# Remaining Useful Life AI Blueprint -deprecated from 11/2024
# Batch-Predict
Remaining useful life (RUL) is a time estimate that an asset like equipment or a machine is expected to operate before it requires maintenance, repair, or replacement. Estimating RUL enables companies to schedule maintenance and anticipate repairs so operating efficiency can be optimized and unplanned downtime can be avoided.
# Purpose
Use this batch blueprint to run a pretrained convolutional neural network (CNN) model with your customized dataset to predict when a company asset is likely to fail within given cycles. To clean and validate the data on which to further train the model, provide one folder in the S3 Connector containing your raw training data.
# Deep Dive
The following flow diagram illustrates this batch-predict blueprint’s pipeline:
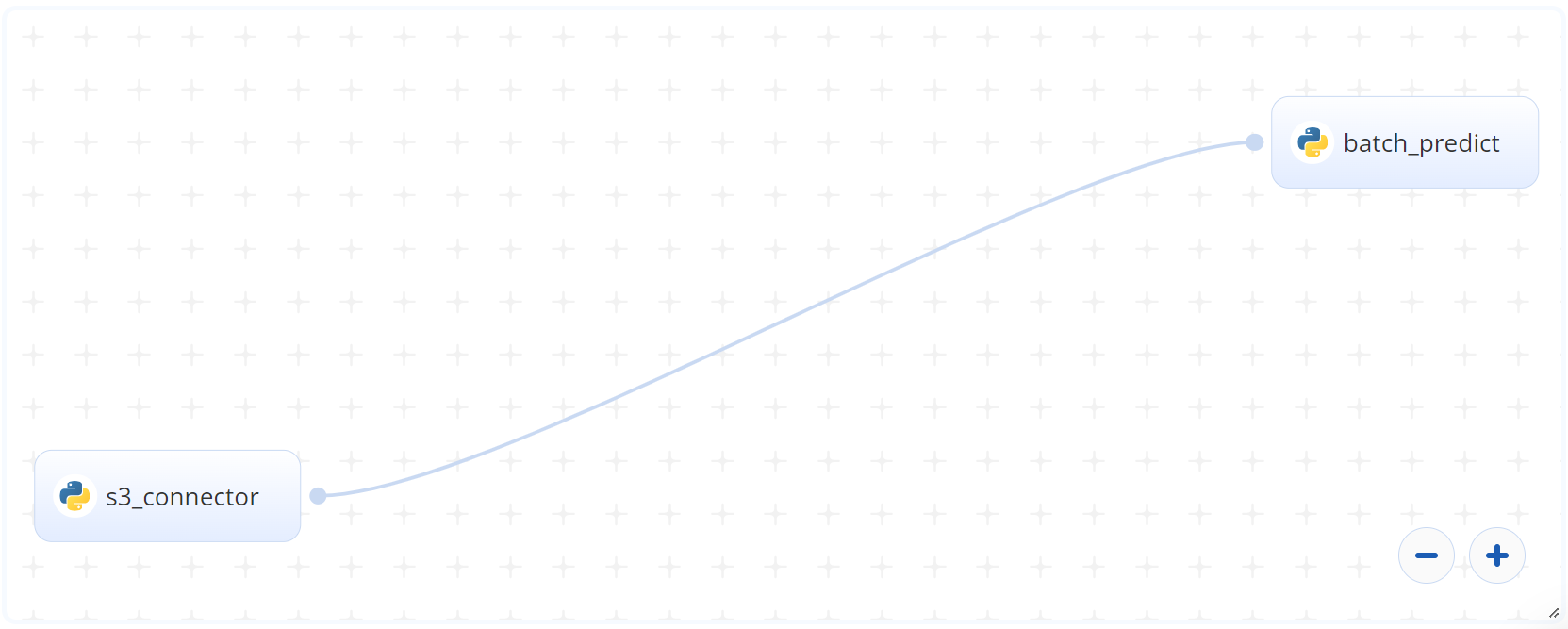
# Flow
The following list provides a high-level flow of this blueprint’s run:
- In the S3 Connector, provide the data bucket name and directory path to the training data CSV file
- In the Batch Predict task, provide the S3 Connector paths to the test dataset, trained model, and shape dataframe
# Arguments/Artifacts
For more information on this blueprint’s tasks, its inputs, and outputs, click here.
# Batch-Predict Inputs
--x_testis the user-provided raw test dataset.--cnnis the pretrained 2-D CNN model.--shape_datais a dataframe containing multiple variables to batch predict from data preprocessing block.
# Batch-Predict Outputs
--output.csvis the name of the file containing the predictions for each individual ID or machine.
# Batch-Predict Instructions
NOTE
The minimum resource recommendations to run this blueprint are 3.5 CPU and 8 GB RAM.
NOTE
This blueprint’s performance can benefit from using GPU as its compute.
Complete the following steps to run this RUL-predictor blueprint in batch mode:
- Click the Use Blueprint button. The cnvrg Blueprint Flow page displays.
- In the flow, click the S3 Connector task to display its dialog.
- Within the Parameters tab, provide the following Key-Value pair information:
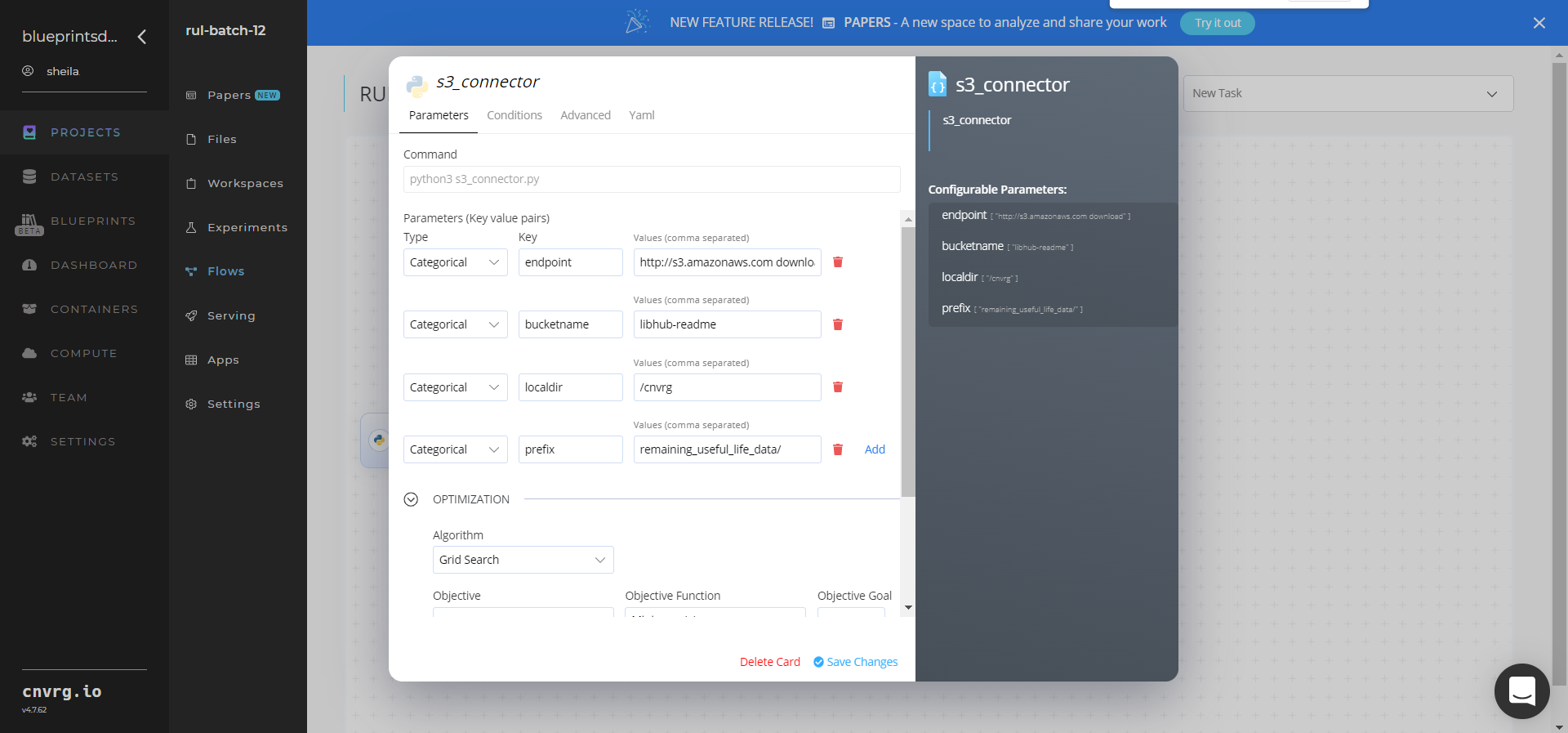
- Key:
bucketname− Value: provide the data bucket name - Key:
prefix− Value: provide the main path to the images folders
- Key:
- Click the Advanced tab to change resources to run the blueprint, as required.
- Within the Parameters tab, provide the following Key-Value pair information:
- Click the Batch-Predict task to display its dialog.
Within the Parameters tab, provide the following Key-Value pair information:
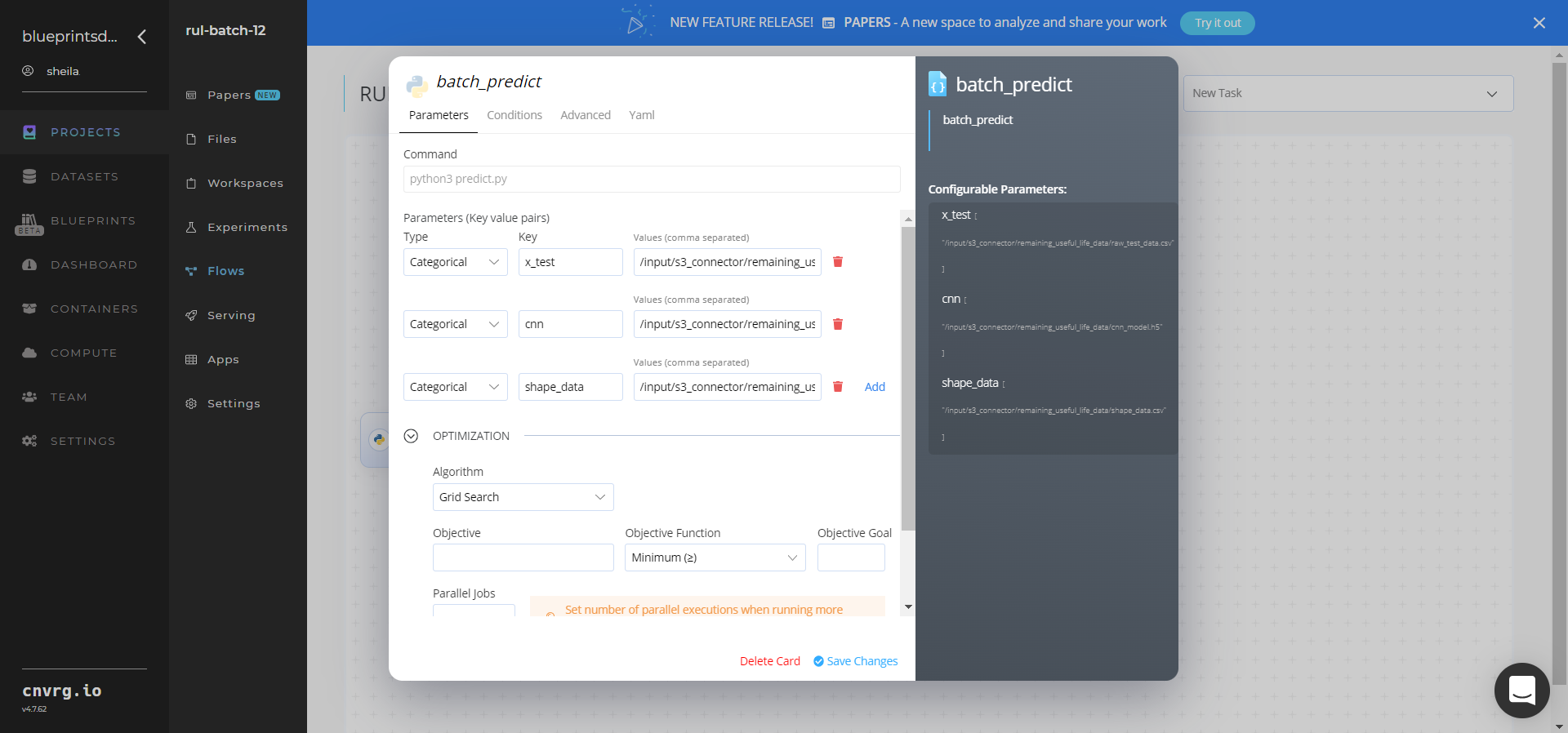
- Key:
--x_test– Value: provide the S3 path to the test dataset in the following format:/input/s3_connector/remaining_useful_life_data/raw_test_data.csv - Key:
--cnn– Value: provide the S3 path to the trained model in the following format:/input/ s3_connector/remaining_useful_life_data/cnn_model.h5 - Key:
--shape_data– Value: provide the S3 path to the shape dataframe in the following format:/input/ s3_connector/remaining_useful_life_data/shape_data.csv
NOTE
You can use the prebuilt data example paths provided.
- Key:
Click the Advanced tab to change resources to run the blueprint, as required.
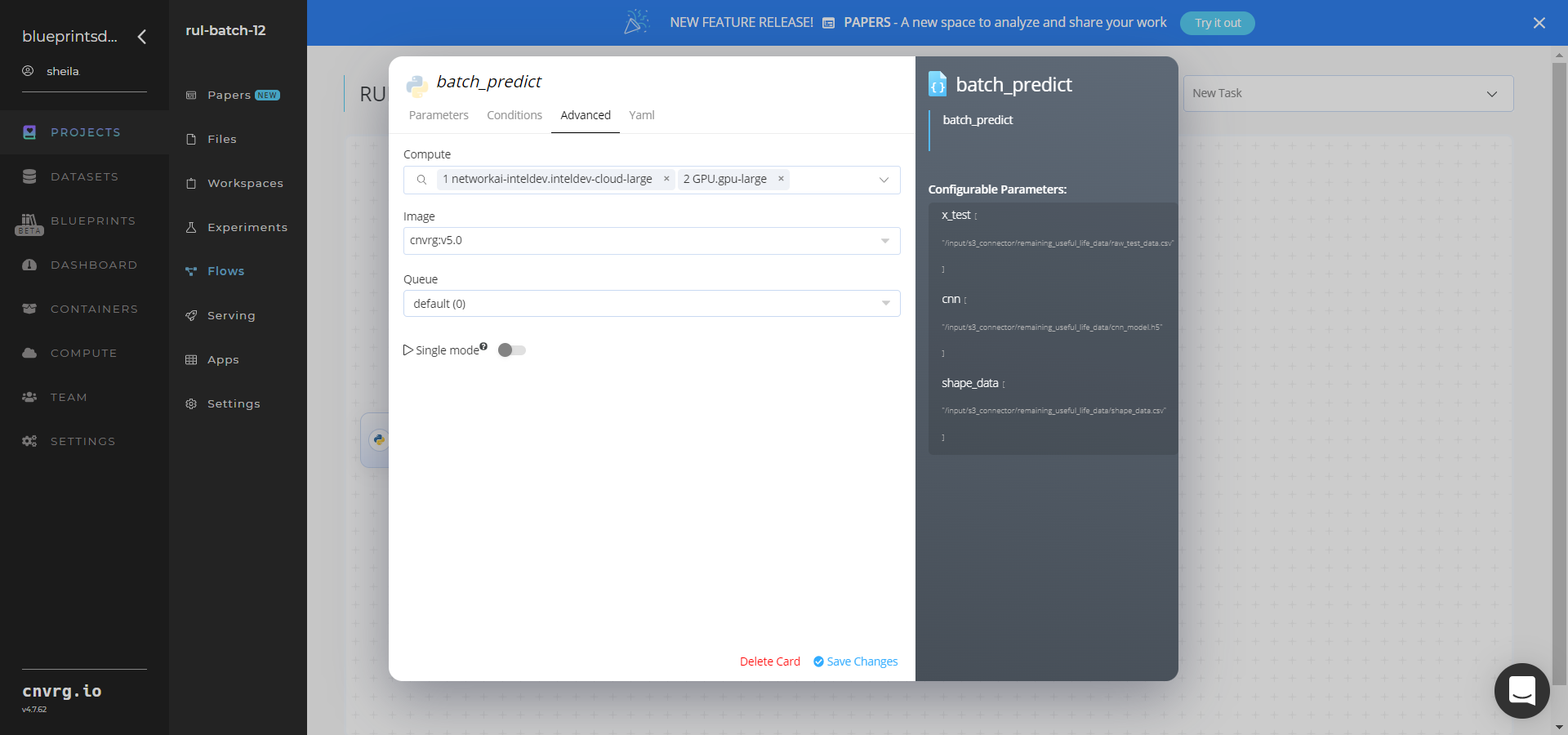
- Click the Run button.
 The cnvrg software deploys a RUL-predictor model that predicts the number of cycles until an asset fails.
The cnvrg software deploys a RUL-predictor model that predicts the number of cycles until an asset fails. - Track the blueprint's real-time progress in its Experiments page, which displays artifacts such as logs, metrics, hyperparameters, and algorithms.
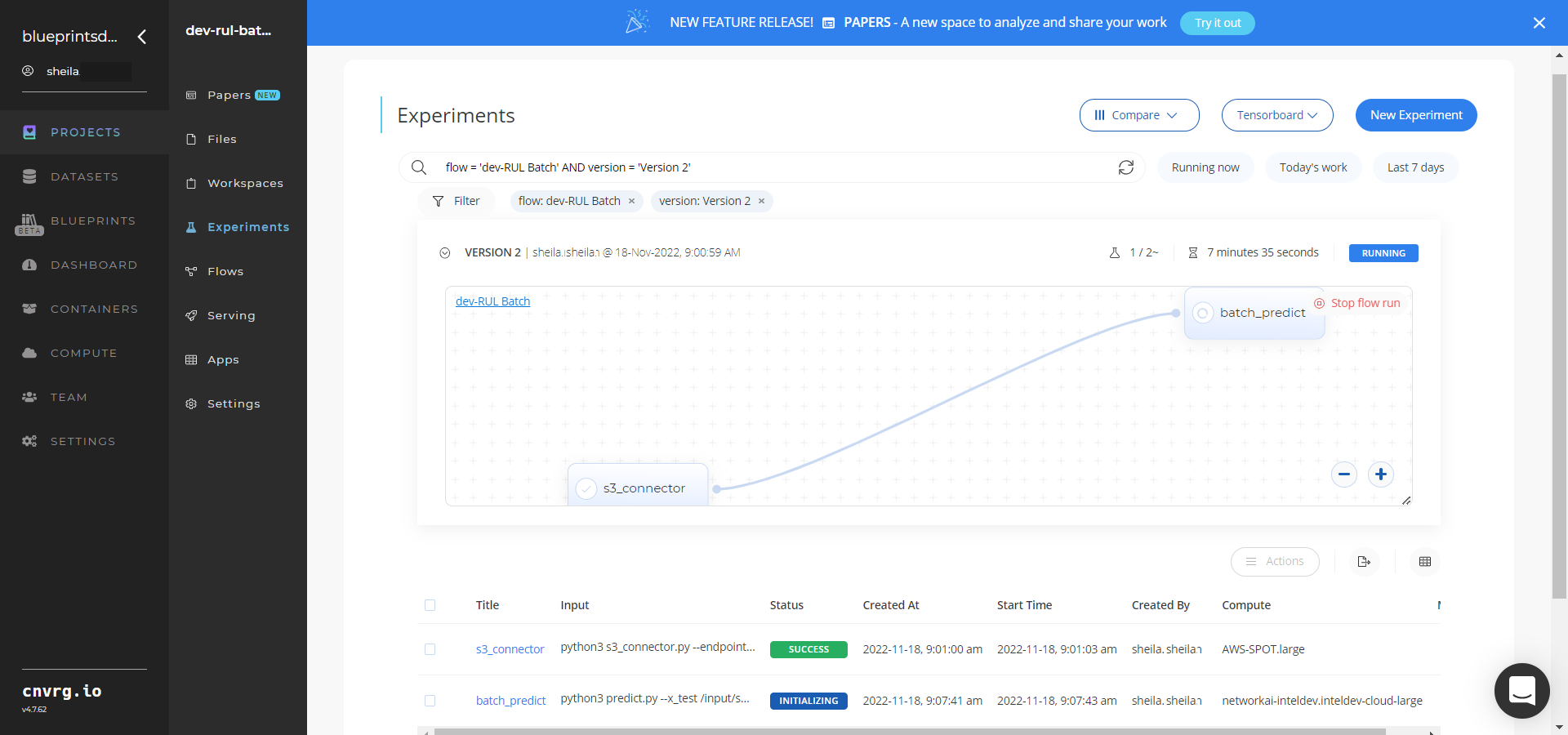
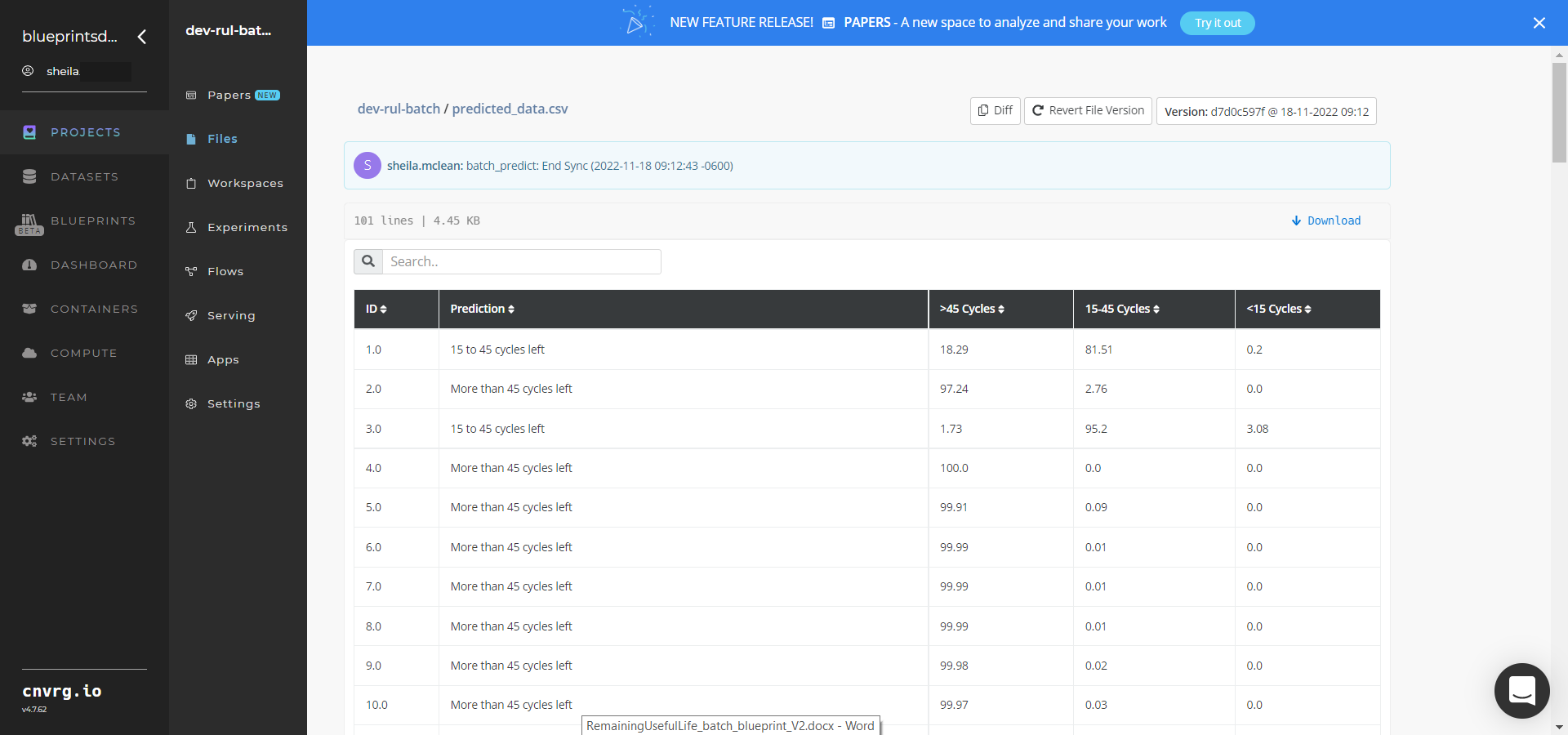
- Select Batch-Predict > Experiments > Artifacts and locate the output CSV file.
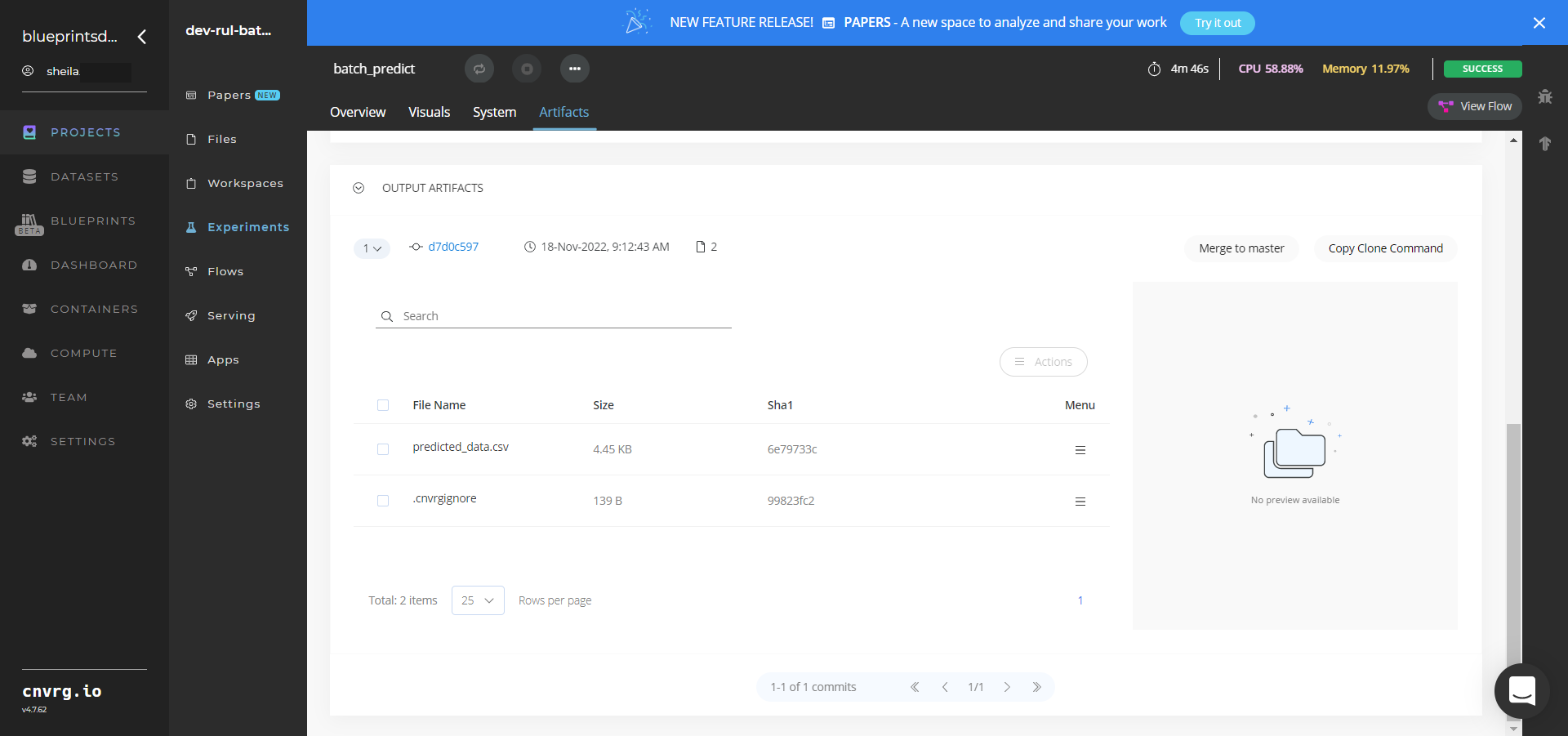
- Select the predicted_data.csv File Name, click the right Menu icon, and select Open File to view the output CSV file.
A custom model that can predict the number of cycles until an asset fails has now been deployed in batch mode. For information on this blueprint's software version and release details, click here.
# Connected Libraries
Refer to the following libraries connected to this blueprint:
# Related Blueprints
Refer to the following blueprints related to this batch blueprint:
- Remaining Useful Life Inference
- Remaining Useful Life Train
- Sensor Forecasting Time-Series Train
- Sensor Forecasting Time-Series Inference
- InfluxDB Anomaly Detection TS Train
- S3 Anomaly Detection TS Train
- Anomaly Detection TS Inference
# Inference
Remaining useful life (RUL) is a time estimate that an asset like equipment or a machine is expected to operate before it requires maintenance, repair, or replacement. Estimating RUL enables companies to schedule maintenance and anticipate repairs so operating efficiency can be optimized and unplanned downtime can be avoided.
# Purpose
Use this inference blueprint to immediately predict when a machine is likely to fail within given cycles using your customized dataset. To use this pretrained RUL-predictor model, create a ready-to-use API-endpoint that can be quickly integrated with your data and application.
This inference blueprint’s model was trained using the Kaggle NASA Turbofan Jet Engine Dataset. To use custom data according to your specific business, run this counterpart’s training blueprint, which trains the model and establishes an endpoint based on the newly trained model.
# Instructions
NOTE
The minimum resource recommendations to run this blueprint are 3.5 CPU and 8 GB RAM.
NOTE
This blueprint’s performance can benefit from using GPU as its compute.
Complete the following steps to deploy an RUL-predictor API endpoint:
- Click the Use Blueprint button.
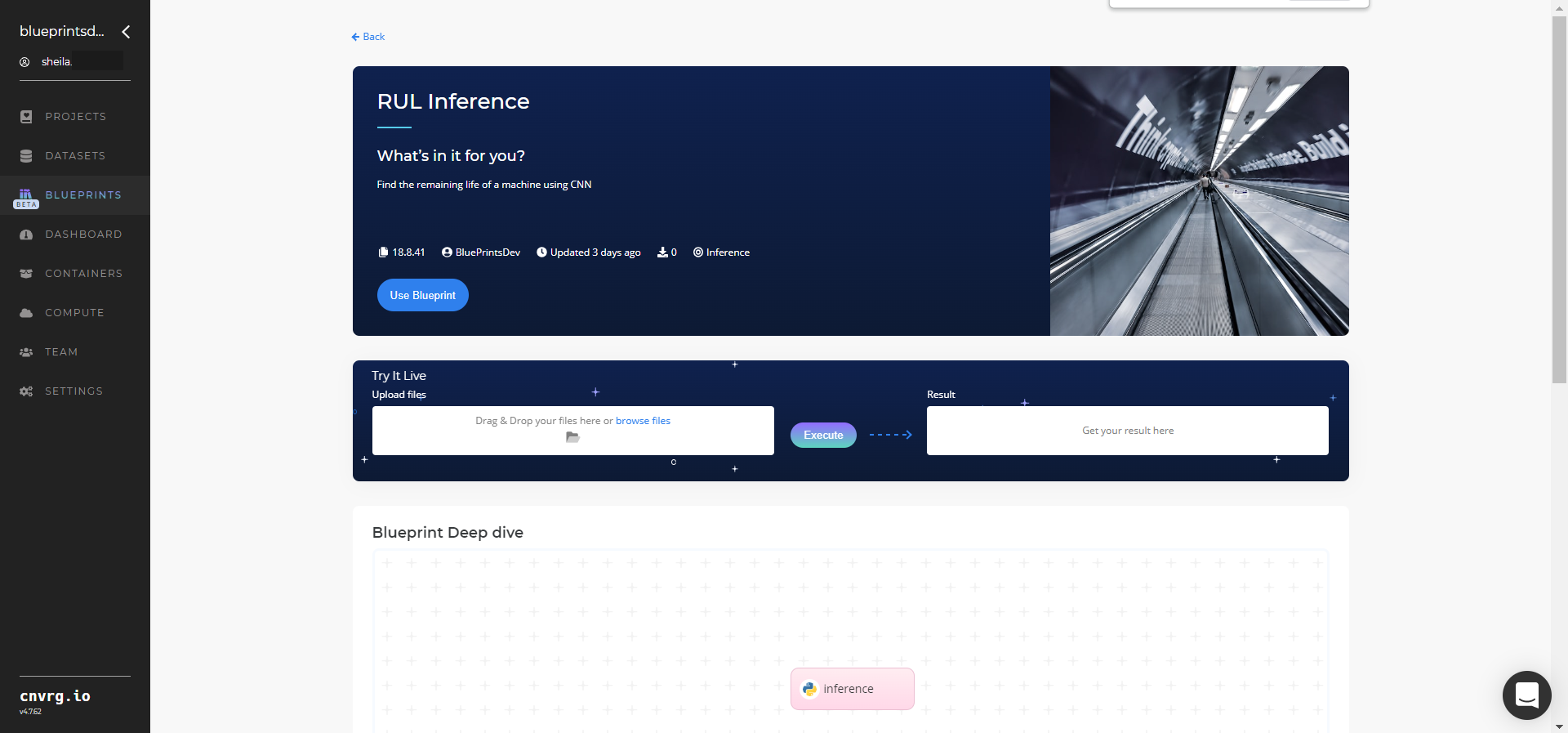
- In the dialog, select the relevant compute to deploy the API endpoint and click the Start button.
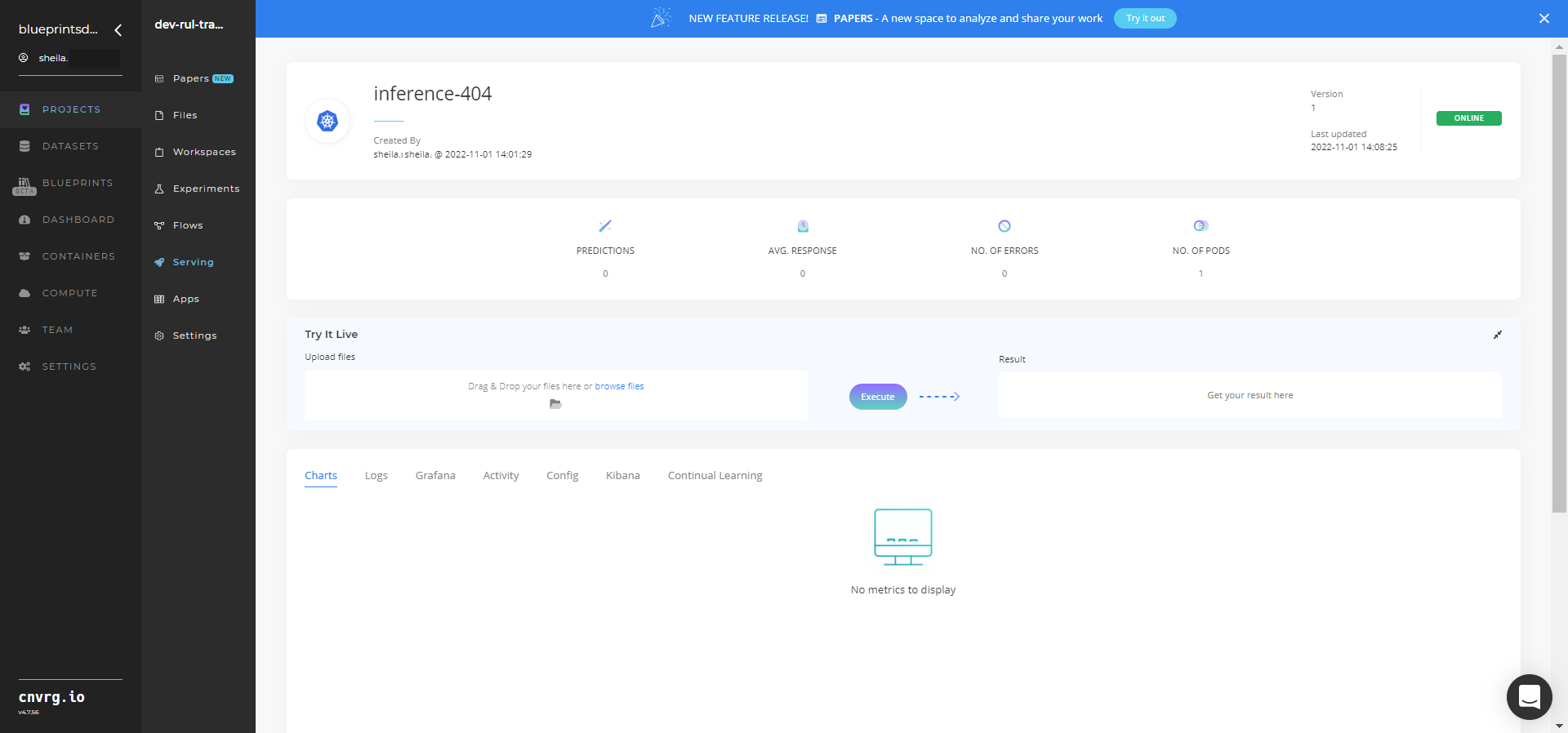
- The cnvrg software redirects to your endpoint. Complete one or both of the following options:
- Use the Try it Live section with any data to check your model's predictions.
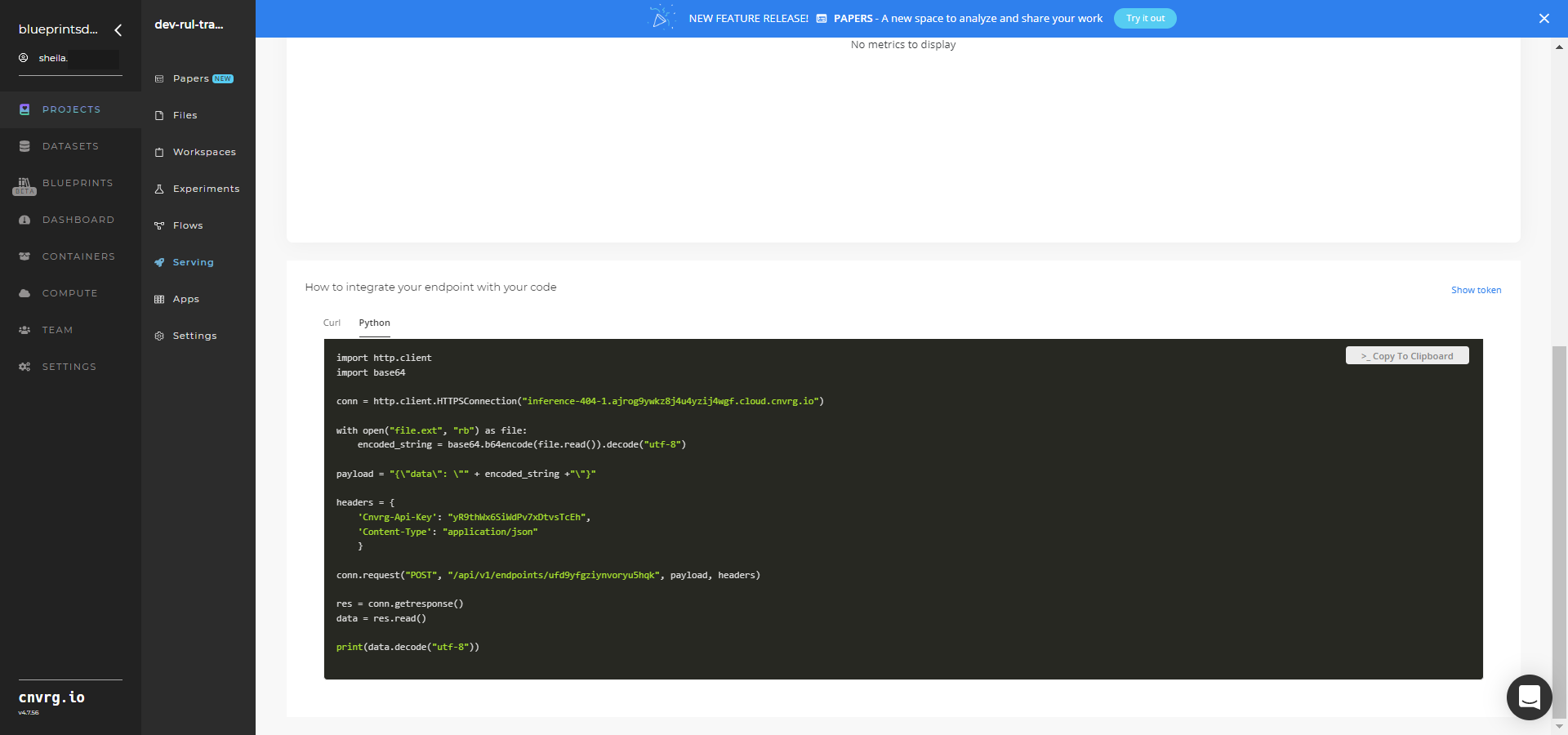
- Use the bottom integration panel to integrate your API with your code by copying in your code snippet.
- Use the Try it Live section with any data to check your model's predictions.
An API endpoint that can predict the number of cycles until a machine or equipment fails has now been deployed. For information on this blueprint's software version and release details, click here.
# Related Blueprints
Refer to the following blueprints related to this inference blueprint:
- Remaining Useful Life Train
- Remaining Useful Life Batch
- Sensor Forecasting Time-Series Train
- Sensor Forecasting Time-Series Inference
- InfluxDB Anomaly Detection TS Train
- S3 Anomaly Detection TS Train
- Anomaly Detection TS Inference
# Training
Remaining useful life (RUL) is a time estimate that an asset like equipment or a machine is expected to operate before it requires maintenance, repair, or replacement. Estimating RUL enables companies to schedule maintenance and anticipate repairs so operating efficiency can be optimized and unplanned downtime can be avoided.
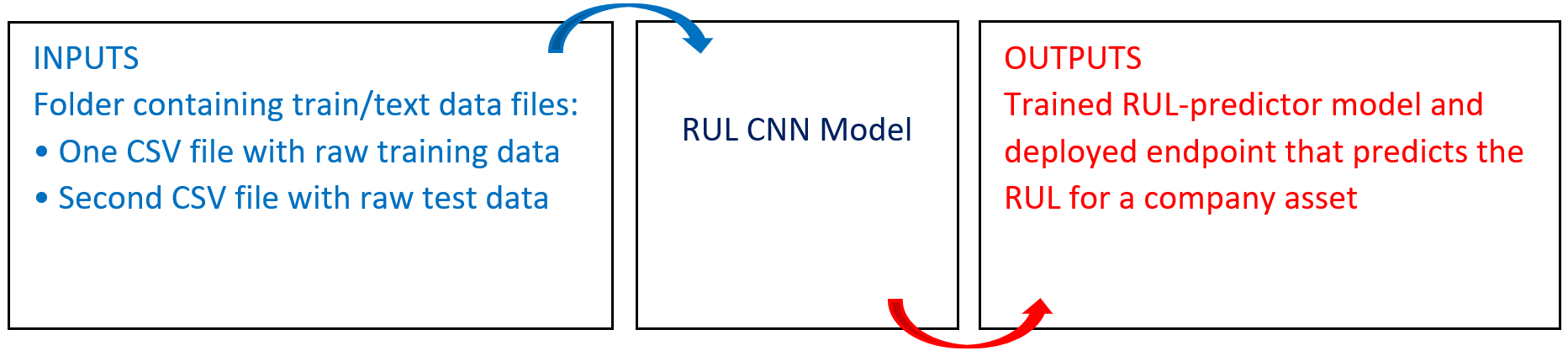
# Overview
The following diagram provides an overview of this blueprint's inputs and outputs.
# Purpose
Use this training blueprint to tailor-train a convolutional neural network (CNN) model with your customized dataset to predict when a company asset is likely to fail within given cycles. To clean and validate the data on which to further train the model, provide one folder in the S3 Connector containing your raw training data. Inputs to further train the CNN model are placed in a remaining_useful_life folder containing the training data raw_train_data.csv file and the test data raw_test_data.csv file on which to make predictions. This blueprint also establishes an endpoint that can be used to predict RUL cycles based on the newly trained model.
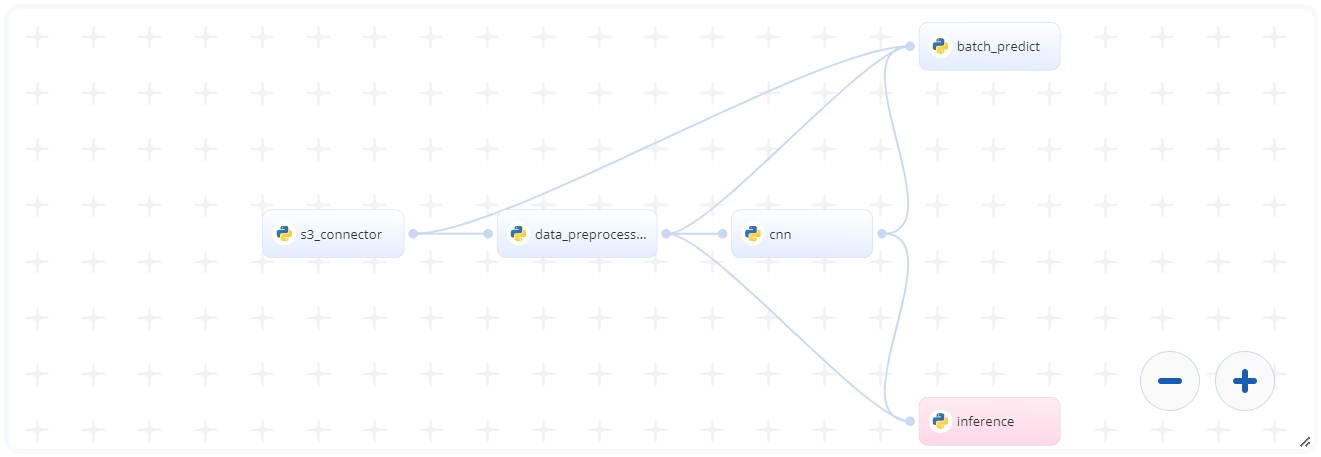
# Deep Dive
The following flow diagram illustrates this blueprint's pipeline:
# Flow
The following list provides a high-level flow of this blueprint’s run:
- In the S3 Connector, provide the data bucket name and directory path to the training data CSV file
- In the Data Preprocessing task, provide the path to the training data CSV file including the S3 Connector prefix
- In the CNN (Train) task, provide the Data Preprocessing paths to the preprocessed training and test CSV files
- In the Batch Predict task, provide the Data Preprocessing and CNN paths to the test dataset and the trained model, respectively
# Arguments/Artifacts
For more information on this blueprint’s tasks, its inputs, and outputs, click here.
# Data Preprocessing Inputs
--raw_train_datais user-uploaded raw training data.--common_letter_numericis the name of the ID column the user provides. It is a common letter if all the sensors or settings start from the same letter, such as setting1,setting2,sensor1,sendor2,sensor3, and so on. Default:s. NOTE: Thiscommon_letter_numericparameter isn’t a requirement for the code. If users choose not to provide this, they can remove the defaultsand eliminate this parameter.--label_encoding_colsis a list of columns the user label encodes.--scaleris the common letter in all numeric variables.--numeric_featuresis list of numeric features in the data to be scaled or labeled. Default:sensor.--meta_columnsare columns other than the numeric features such as ID and cycle. Default:id,cycle.--sequence_lengthis the length of a sequence. To maximize the amount of data to train, the series is split with a fixed window and a sliding step. For example, if engine1 has 192 train cycles with a 50 window length, the blueprint extracts 142 time-series with length 50. The length of this window is the sequence length. Default:50.--upper_limitis the upper limit of cycles. Default:25.--lower_limitis the lower limit of cycles. Default:25.
# Data Preprocessing Outputs
--x_trainis a 2-D array for x-train data.--y_trainis a 2-D array for y-train data.--shape_datais the name of the file which contains the custom-trained CNN model.
# CNN Train Inputs
--x_trainis preprocessed training data in 2-D array format.--y_trainis preprocessed test data in 2-D array format.--batch_sizeis used to train the CNN model. Default:512.--epochsis the number of epochs used to train the CNN model. Default:25.--seedis the method used to initialize the random number generator in the CNN model.--shape_datais a dataframe containing multiple variables to batch predict from data preprocessing block.
# CNN Train Outputs
--cnn_model.h5is the name of the file containing multiple variables to be used in batch predict.
# Batch-Predict Inputs
--x_testis the user-provided raw test dataset.--cnnis the pretrained 2-D CNN model.--shape_datais a dataframe containing multiple variables to batch predict from data preprocessing block.
# Batch-Predict Outputs
--output.csvis the name of the file containing the predictions for each individual ID or machine.
# Instructions
NOTE
The minimum resource recommendations to run this blueprint are 3.5 CPU and 8 GB RAM.
NOTE
This blueprint’s performance can benefit from using GPU as its compute.
Complete the following steps to train a RUL-predictor model:
Click the Use Blueprint button. The cnvrg Blueprint Flow page displays.
In the flow, click the S3 Connector task to display its dialog.
- Within the Parameters tab, provide the following Key-Value pair information:
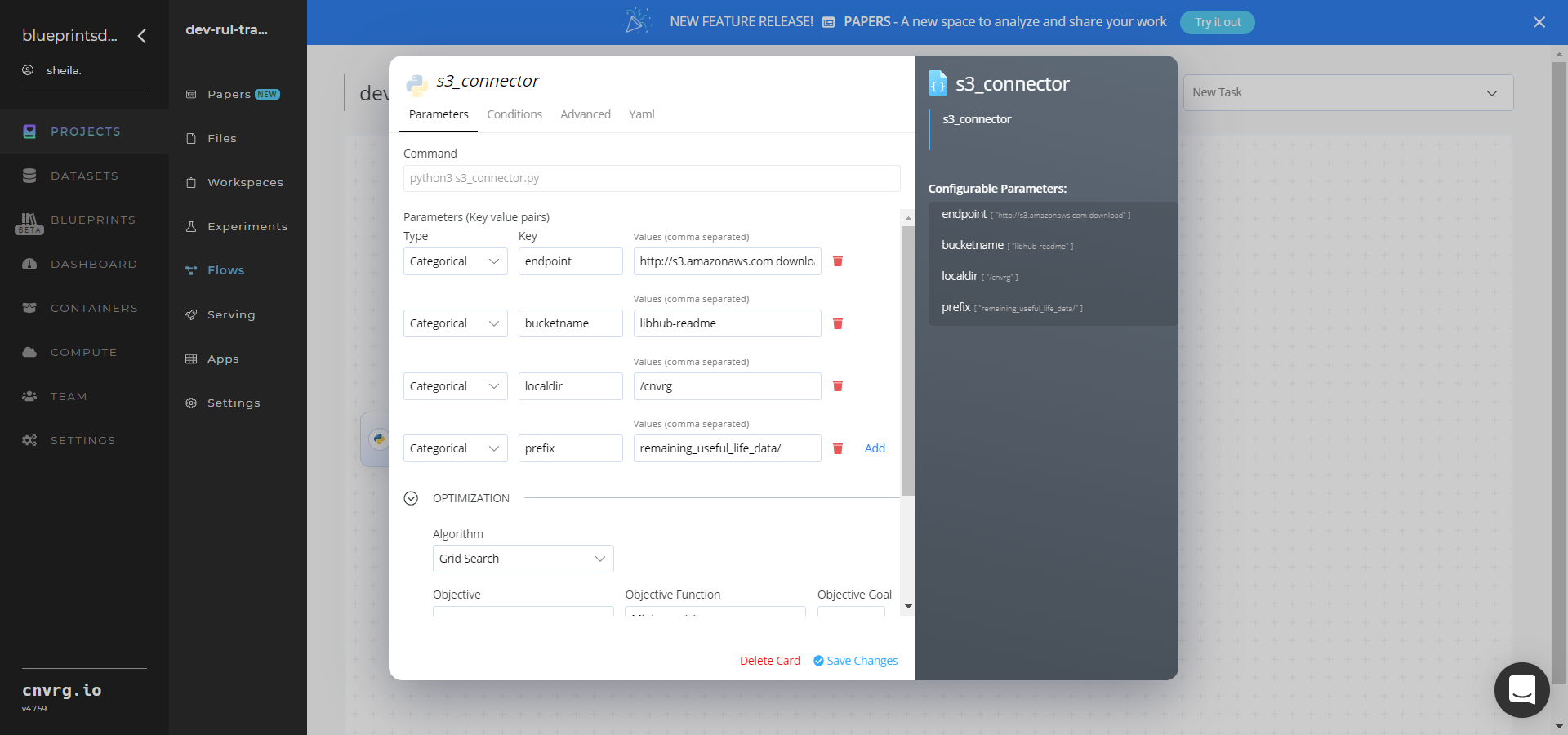
- Key:
bucketname- Value: enter the data bucket name - Key:
prefix- Value: provide the main path to the CVS file folder
- Key:
- Click the Advanced tab to change resources to run the blueprint, as required.
- Within the Parameters tab, provide the following Key-Value pair information:
Return to the flow and click the Data Preprocessing task to display its dialog.
Within the Parameters tab, provide the following Key-Value pair information:
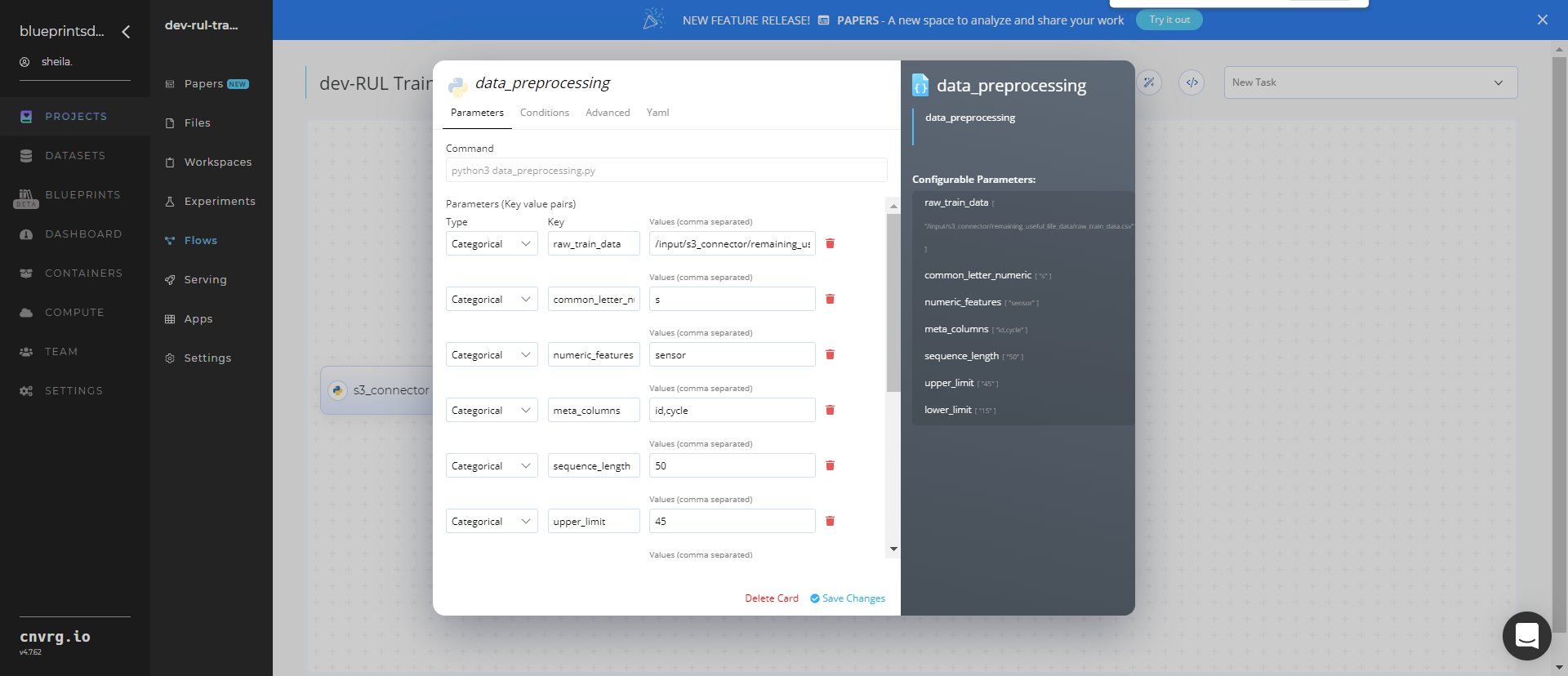
- Key:
--raw_train_data– Value: provide the path to the S3 location with the training data in the following format:/input/s3_connector/remaining_useful_life_data/raw_train_data.csv - Key:
--common_letter_numeric– Value: provide the name of the ID column - Key:
--numeric_features– Value: list the numeric features in the data to be scaled or labeled - Key:
--meta_columns– Value: identify columns other than the numeric features such as ID and cycle - Key:
--sequence_length– Value: enter the length of the sequence - Key:
--upper_limit– Value: provide the upper limit of cycles - Key:
--lower_limit– Value: provide the lower limit of cycles
NOTE
You can use the prebuilt example data paths provided.
- Key:
Click the Advanced tab to change resources to run the blueprint, as required.
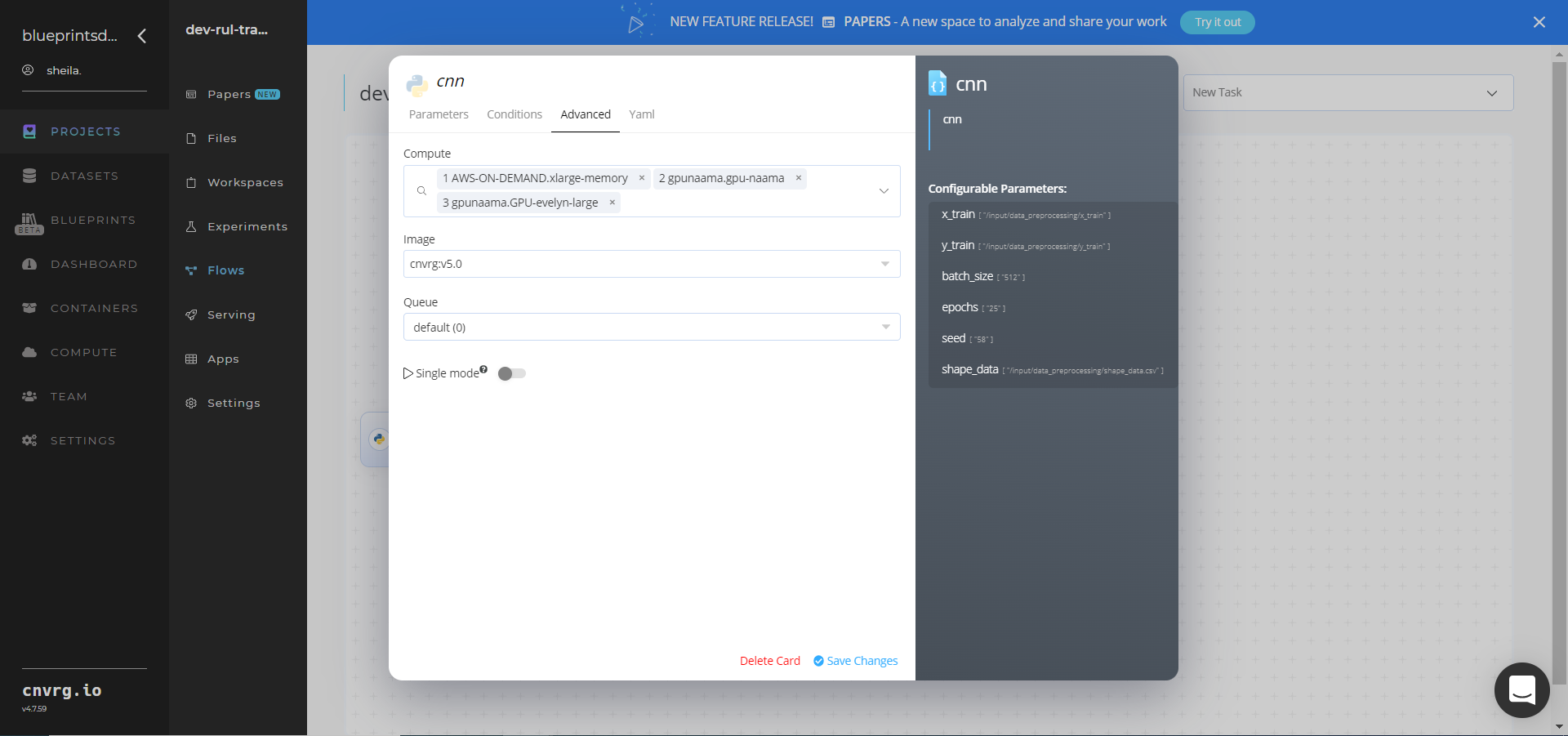
Return to the flow and click the CNN (Train) task to display its dialog.
- Within the Parameters tab, provide the following Key-Value pair information:
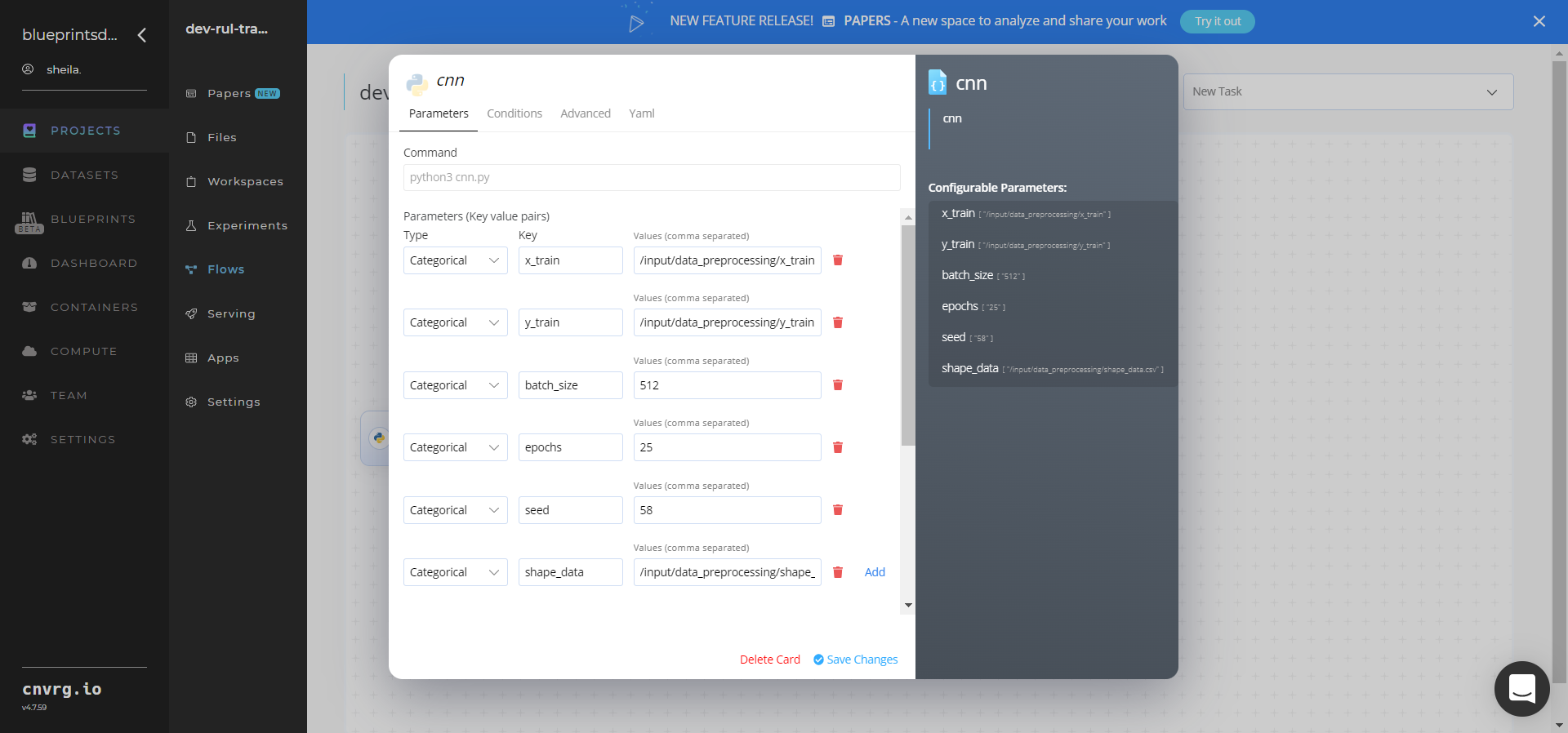
- Key:
--x_train– Value: provide the path to the preprocessed training data in the following format:/input/data_preprocessing/x_train - Key:
--y_train– Value: provide the path to preprocessed test data in the following format:/input/data_preprocessing/y_train - Key:
--batch_size– Value: provide the batch size to train the CNN model - Key: -
-epochs– Value: provide the path the number of epochs to train the CNN model - Key:
--seed– Value: provide the value to initialize the random number generator in the CNN model - Key:
--shape_data– Value: provide the dataframe containing multiple variables to batch predict from data preprocessing block.
NOTE
You can use the prebuilt example data paths provided.
- Key:
- Click the Advanced tab to change resources to run the blueprint, as required.
- Within the Parameters tab, provide the following Key-Value pair information:
Return to the flow and click the Batch Predict task to display its dialog.
- Within the Parameters tab, provide the following Key-Value pair information:
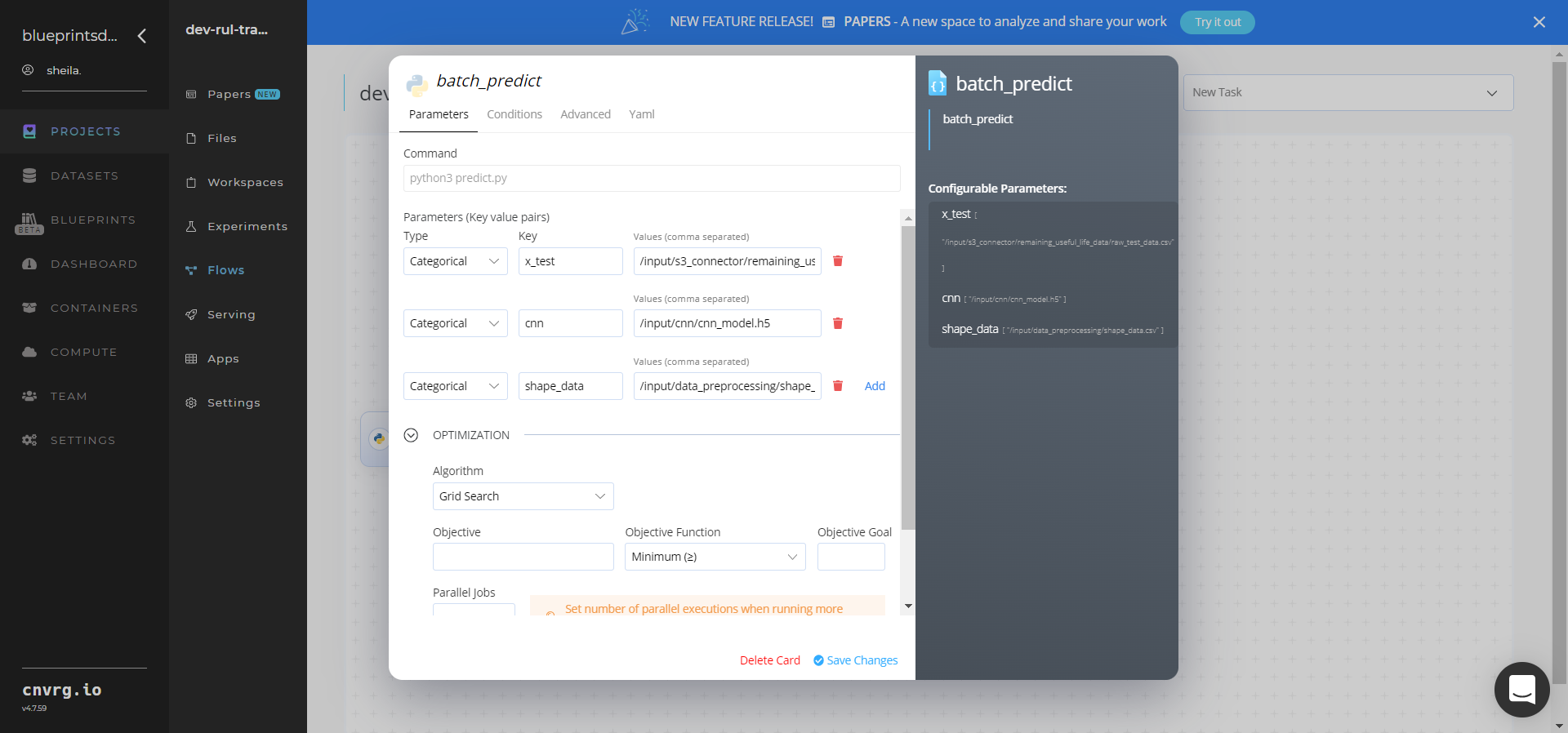
- Key:
--x_test– Value: provide the path to the test dataset in the following format:/input/s3_connector/remaining_useful_life_data/raw_test_data.csv - Key:
--cnn– Value: provide the path to trained model in the following format:/input/cnn/cnn_model.h5 - Key:
--shape_data– Value: provide the shape dataframe path in the following format:/input/data_preprocessing/shape_data.csv
- Key:
- Click the Advanced tab to change resources to run the blueprint, as required.
- Within the Parameters tab, provide the following Key-Value pair information:
Click the Run button.
 The cnvrg software launches the training blueprint as set of experiments, generating a trained RUL-predictor model and deploying it as a new API endpoint.
The cnvrg software launches the training blueprint as set of experiments, generating a trained RUL-predictor model and deploying it as a new API endpoint.NOTE
The time required for model training and endpoint deployment depends on the size of the training data, compute resources, and training parameters.
For more information on cnvrg endpoint deployment capability, see cnvrg Serving.
Track the blueprint's real-time progress in its Experiments page, which displays artifacts such as logs, metrics, hyperparameters, and algorithms.
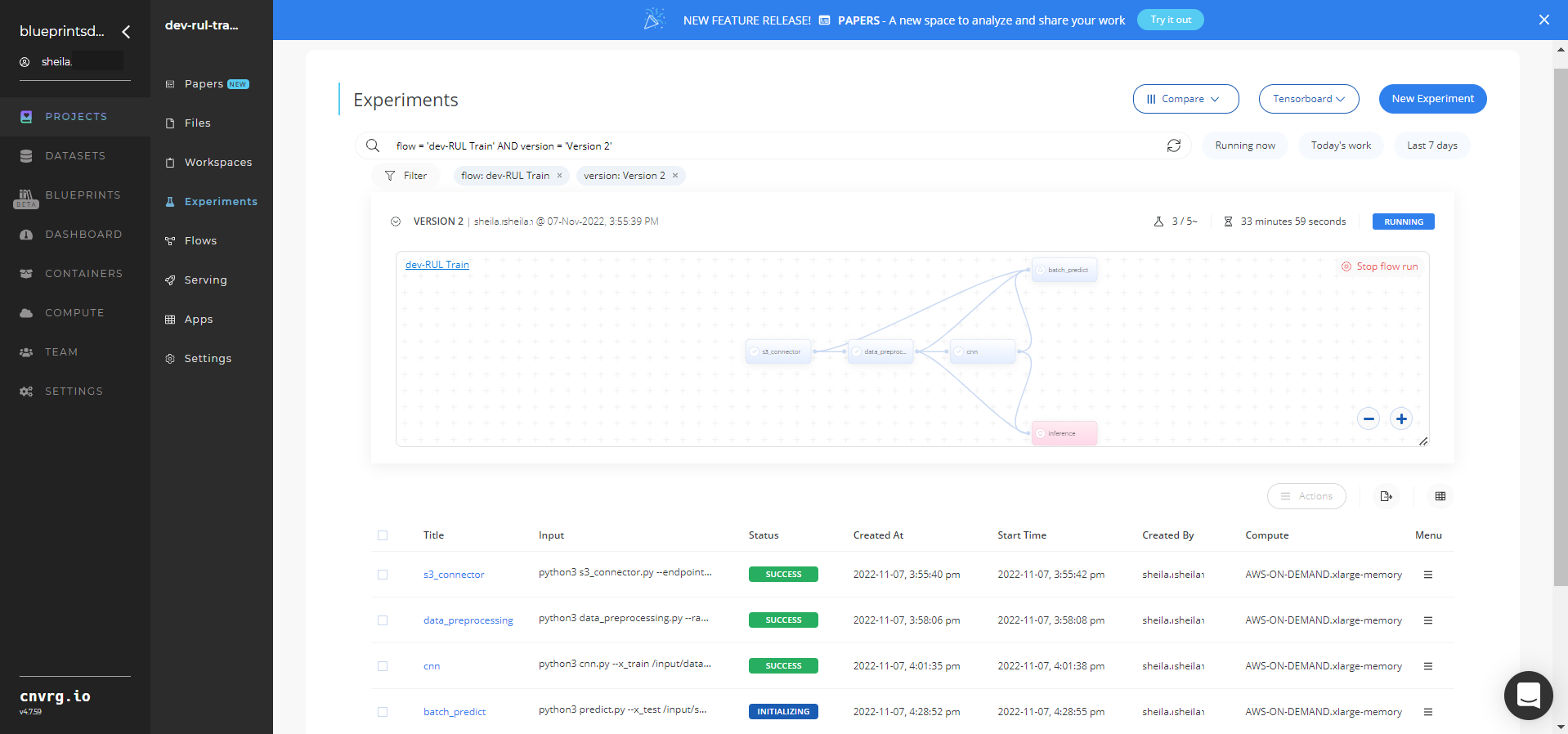
Click the Serving tab in the project and locate your endpoint.
Complete one or both of the following options:
- Use the Try it Live section with any data to check the model's predictions.
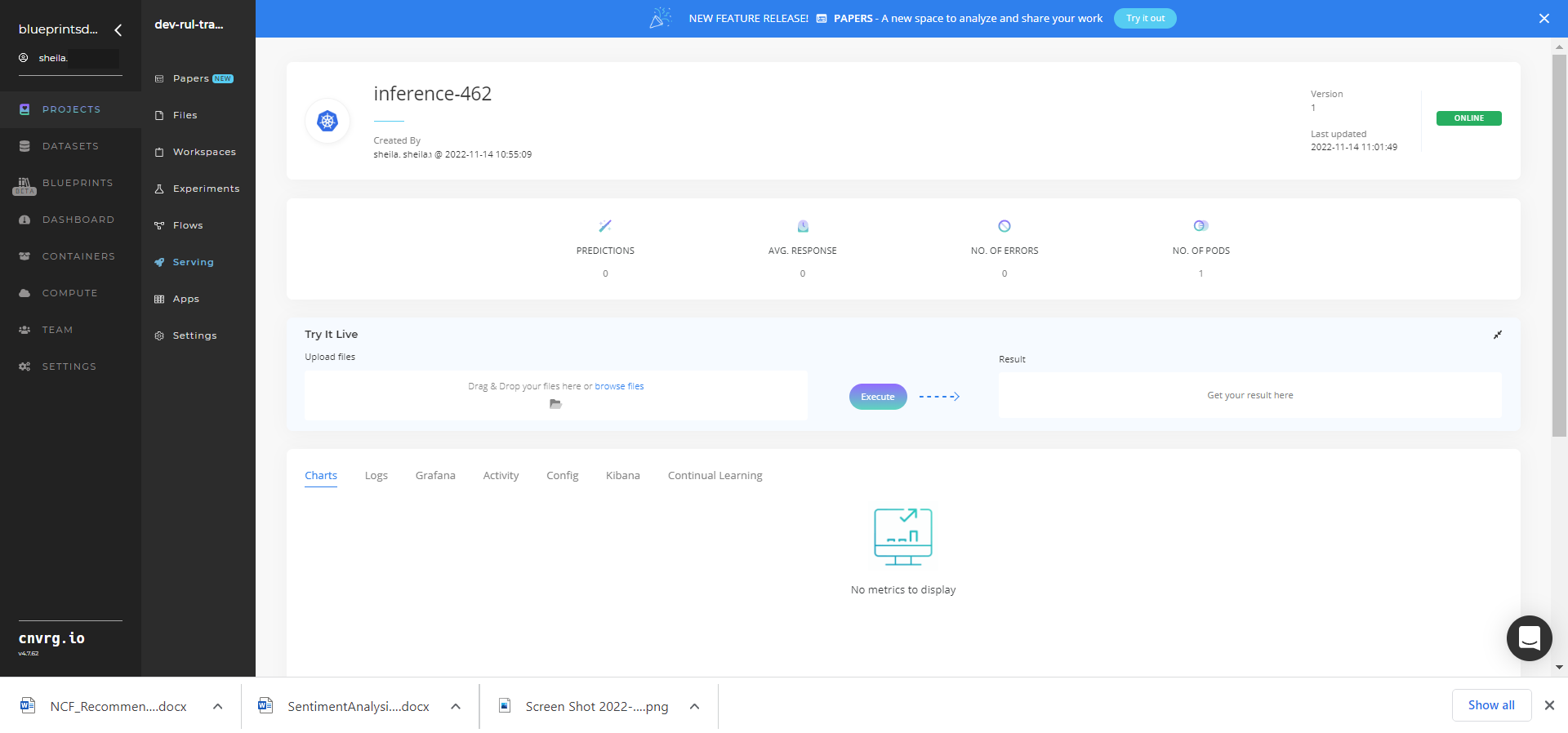
- Use the bottom integration panel to integrate your API with your code by copying in your code snippet.
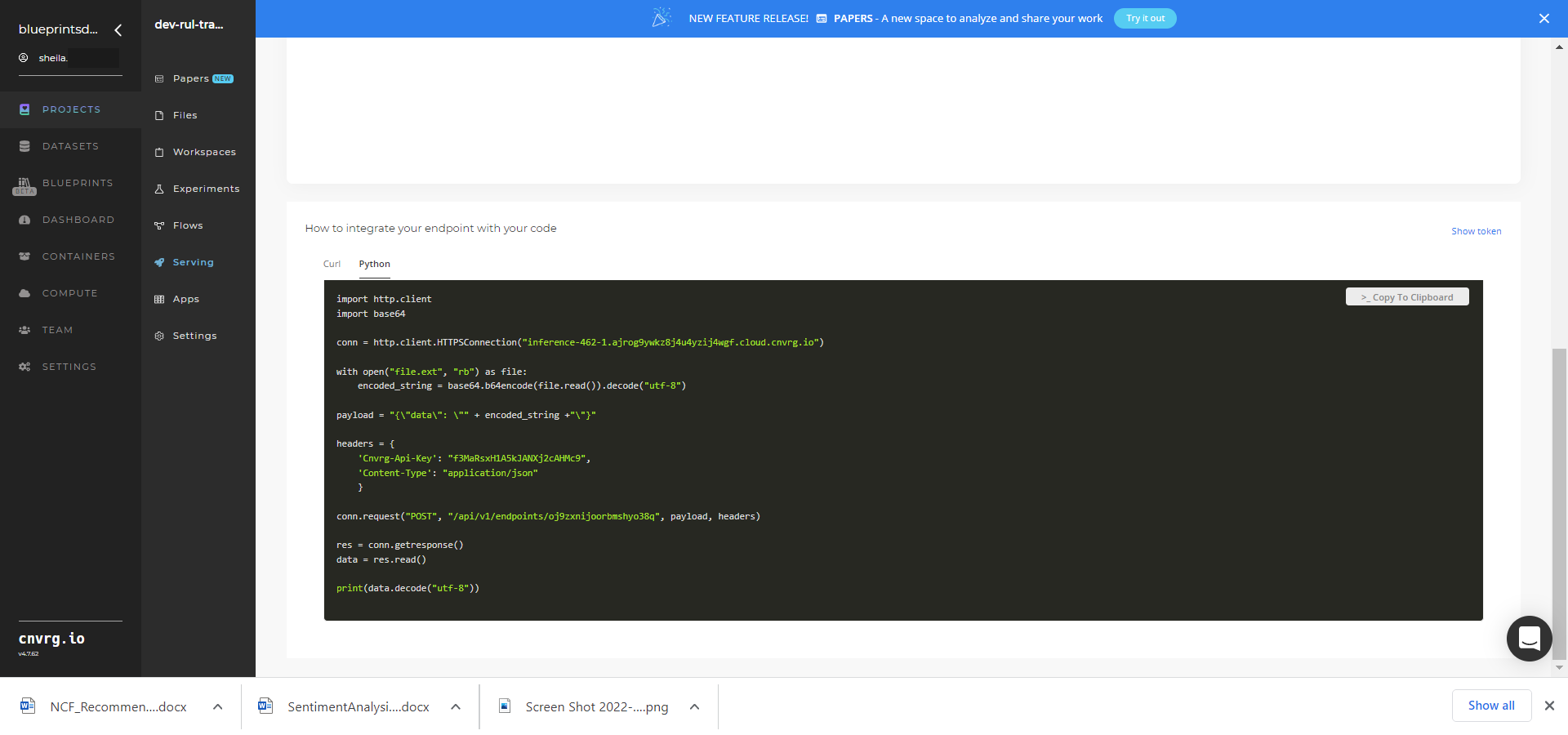
- Use the Try it Live section with any data to check the model's predictions.
A custom model and API endpoint, which can predict the number of cycles until an asset fails, have now been trained and deployed. If also using the Batch Predict task, a trained RUL-predictor model that makes batch predictions has now been deployed. For information on this blueprint's software version and release details, click here.
# Connected Libraries
Refer to the following libraries connected to this blueprint:
# Related Blueprints
Refer to the following blueprints related to this training blueprint: