# Sentiment Analysis BERT AI Blueprint - deprecated from 11/2024
# Inference
Sentiment analysis is used to classify text and determine the sentiment or opinion of a customer’s message. A sentiment analysis model can predict whether a person’s text data is positive, negative, or neutral by extracting meaning and assigning a numerical score designating a sentiment.
# Purpose
Use this inference blueprint to immediately analyze sentiment in text. To use this fine-tuned BERT sentiment-analysis model, create a ready-to-use API-endpoint that can be quickly integrated with your data and application to make predictions on new text.
This inference blueprint’s model was fine-tuned on a Twitter dataset. To use custom data according to your specific business, run this counterpart’s training blueprint, which trains the model and establishes a batch prediction based on the newly trained model.
# Instructions
NOTE
The minimum resource recommendations to run this blueprint are 3.5 CPU and 8 GB RAM.
Complete the following steps to deploy a BERT sentiment-analysis API endpoint:
- Click the Use Blueprint button. The cnvrg Blueprint Flow page displays.
- In the dialog, select the relevant compute to deploy the API endpoint and click the Start button.
- The cnvrg software redirects to your endpoint. Complete one or both of the following options:
- Use the Try it Live section with any text to check the model.
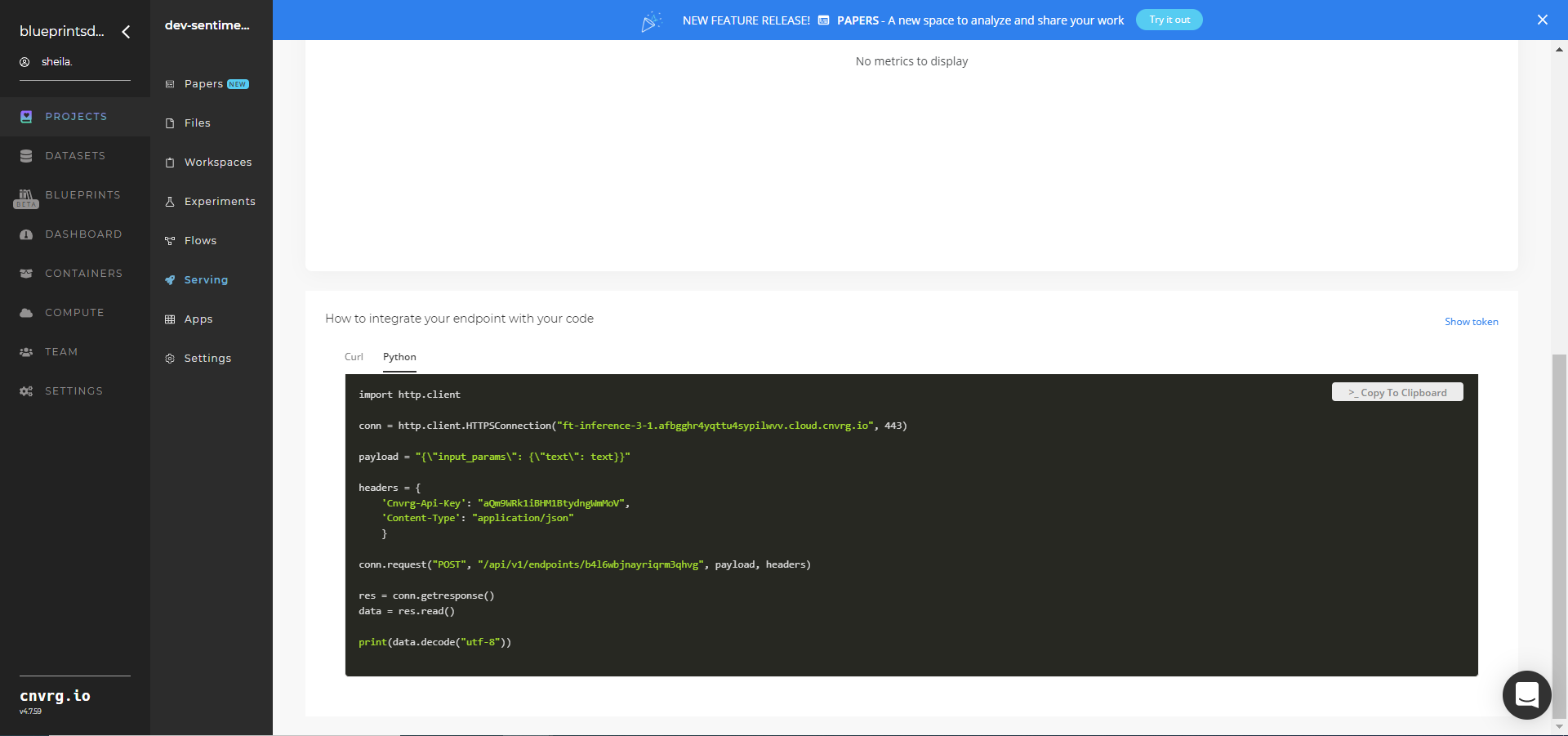
- Use the bottom integration panel to integrate your API with your code by copying in your code snippet.
- Use the Try it Live section with any text to check the model.
An API endpoint that analyzes sentiment in text has now been deployed. For information on this blueprint’s software version and release details, click here.
# Related Blueprints
The following blueprints are related to this inference blueprint:
- BERT Sentiment Analysis Train
- BERT Twitter Sentiment Analysis Batch
- Sentiment Analysis Train
- Sentiment Analysis Inference
# Training
Sentiment analysis is used to classify text and determine the sentiment or opinion of a customer’s message. A sentiment-analysis model can predict whether a person’s text data is positive, negative, or neutral by extracting meaning and assigning a numerical score designating a sentiment. Train and fine-tune (FT) this BERT model using a set of labeled text to make predictions on new text.
# Overview
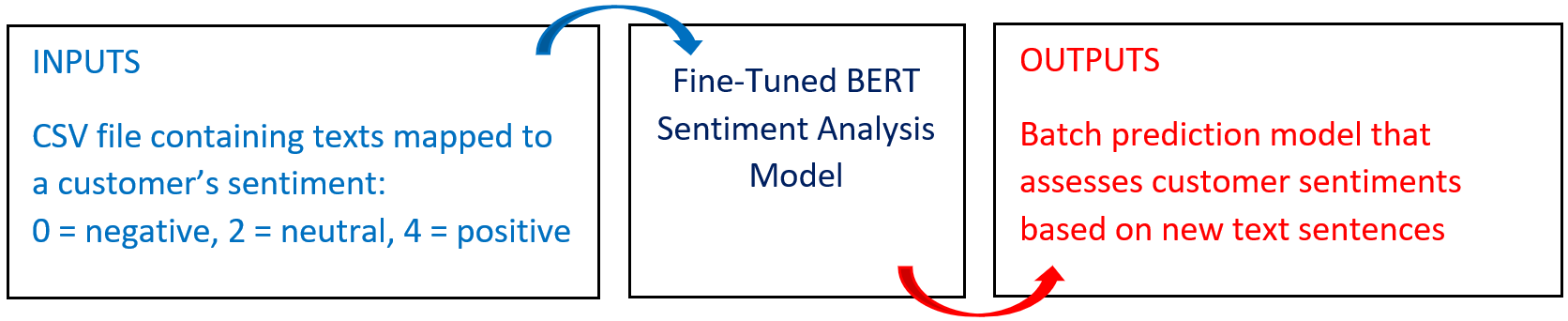
The following diagram provides an overview of this blueprint’s inputs and outputs.
# Purpose
Use this training blueprint to fine-tune a pretrained BERT model for use in sentiment analysis. The fine-tuned model can then be used with custom data to analyze textual data and predict sentiments.
This blueprint fine-tunes a pretrained BERT model on user-supplied data and produces a sentiment-analyzer model. To train this model, provide a CSV-formatted dataset that includes comments, consisting of one target column (0: Negative, 2: Neutral, 4: Positive) and five feature columns: timestamp, datetime, query, user, and text, the latter text of which is mandatory. By default, the blueprint requires one input_filename path to a local file. This blueprint also makes batch predictions that analyze sentiment in text based on the newly fine-tuned model.
# Deep Dive
The following flow diagram illustrates this blueprint’s pipeline:
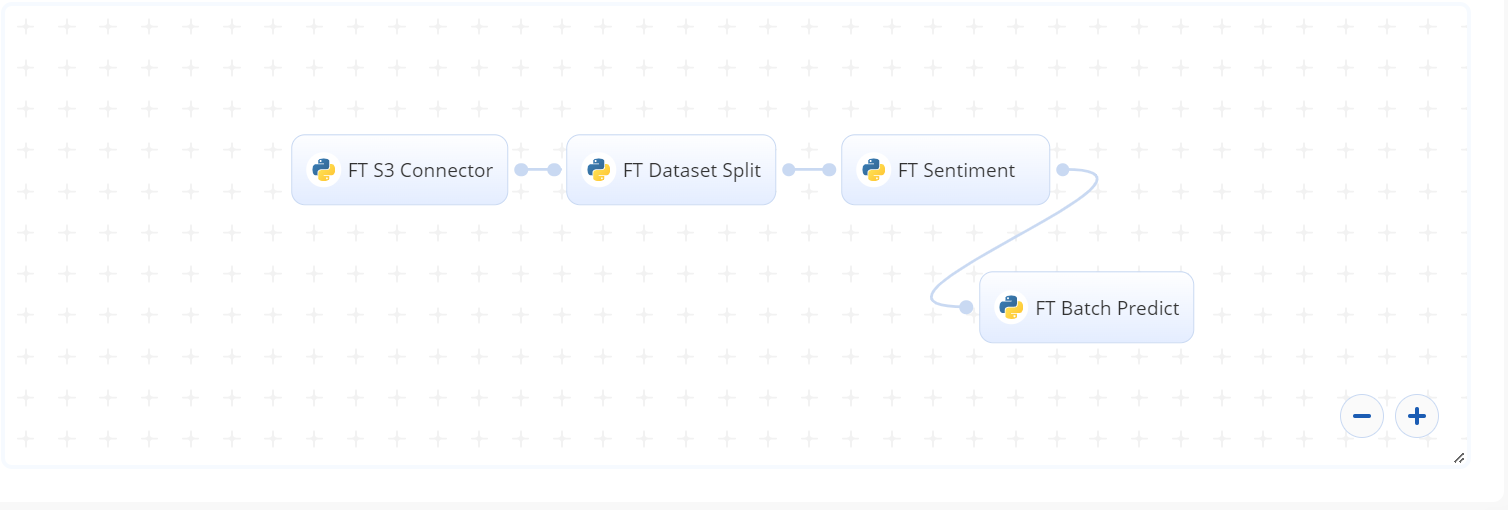
# Flow
The following list provides a high-level flow of this blueprint’s run:
- In the FT S3 Connector, the user provides the name and path to the input dataset.
- In the FT Dataset Split task, the user provides the path and valid size of the percentage of the original dataset.
- In the FT Sentiment (Train) task, the user provides the paths for the
input_filenameand theoutput_model_pathas well as thetext_columnandlabel_columnnames for dataframe. The user also provides hyperparameters fornum_train_epochs,max_length,batch_size_train, andbatch_size_val. - In the FT Batch Predict task, the user provides the paths to the train/validation data and the trained sentiment-analysis model.
- The blueprint fine-tunes the model and makes batch predictions that analyze customer sentiments.
# Arguments/Artifacts
For more information on this blueprint’s tasks, its inputs, and outputs, click here.
# Inputs
--input_filename(string, required) is the path to a local labeled data file containing the data to be used for training and validation.--output_model_path(string) is the path to save the model/checkpoint/events. Default:output.--text_column(string) is the name of dataframe text column. Default:text.--label_column(string) is the name of dataframe label column. Default:target.--num_train_epochs- (int) are the number of epochs the algorithm performs while training. Default:1.--batch_size_train- (int) are the number of texts the model goes over in each epoch. Default:256.--batch_size_val- (int) are the number of texts the model evaluates in each epoch. Default:256.
# Outputs
--prediction_resultis the name of the CSV file where the sentiment prediction results are saved.
# Blueprint Devices
Refer to the following compute device guidelines:
- If using CPU for fine-tuning, it uses less than 32GB memory.
- If using GPU for fine-tuning, it uses at least 16GB memory for BERT-Large models and hyperparameters for
max_sequenceandbatch_size, as shown in the following table: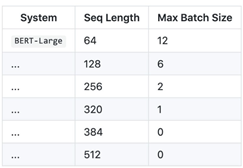
# Instructions
NOTE
The minimum resource recommendations to run this blueprint are 3.5 CPU and 8 GB RAM.
NOTE
This blueprint’s performance can benefit from using GPU as its compute.
Complete the following steps to fine-tune this BERT sentiment-analysis model:
Click the Use Blueprint button. The cnvrg Blueprint Flow page displays.
Click the FT S3 Connector task to display its dialog.
- Within the Parameters tab, provide the following Key-Value pair information:
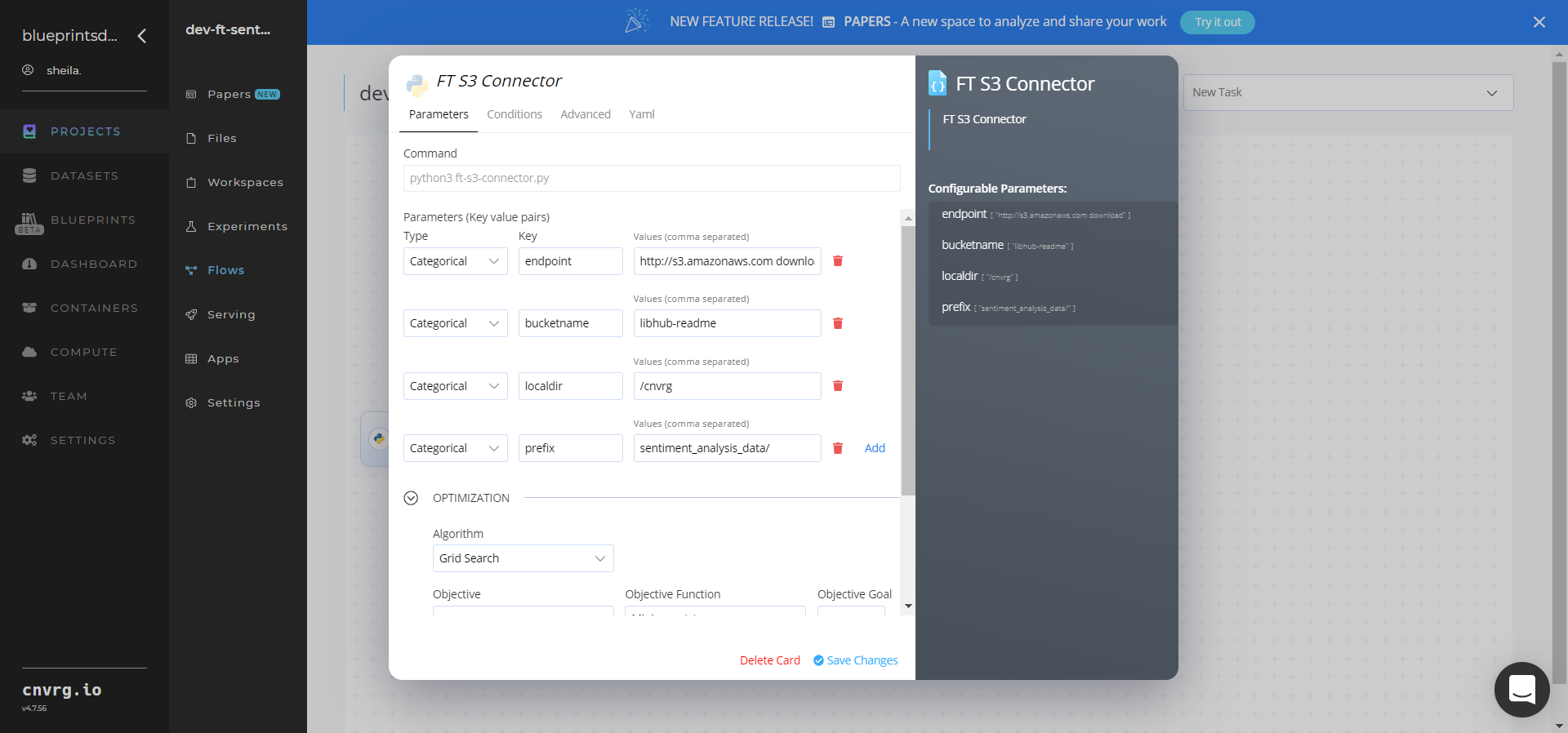
- Key:
bucketname− Value: provide the data bucket name - Key:
prefix− Value: provide the main path to the input dataset
- Key:
- Click the Advanced tab to change resources to run the blueprint, as required.
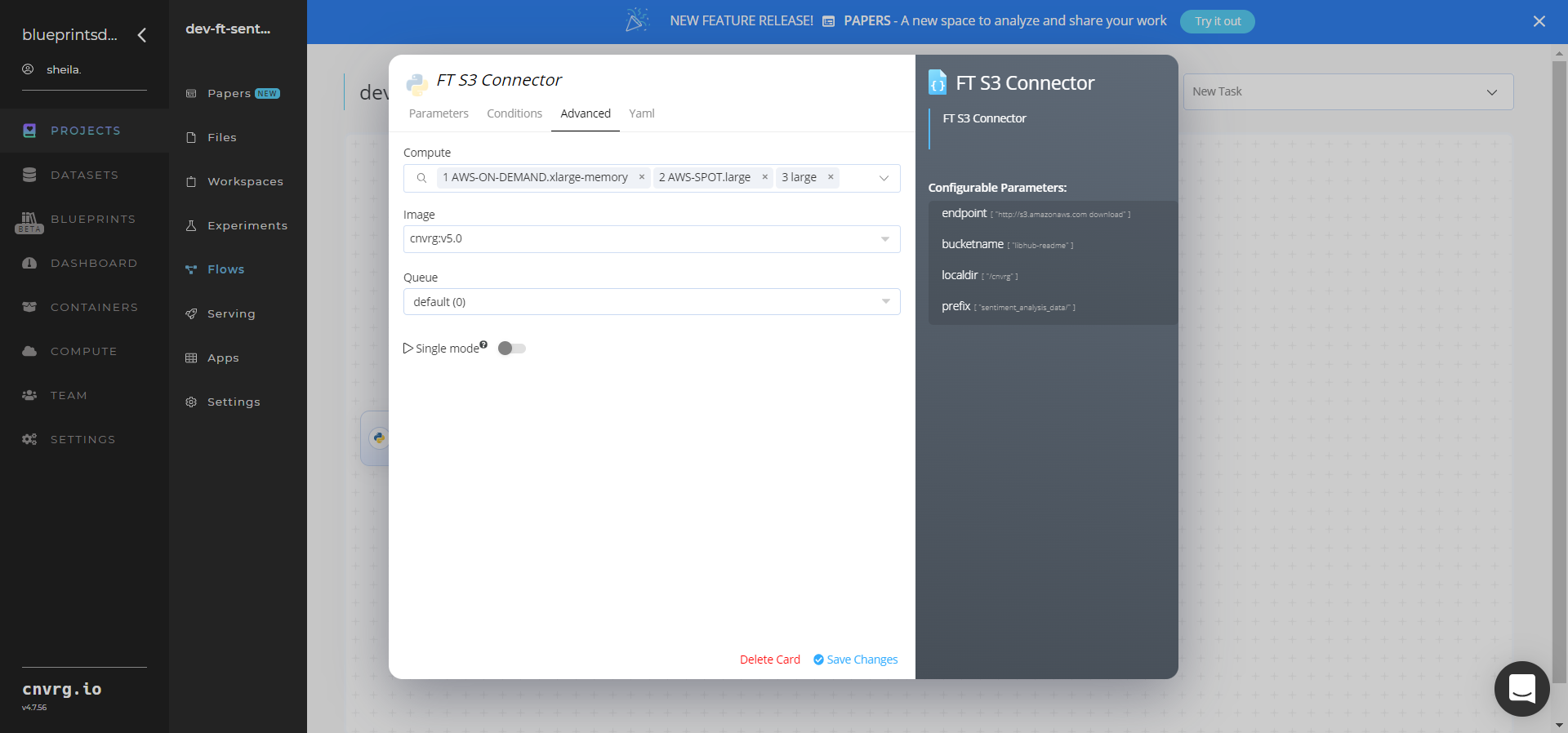
- Within the Parameters tab, provide the following Key-Value pair information:
Click the FT Dataset Split task to display its dialog.
Within the Parameters tab, provide the following Key-Value pair information:
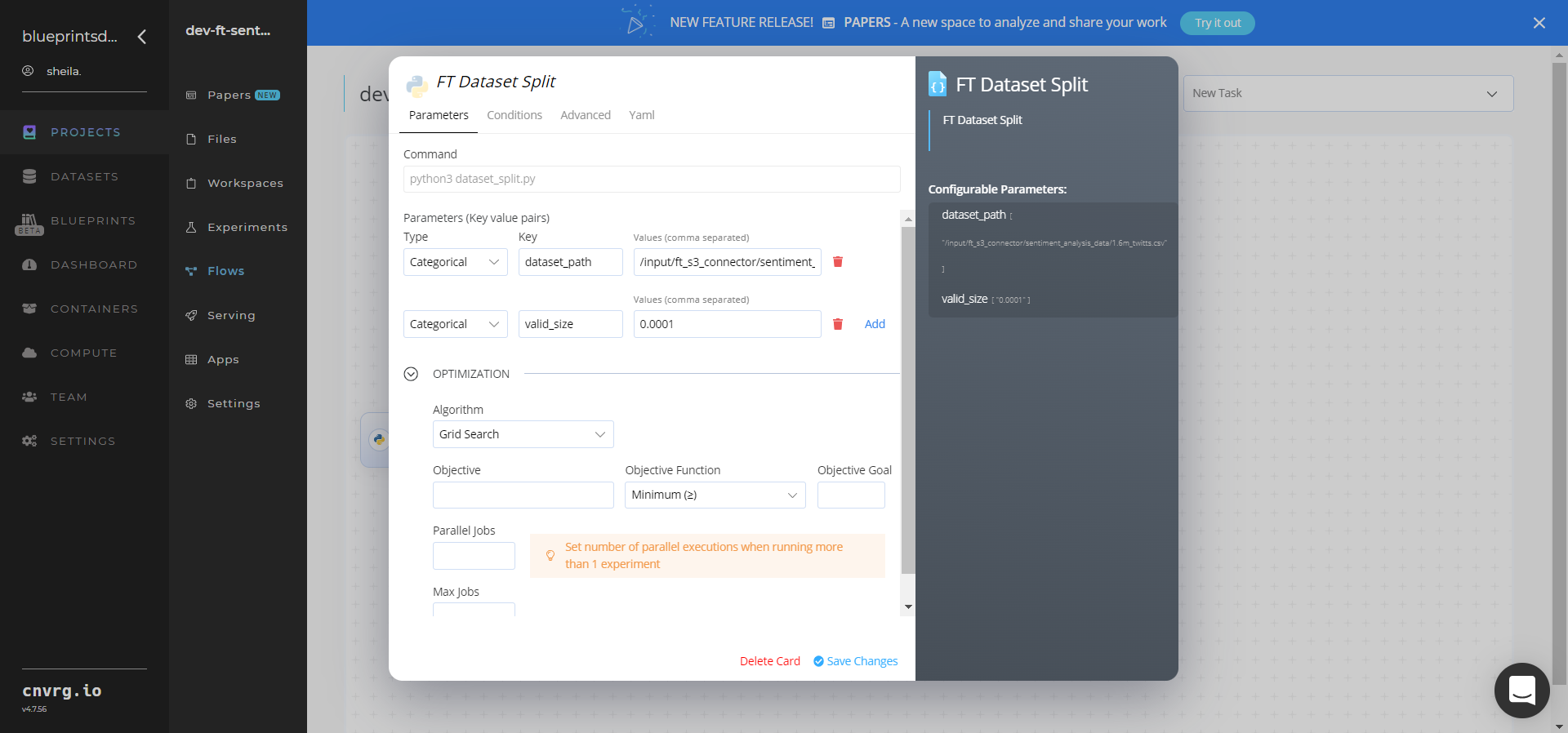
- Key:
dataset_path− Value: provide the path to the dataset in the following format:/input/ft_s3_connector/sentiment_analysis_data/1.6m_twitts.csv - Key:
valid_size− Value: provide the percentage of small dataset from the1.6m_twitts.csvdataset
NOTE
You can use the prebuilt datasets provided.
- Key:
Click the Advanced tab to change resources to run the blueprint, as required.
Click the FT Sentiment (Train) task to display its dialog.
Within the Parameters tab, provide the following Key-Value pair information:
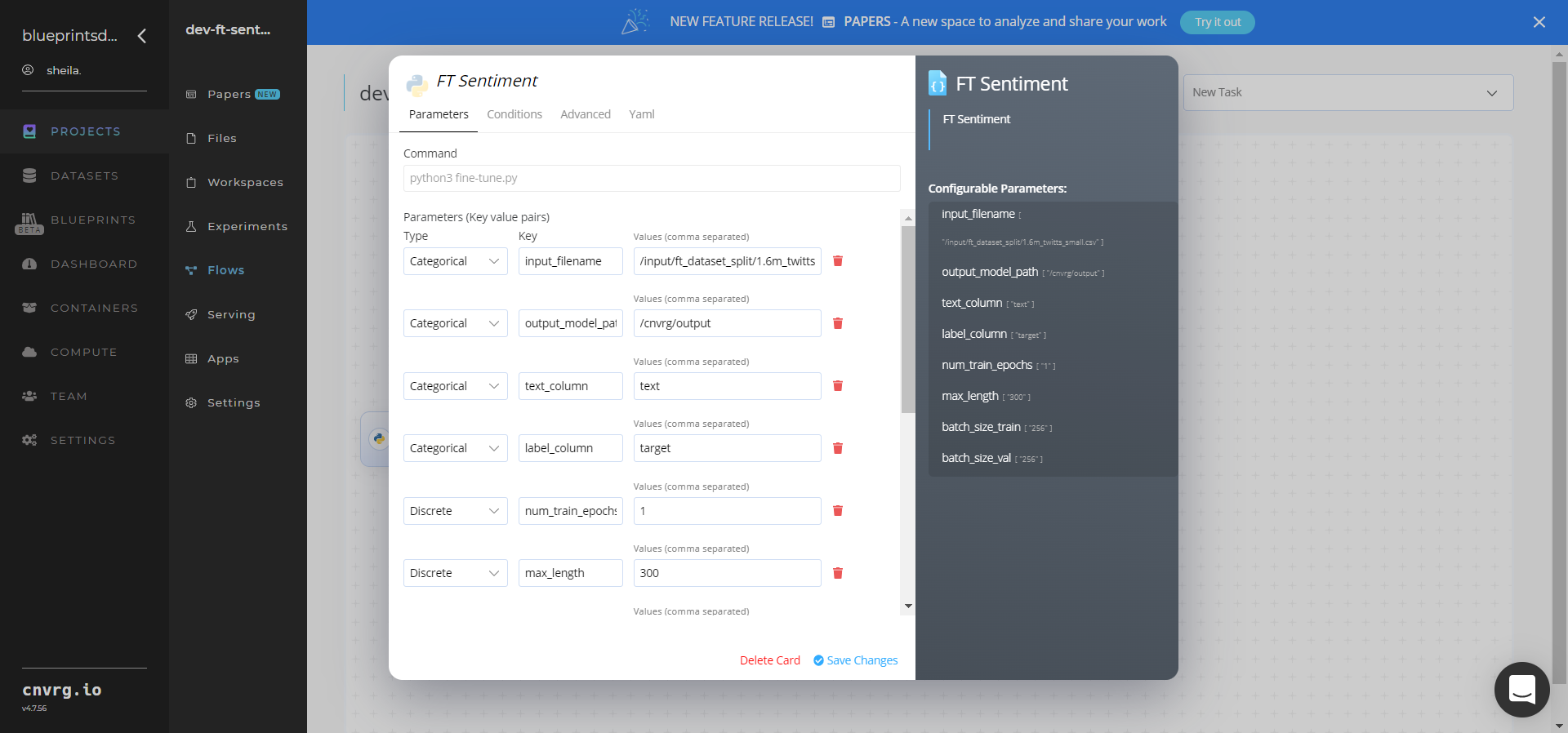
- Key:
input_filename− Value: provide the path to a local labeled train/validation data file - Key:
output_model_path− Value: provide the path to save the model/checkpoint/events - Key:
text_column− Value: enter the name of dataframe text column - Key:
label_column− Value: enter the name of dataframe label column - Key:
num_train_epochs− Value: set the number of epochs to perform while training - Key:
max_length− Value: set the maximum length for each sequence - Key:
batch_size_train− Value: set the number of texts the model fine-tunes in each epoch - Key:
batch_size_val− Value: set the number of texts the model evaluates in each epoch
NOTE
You can use the prebuilt datasets provided.
- Key:
Click the Advanced tab to change resources to run the blueprint, as required.
Click the FT Batch Predict task to display its dialog.
- Click the Parameters tab to set the following Key-Value pair information:
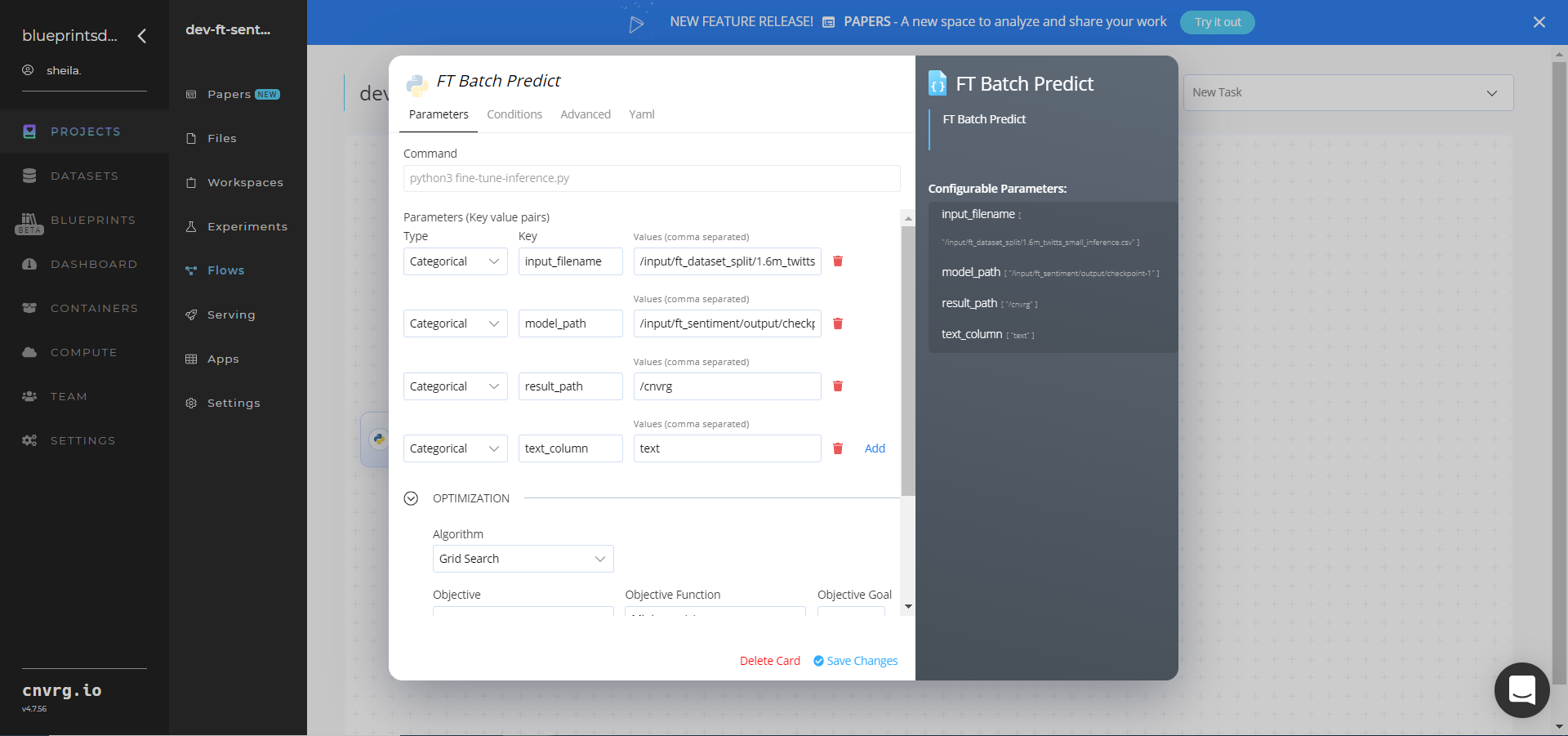
- Key:
input_filename− Value: provide the dataset split path to the train/validation data file in the following format:/input/ft_dataset_split/1.6m_twitts_small_inference.csv - Key:
model_path− Value: provide the sentiment model path to a saved model in the following format:/input/ft_sentiment/output/checkpoint-1 - Key:
result_path− Value: provide the results path; default/cnvrg/
- Key:
- Click the Advanced tab to change resources to run the blueprint, as required.
- Click the Parameters tab to set the following Key-Value pair information:
Click the Run button.
 The cnvrg software launches the training blueprint as set of experiments, generating a fine-tuned BERT sentiment-analyzer model and deploying it in batch mode.
The cnvrg software launches the training blueprint as set of experiments, generating a fine-tuned BERT sentiment-analyzer model and deploying it in batch mode.NOTE
The time required for model training and batch deployment depends on the size of the training data, the compute resources, and the training parameters.
Track the blueprint’s real-time progress in its Experiments page, which displays artifacts such as logs, metrics, hyperparameters, and algorithms.
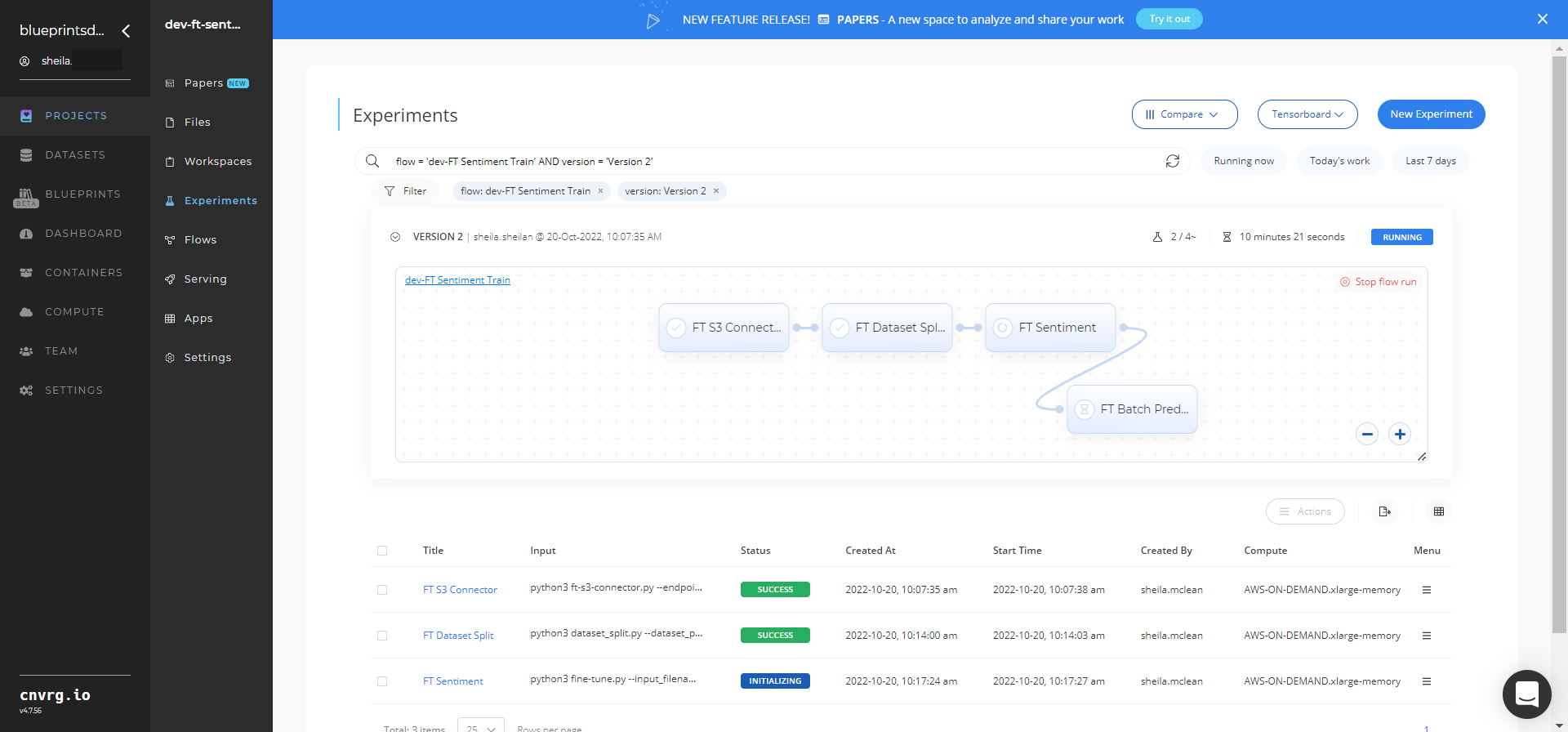
Select Batch Predict > Experiments > Artifacts and locate the batch output CSV file.
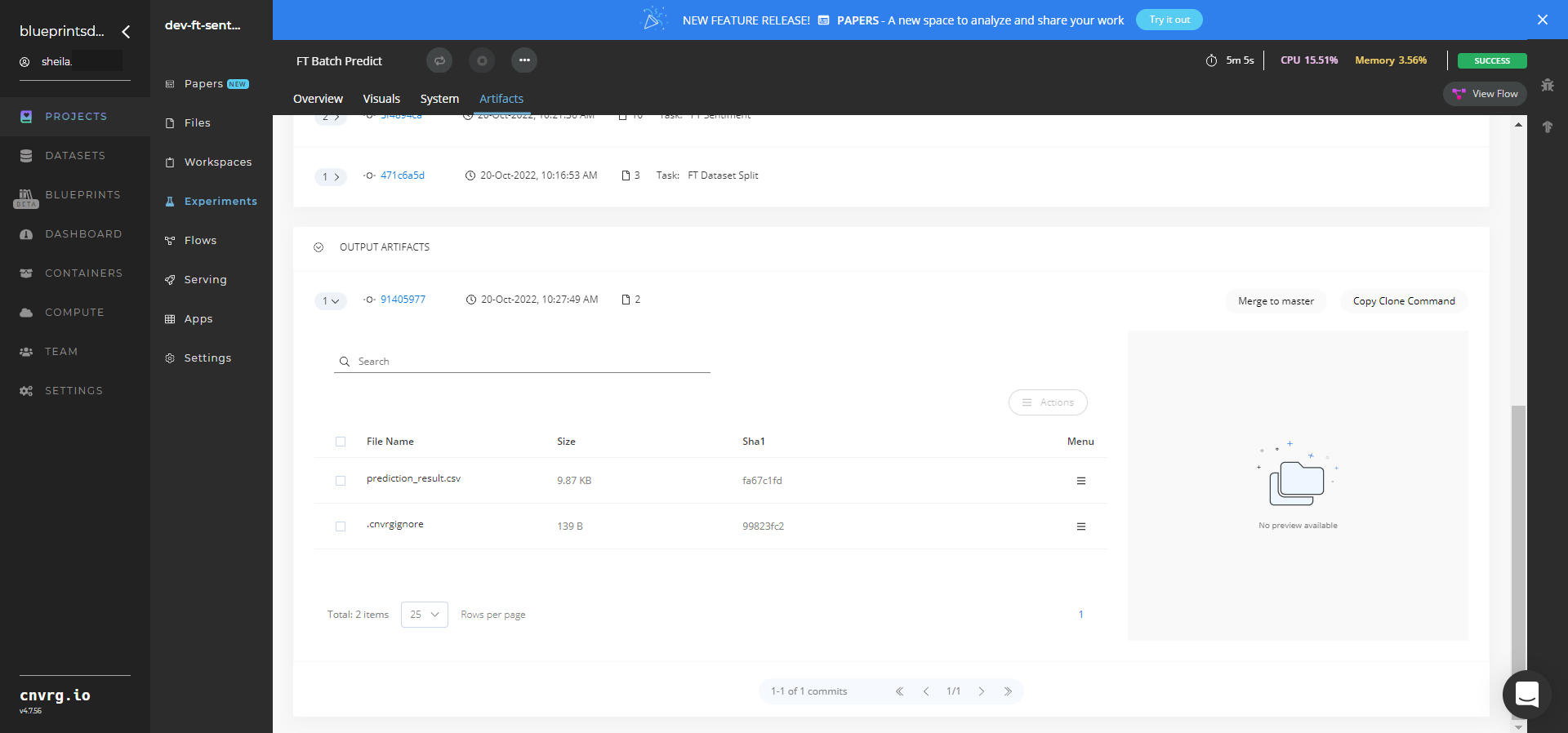
Select the prediction_result.csv File Name, click the Menu icon, and select Open File to view the output CSV file.
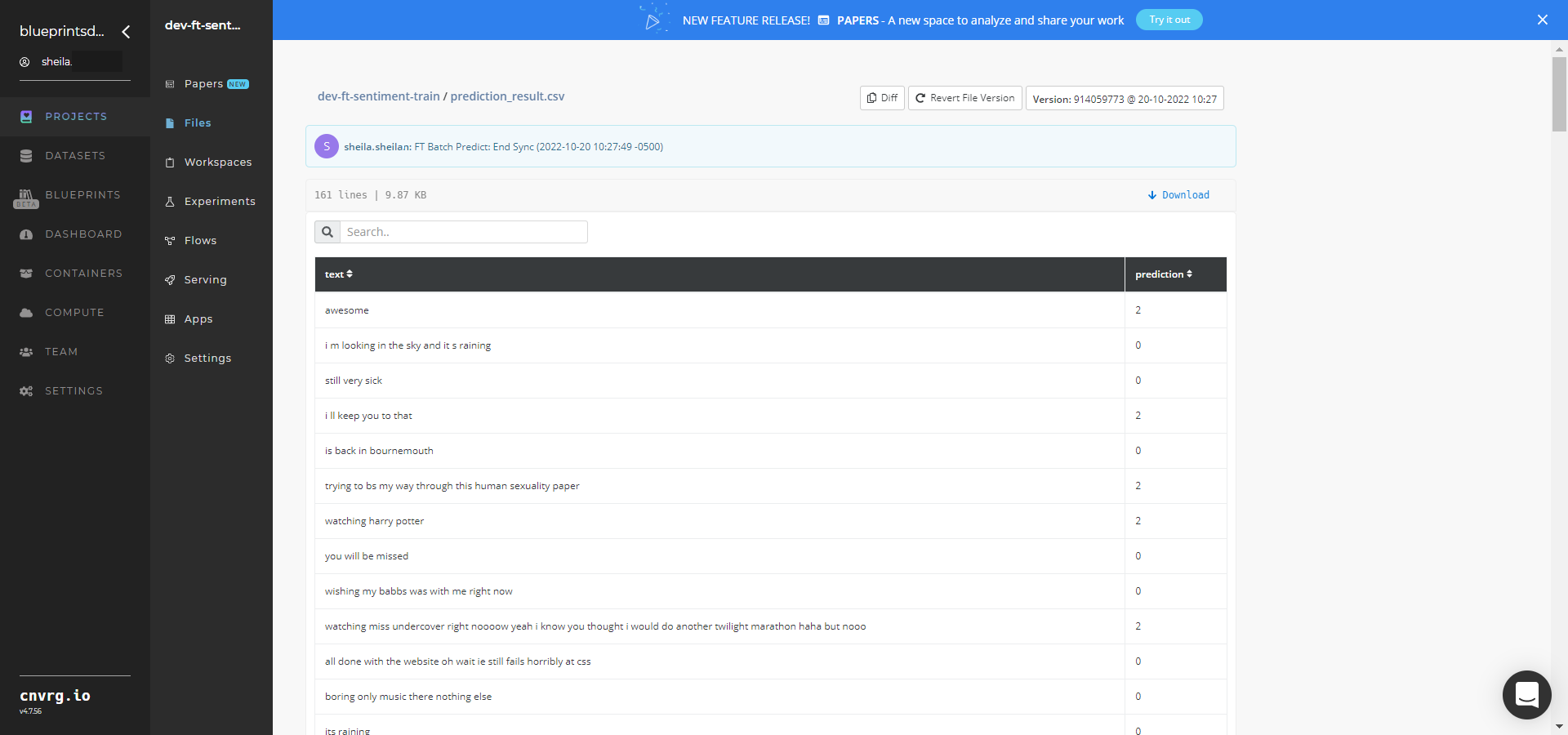
A tailored model that can analyze sentiment in text has now been fine-tuned and deployed in batch mode. For information on this blueprint's software version and release details, click here.
# Connected Libraries
Refer to the following libraries connected to this blueprint:
# Related Blueprints
Refer to the following blueprints related to this training blueprint: