# Text-PDF Extraction AI Blueprint - deprecated from 11/2024
# Inference
Text extraction uses a trained model to extract text from PDFs. This blueprint can be used with digital or scanned PDFs. Input a PDF and receive raw text data from the PDF’s textual content. Further operations such as searches can be performed on the text extracted using the blueprint.
# Purpose
Use this inference blueprint to immediately extract text from a scanned or digital PDF. To use this pretrained text-extractor model, create a ready-to-use API-endpoint that can be quickly integrated with your data and application.
This inference blueprint’s endpoint extracts text from one PDF at a time. To simultaneously extract text from multiple PDFs, run this counterpart’s batch blueprint, which extracts text from multiple PDFs placed in an S3 connector or a cnvrg dataset.
# Instructions
NOTE
The minimum resource recommendations to run this blueprint are 3.5 CPU and 8 GB RAM.
NOTE
This blueprint’s performance can benefit from using GPU as its compute.
Complete the following steps to deploy this text-extractor endpoint:
- Click the Use Blueprint button.
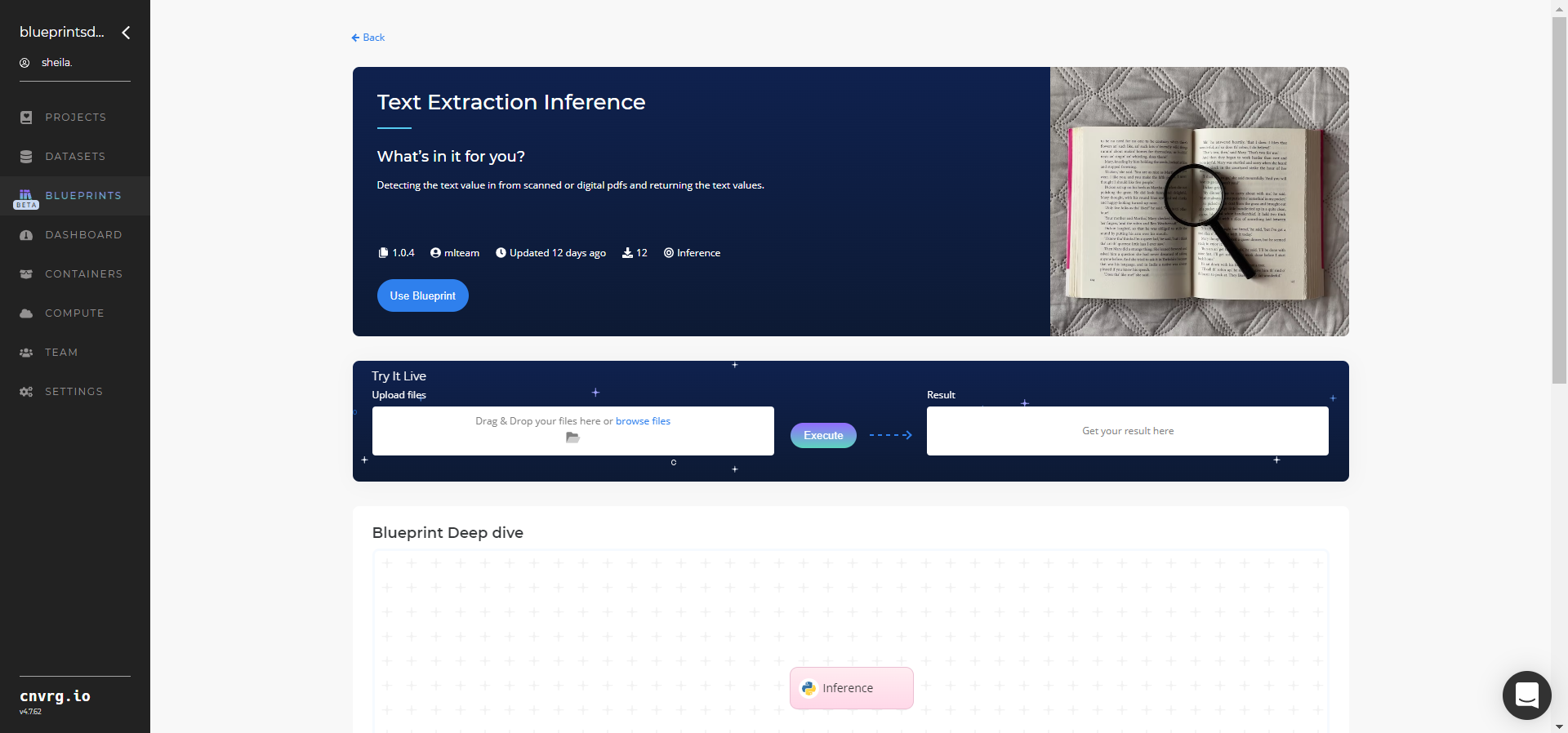
- In the dialog, select the relevant compute to deploy the API endpoint and click the Start button.
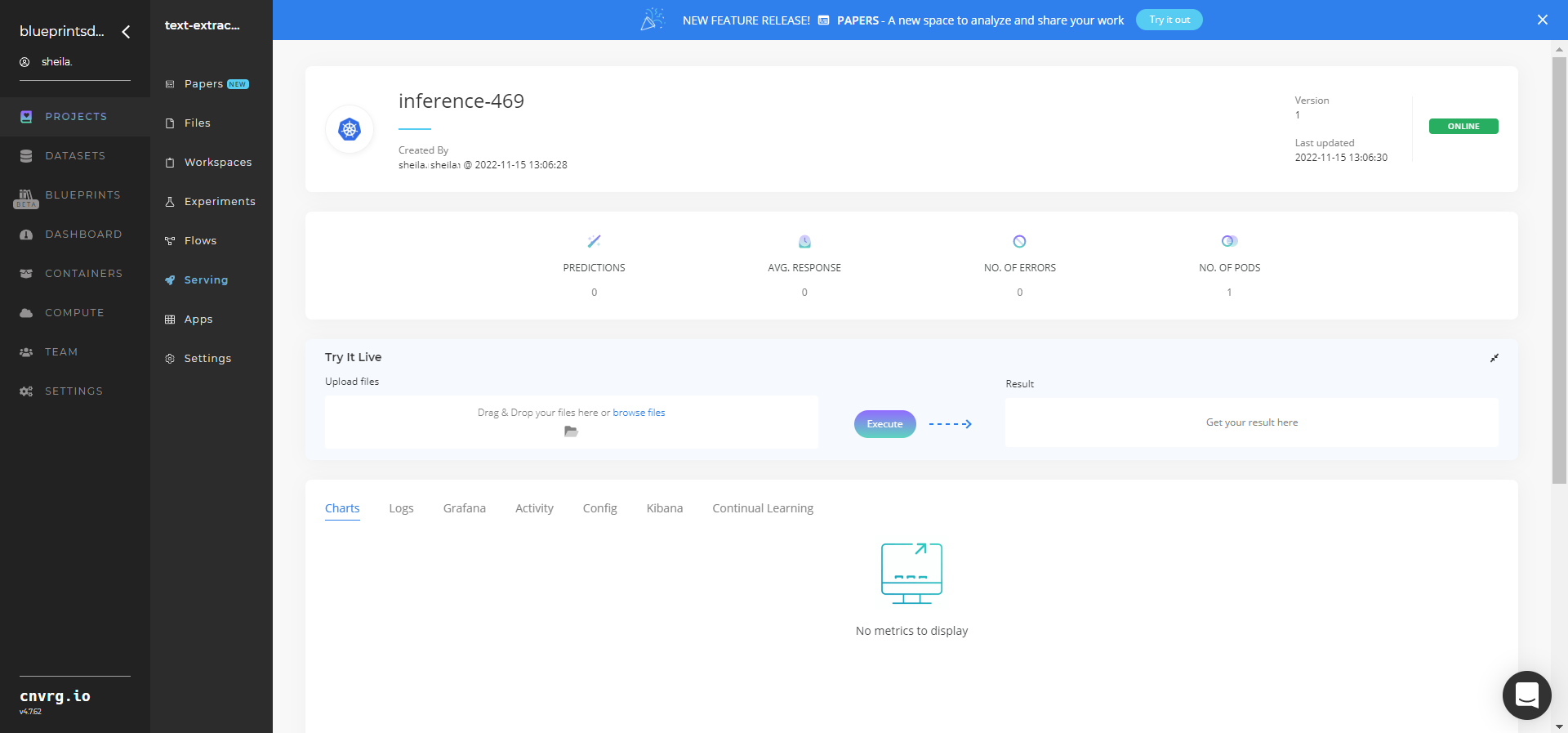
- The cnvrg software redirects to your endpoint. Complete one or both of the following options:
- Use the Try it Live section with any PDF containing text to be extracted.
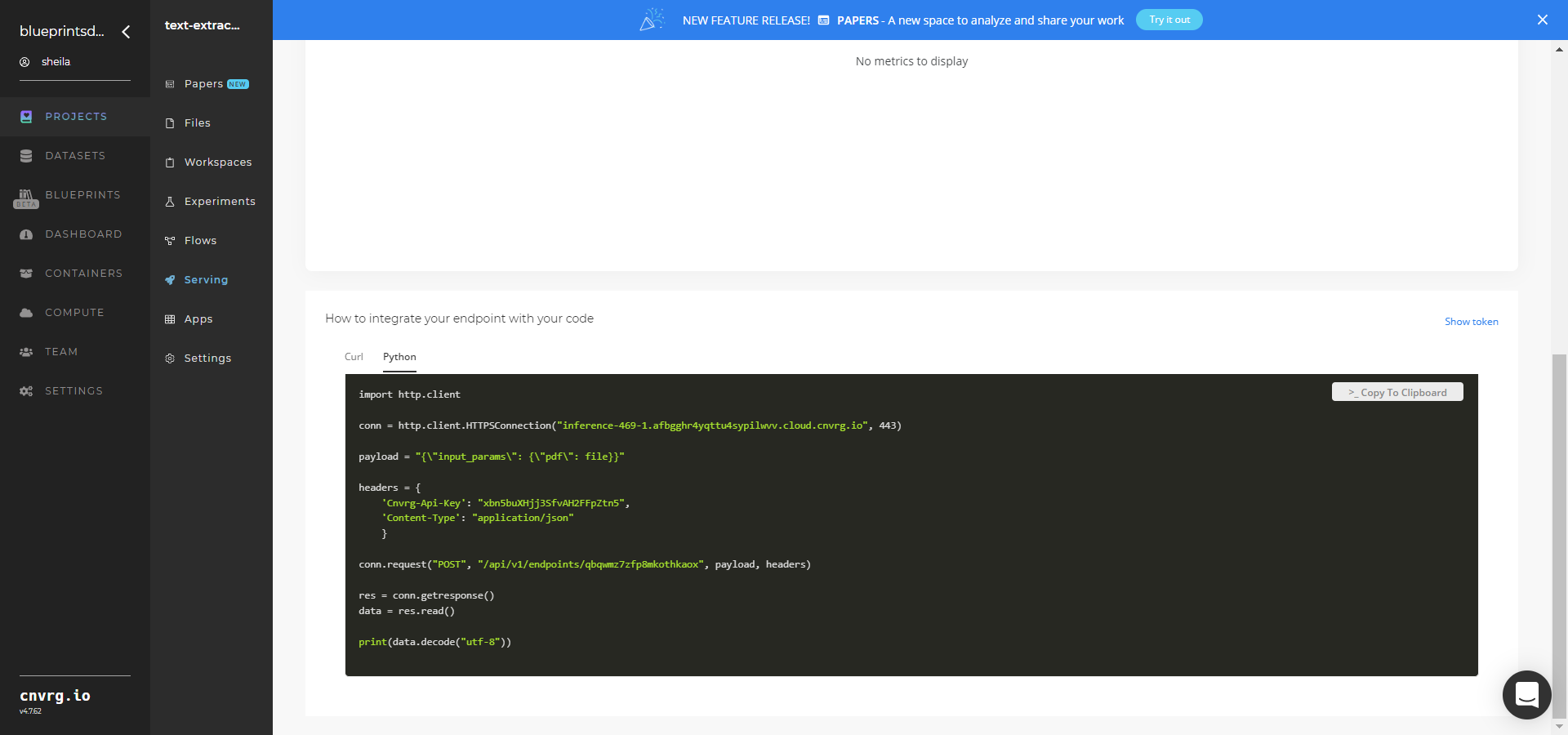
- Use the bottom integration panel to integrate your API with your code by copying in the code snippet.
- Use the Try it Live section with any PDF containing text to be extracted.
An API endpoint that extracts text from any digital or scanned PDF has now been deployed. For information on this blueprint's software version and release details, click here.
# Related Blueprints
Refer to the following blueprint related to this inference blueprint: