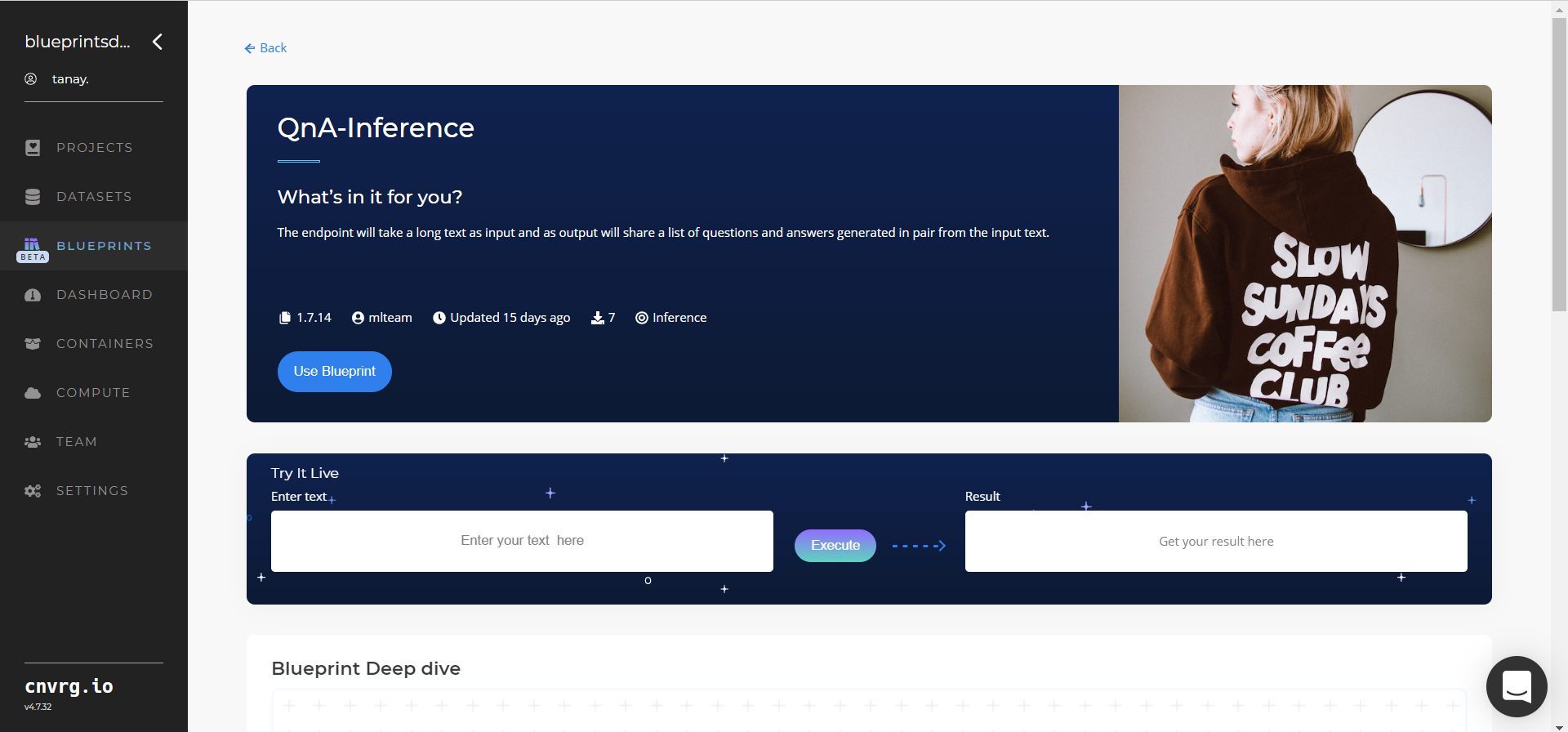
- In the dialog, select the relevant compute to deploy the API endpoint and click the Start button.
- The cnvrg software redirects to your endpoint. Complete one or both of the following options:
- Use the Try it Live section with any text passage to check the model.
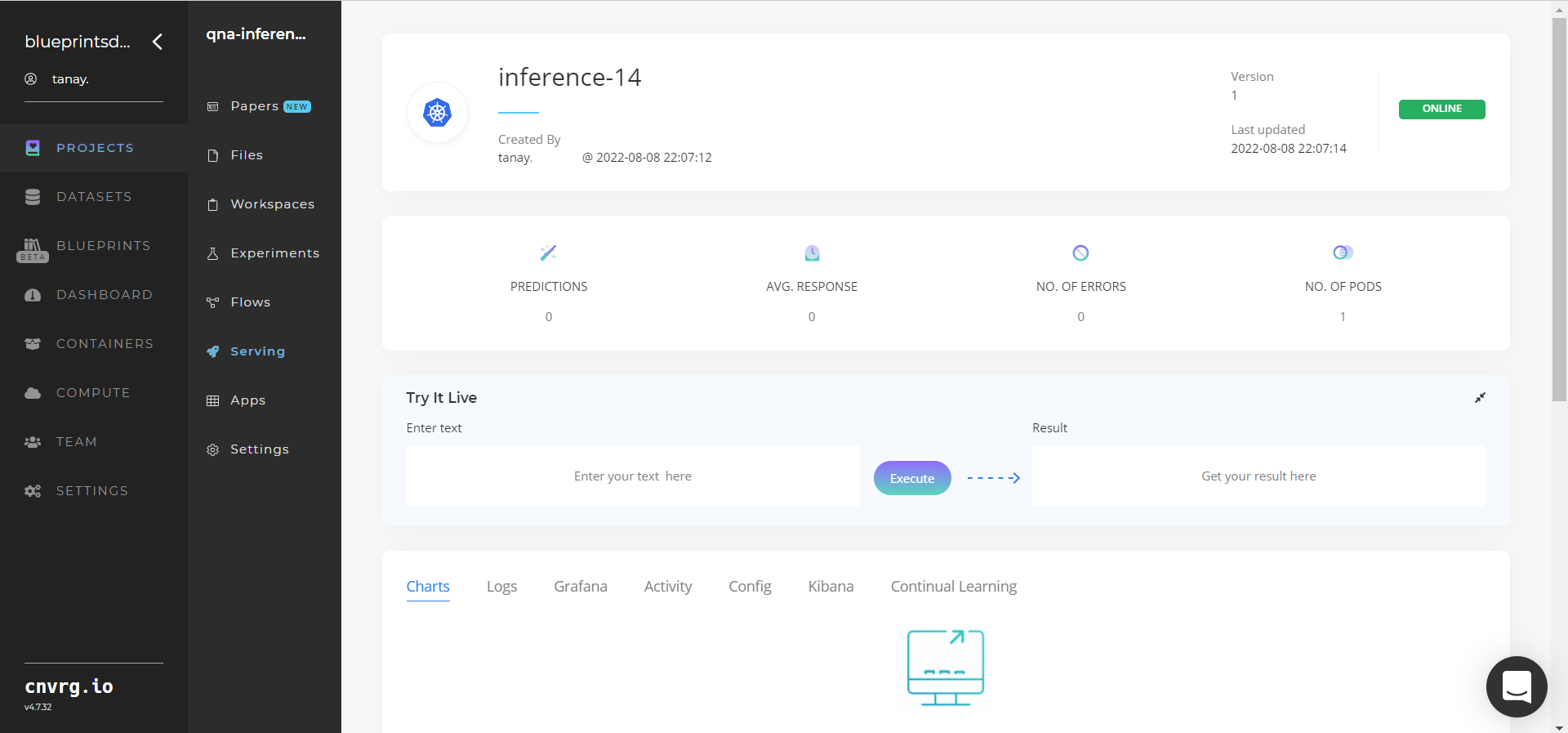
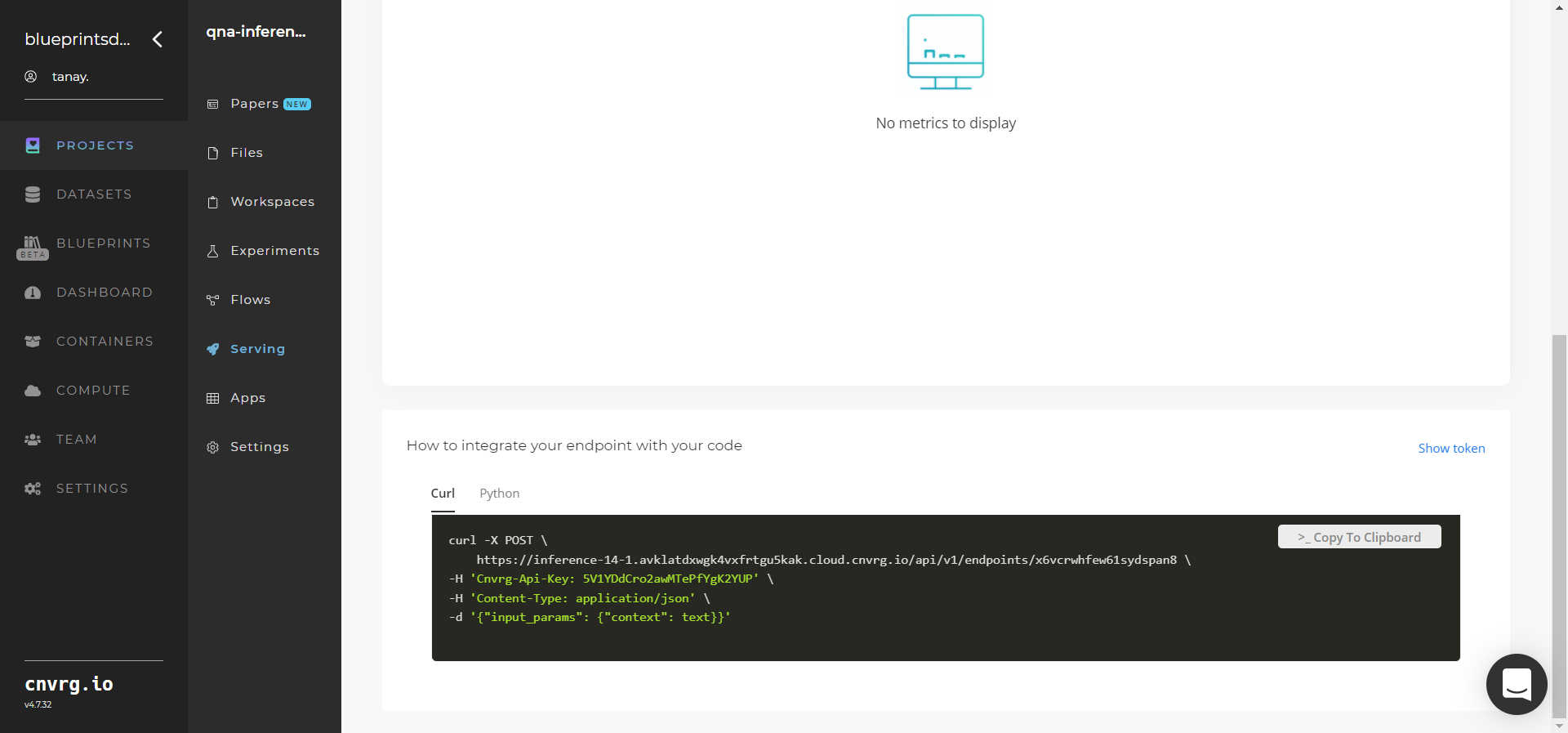
- Use the bottom integration panel to integrate your API with your code by copying in your code snippet.
- Use the Try it Live section with any text passage to check the model.
An API endpoint that returns the QnA pairs for input text has now been deployed. For information on this blueprint’s software version and release details, click here.
# Related Blueprints
The following blueprints are related to this inference blueprint:
# Training
Question and answer (QnA) generation is the task of generating pairs of questions and answers based on input text. A QnA generator is a NLP-based model that uses text sections to answer questions. A trained-QnA generator can provide immediate, brief responses to customer questions.
# Overview
This blueprint trains a QnA generator. For answer-aware question generation, three models are usually needed, adding multi-model complexity to a single task:
- First model − extracts an answer like spans
- Second model − generates a question to that answer
- Third QA model − takes the question and produces an answer
The two answers are then compared to determine whether the generated question is correct. The T5 model is fine-tuned in multitask manner, and is further trained on the input data.
# Purpose
Using an extensive dataset, this training blueprint retrains a QnA model to enhance its performance. This blueprint also establishes an endpoint that returns QnA pairs for input text based on the newly trained model.
The Prepare library task prepares the input data for training by converting it into PyTorch datasets and splitting it into train and development data. The input data format for the Training task is SQuAD v1.0 in the form of a single JSON file. This blueprint trains the QnA model and deploys a fine-tuned model that can be used for inference using API calls.
# Deep Dive
The following flow diagram illustrates this blueprint's pipeline:
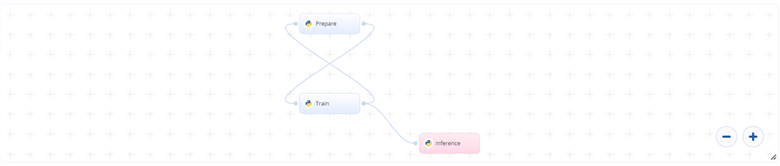
# Flow
The following list provides a high-level flow of this blueprint’s run:
- In the Prepare task, provide the path to the training data folder including the S3 Connector prefix.
- In the Train task, provide the
--num_train_epochsand--output_dirto set the number of times the model trains on the dataset and the output folder to store the newly trained model, respectively.
# Arguments/Artifacts
For more information on this blueprint’s tasks, its inputs, and outputs, click here.
# Prepare Input
--data_source is the location of the JSON file in the input cnvrg dataset.
# Prepare Outputs
The Prepare outputs are PyTorch datasets comprising train_data_qg_hl_t5.pt and valid_data_qg_hl_t5.pt. There is also a t5_qg_tokenizer folder containing the tokenizer used to create the training data. The model uses both the datasets and tokenizer for training.
# Train Inputs
--num_train_epochsis the number of times the model goes through the dataset while learning.--output_diris the name of the output folder that contains the final trained model. Download and save this folder for future usage.
# Train Outputs
The final output contains a t5-small-qg-hl folder containing the trained model and the tokenizer. This folder is referenced when using the new model to generate questions and answers.
# Instructions
NOTE
The minimum resource recommendations to run this blueprint are 3.5 CPU and 8 GB RAM.
NOTE
This blueprint’s performance can benefit from using GPU as its compute.
Complete the following steps to train and deploy a QnA-generator model and an API endpoint:
Click the Use Blueprint button. The cnvrg Blueprint Flow page displays.
In the flow, click the Prepare task to display its dialog.
- Within the Parameters tab, provide the following Key-Value pair information:
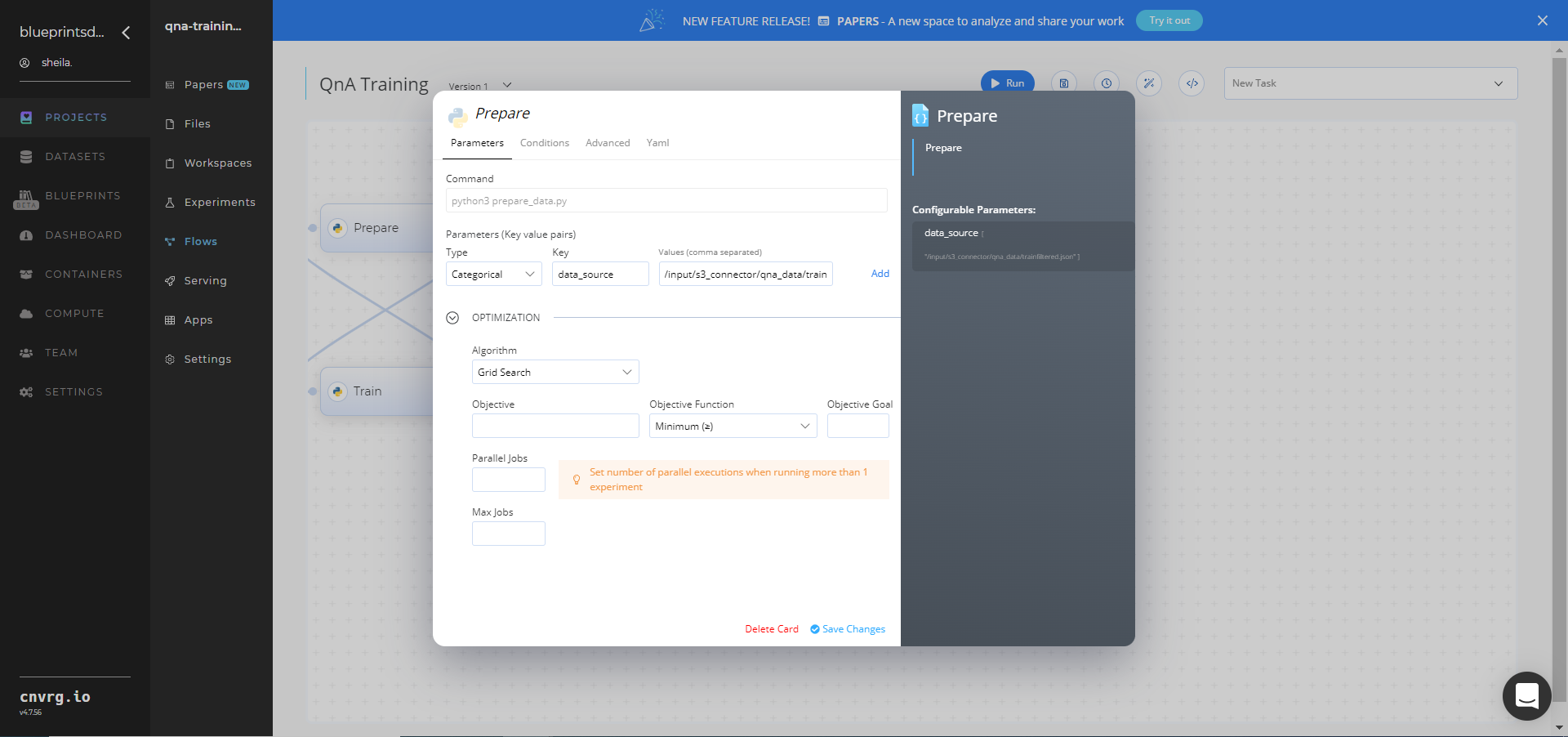
- Key:
data_source− Value: provide the path to the data folder including the S3 prefix /input/s3_connector/qna_data/trainfiltered.json− ensure the path adheres to this format
- Key:
- Click the Advanced tab to change resources to run the blueprint, as required.
- Within the Parameters tab, provide the following Key-Value pair information:
Return to the flow and click the Train task to display its dialog.
- Within the Parameters tab, provide the following Key-Value pair information:
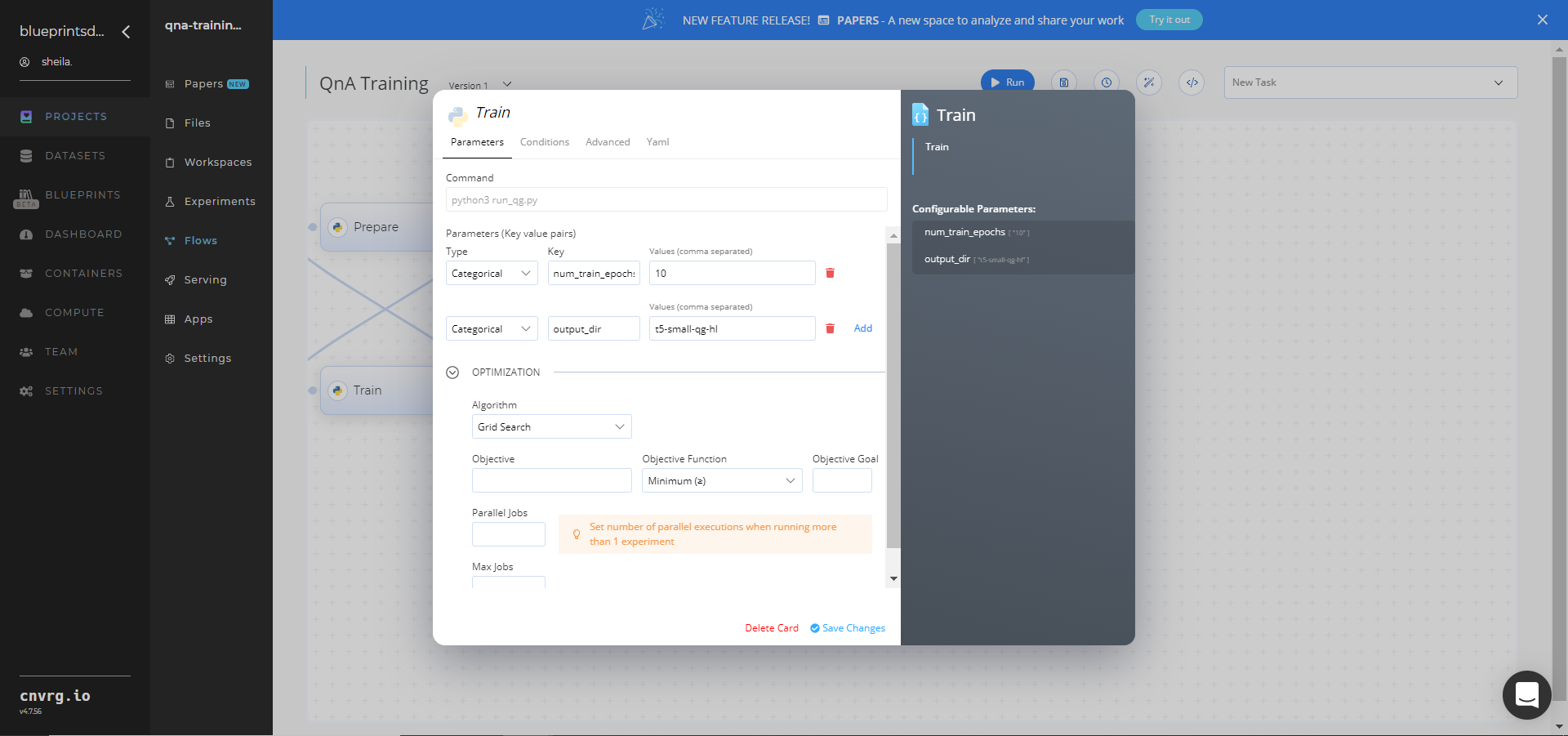
- Key:
--num_train_epochs− Value: set the number of times the model trains on the dataset - Key:
--output_dir− Value: provide the output folder to store the final trained model
- Key:
- Click the Advanced tab to change resources to run the blueprint, as required.
- Within the Parameters tab, provide the following Key-Value pair information:
Click the Run button.

The cnvrg software launches the training blueprint as set of experiments, producing a trained QnA-generator model and deploying it as a new API endpoint.
NOTE
The time required for model training and endpoint deployment depends on the size of the training data, the compute resources, and the training parameters.
For more information on cnvrg endpoint deployment capability, see cnvrg Serving.
Track the blueprint's real-time progress in its Experiments page, which displays artifacts such as logs, metrics, hyperparameters, and algorithms.
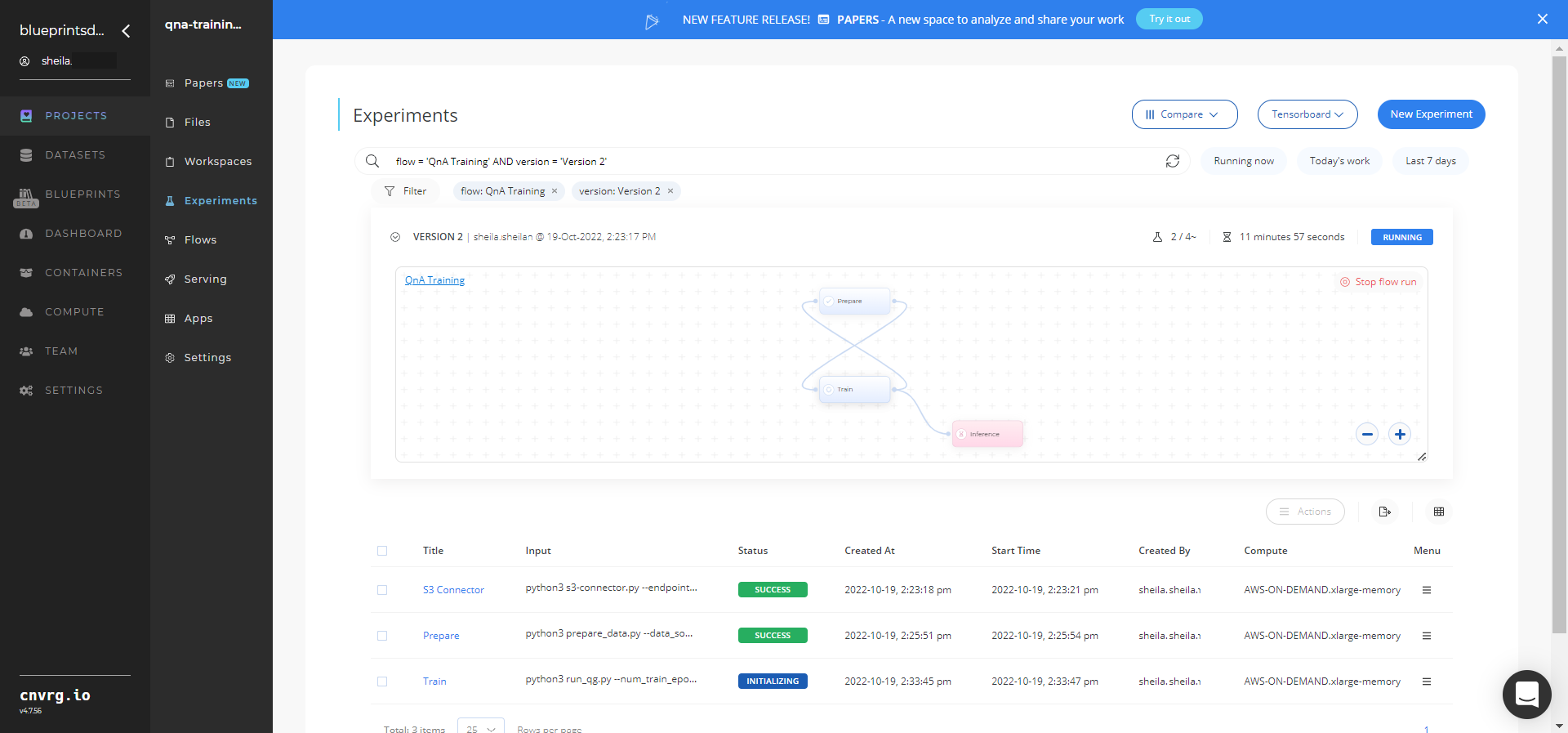
Click the Serving tab in the project and locate your endpoint.
Complete one or both of the following options:
- Use the Try it Live section with any text passage to check the model.
- Use the bottom integration panel to integrate your API with your code by copying in your code snippet.
- Use the Try it Live section with any text passage to check the model.
A QnA model and an API endpoint, which returns the QnA pairs for input text, have now been retrained and deployed. For information on this blueprint’s software version and release details, click here.
# Connected Libraries
Refer to the following libraries connected to this blueprint:
# Related Blueprints
Refer to the following blueprints related to this training blueprint: