# Text Summarization AI Blueprint -deprecated from 11/2024
# Batch-Predict
Text Summarization is a process of creating a fluent, concise, and continuous summary from large textual paragraphs and passages while preserving main ideas, key points, and important information.
# Purpose
Use the PubMed Summarization Batch blueprint with a tailor-trained model to extract text summaries from PubMed papers. This blueprint uses the PubMed Connector to access the PubMed National Library of Medicine database and downloads the user-selected papers and creates their summaries.
NOTE
This blueprint and the associated PubMed Connector downloads only full papers. It does not summarize the PubMed database’s abstracts or titles.
Use the Text Summarization Batch blueprint with a tailor-trained model to extract text summaries from custom text and Wikipedia articles. To use this blueprint, provide one summarization folder in the S3 Connector with the training file containing the text to be summarized and the model/tokenizer files.
The main summarization folder has two subdirectories, namely:
default_model− A folder with the base model used to fine tune to customize the modeltokenizer− A folder with the tokenizer files used to assist in text summarization
NOTE
This documentation uses the Wikipedia connection and subsequent summarization as an example. The users of this blueprint can select any source of text and input it to the Batch Predict task.
# Deep Dive
The following flow diagram illustrates the PubMed Text Summarization batch blueprint’s pipeline:
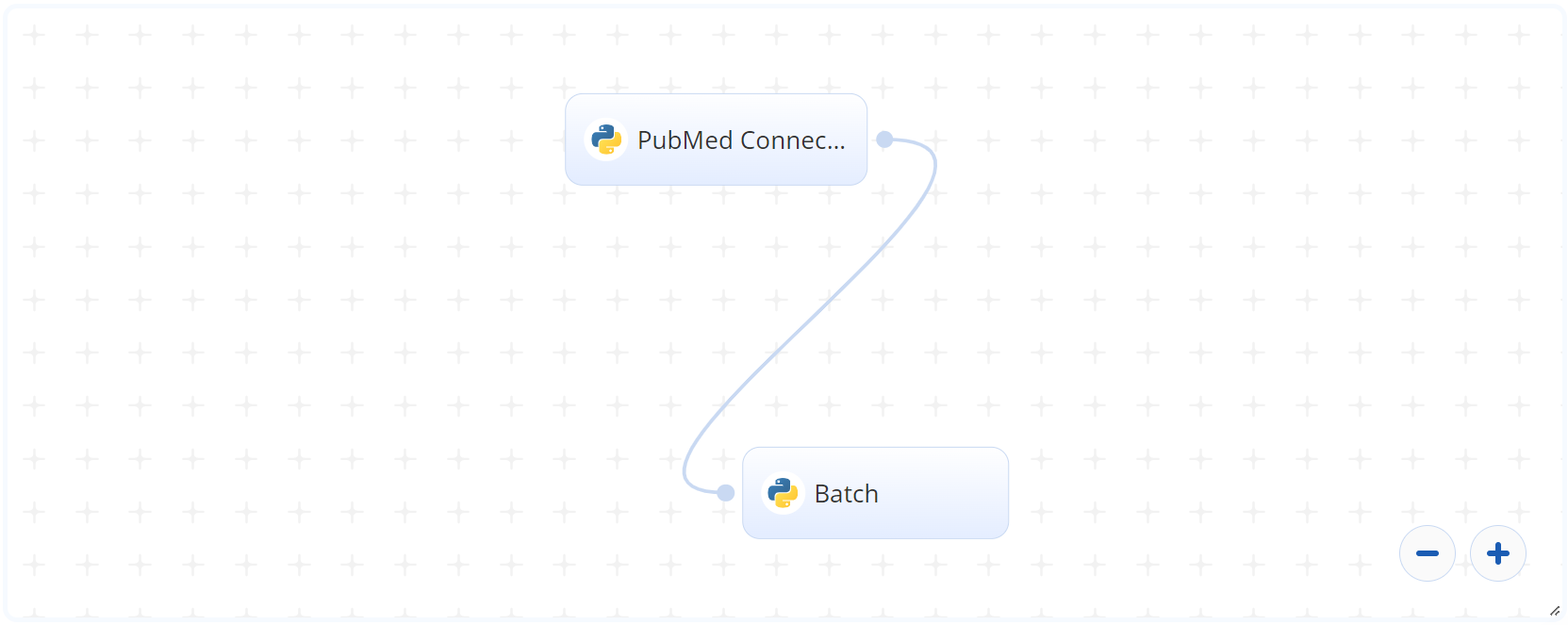
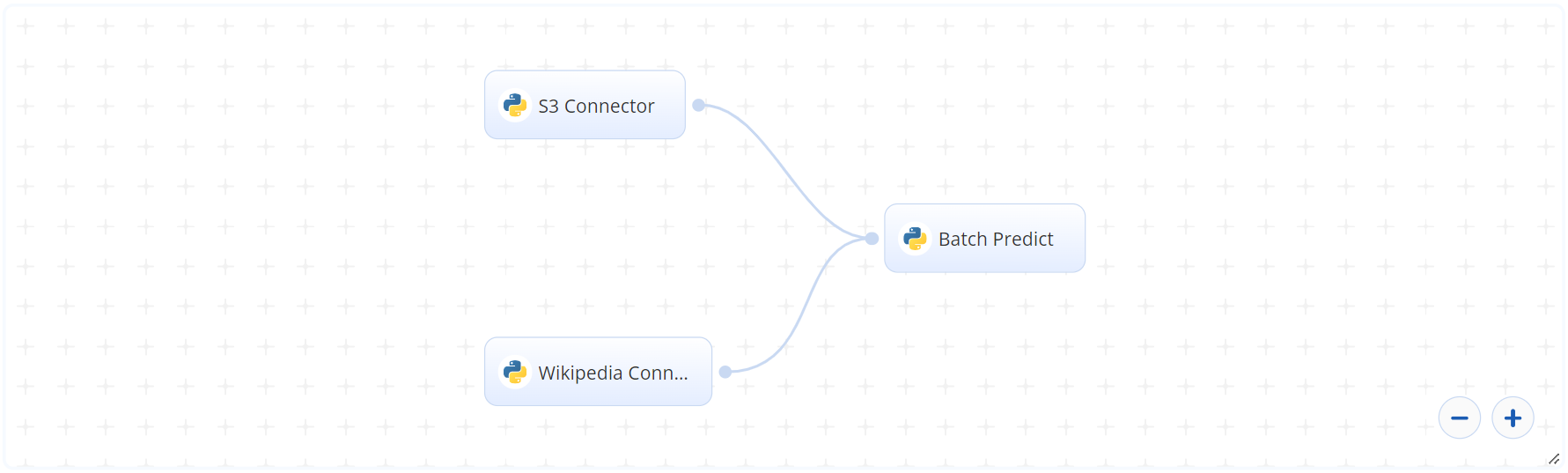
The following flow diagram illustrates the Text Summarization batch-predict blueprint’s pipeline:
# Arguments/Artifacts
For information on these blueprints’ tasks, inputs, and outputs, click here.
# PubMed Summarization Inputs
When the Batch task is used the pubmed_connector, ensure the dir value contains the location of the PubMed Connector outputs, such as /input/pubmed_connector/pdfs.
The PubMed Connector requires the following inputs:
--email(string, required) is the user’s email address as an input argument.--field(string, required) is the field to be extracted from the papers. For this blueprint, the only valid field isfullfor the full articles.--max_results(integer, required) is the maximum number of results to return. Default:5.--query(string, required) is the text to query the PubMed database.
# PubMed Summarization Outputs
--output.csvis the name of the file containing the paper summaries.
# Text Summarization Inputs
--input_pathis the name and path of the file that contains the articles. It is like theoutput_summaries_filedescribed in the Wikipedia Connector. This CSV formatted file has two columns, one with the summary and the other with a dummy value 'x'. The dummy value is for formatting purposes and does not require user modifications. The file headers are a string pair called document and summary. The file path includes the dataset name containing the file, like the following:\dataset_name\input_file.csv. Ensure that the dataset is in text format. The values can contain article text, cleaned of any special characters. When this Batch Predict task is used thewikipeda_connector, ensure theinput pathcontains the file location of the Wikipedia Connector outputs, like/input/wikipedia_connector/wiki_output.csv--modelpathis the model that generates the summaries. By default, it is the cnvrg model trained onwiki_linguadataset./model/model/is the model’s default path. For a custom model, the path is/input/train-task-name/model-filewheretrain-task-nameis the library used to run the code. More information can be found here.--tokenizeris the tokenizer used while performing the summarization. There is no option to train the tokenizer.--min_percentis the lowest ratio of the paragraph, to which the summary lengths can be reduced.--encoder_max_lengthis the maximum length of the encoder used while inputting text to summarize.
# Text Summarization Outputs
--output.csvis the name of the file containing the custom text and article summaries.
# Instructions
NOTE
The minimum resource recommendations to run this blueprint are 3.5 CPU and 8 GB RAM.
NOTE
This blueprint’s performance can benefit from using GPU as its compute.
NOTE
NOTE: The PubMed Connector Batch and Wikipedia Connector Batch Predict use different models.
Complete the following steps to run the text-summarizer model in batch mode:
Click the Use Blueprint button. The cnvrg Blueprint Flow page displays.
For the PubMed Summarization Batch blueprint, complete the following steps:
- Click the PubMed Connector task to display its dialog, and within the Parameters tab, provide the following Key-Value pair information:
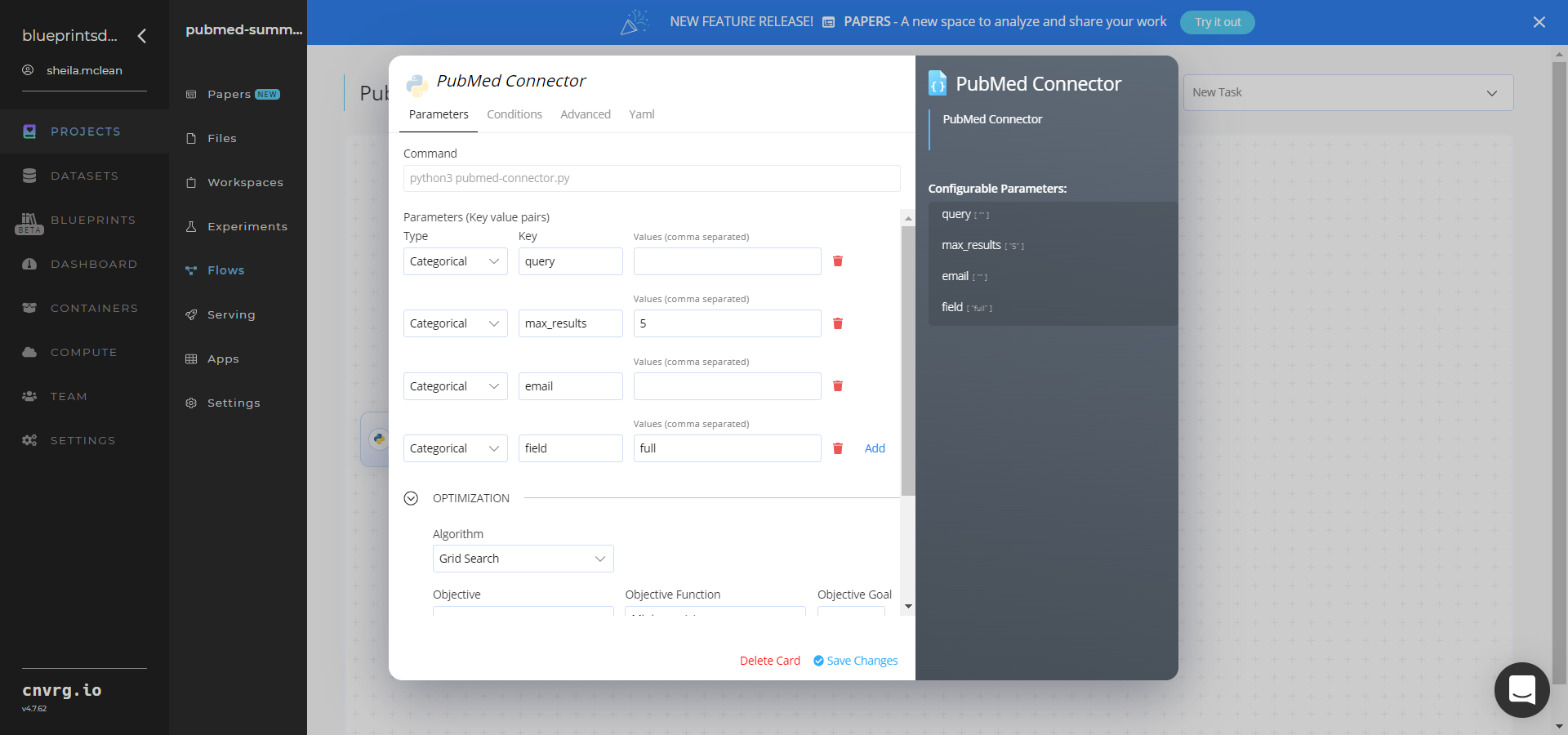
- Key:
email− Value: provide the user’s email address - Key:
field− Value: leave the field to be extracted from the papers asfullfor the full articles - Key:
max_results− Value: provide the maximum number of results to return - Key:
query− Value: provide the text to query the PubMed database
- Key:
- Click the Advanced tab to change resources to run the blueprint, as required.
- Click the Batch task, and within the Parameters tab, provide the following Key-Value pair information:
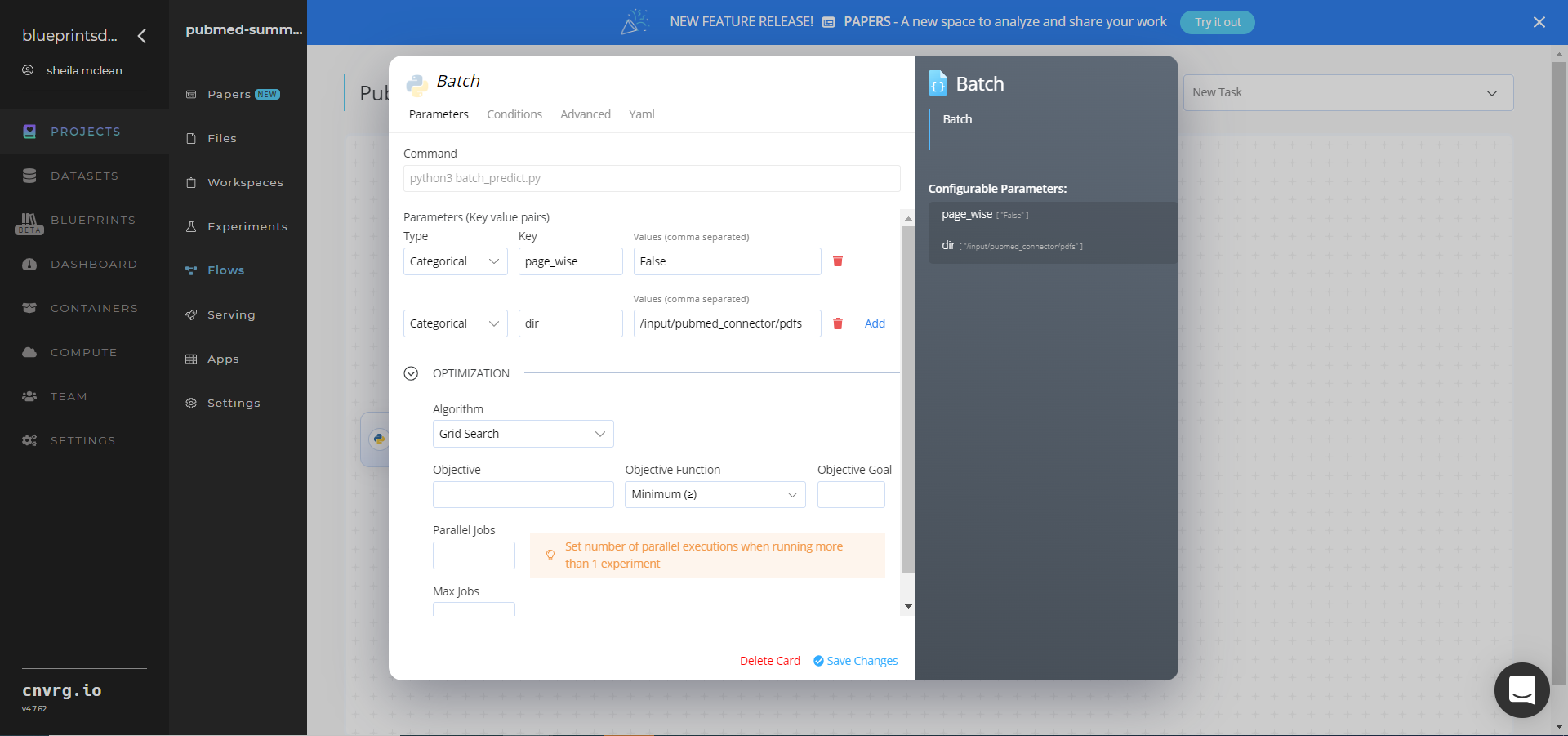
- Key:
page_wise− Value: leave the value asfalsefor the full article summaries - Key:
dir− Value: provide the path to the data file including the PubMed prefix. Ensure the path adheres to the following format:/input/pubmed_connector/pdfs
- Key:
- Click the Advanced tab to change resources to run the blueprint, as required.
- Click the PubMed Connector task to display its dialog, and within the Parameters tab, provide the following Key-Value pair information:
For the Text Summarization Batch blueprint, complete the following steps:
Click the S3 Connector task to display its dialog, and within the Parameters tab, provide the following Key-Value pair information:
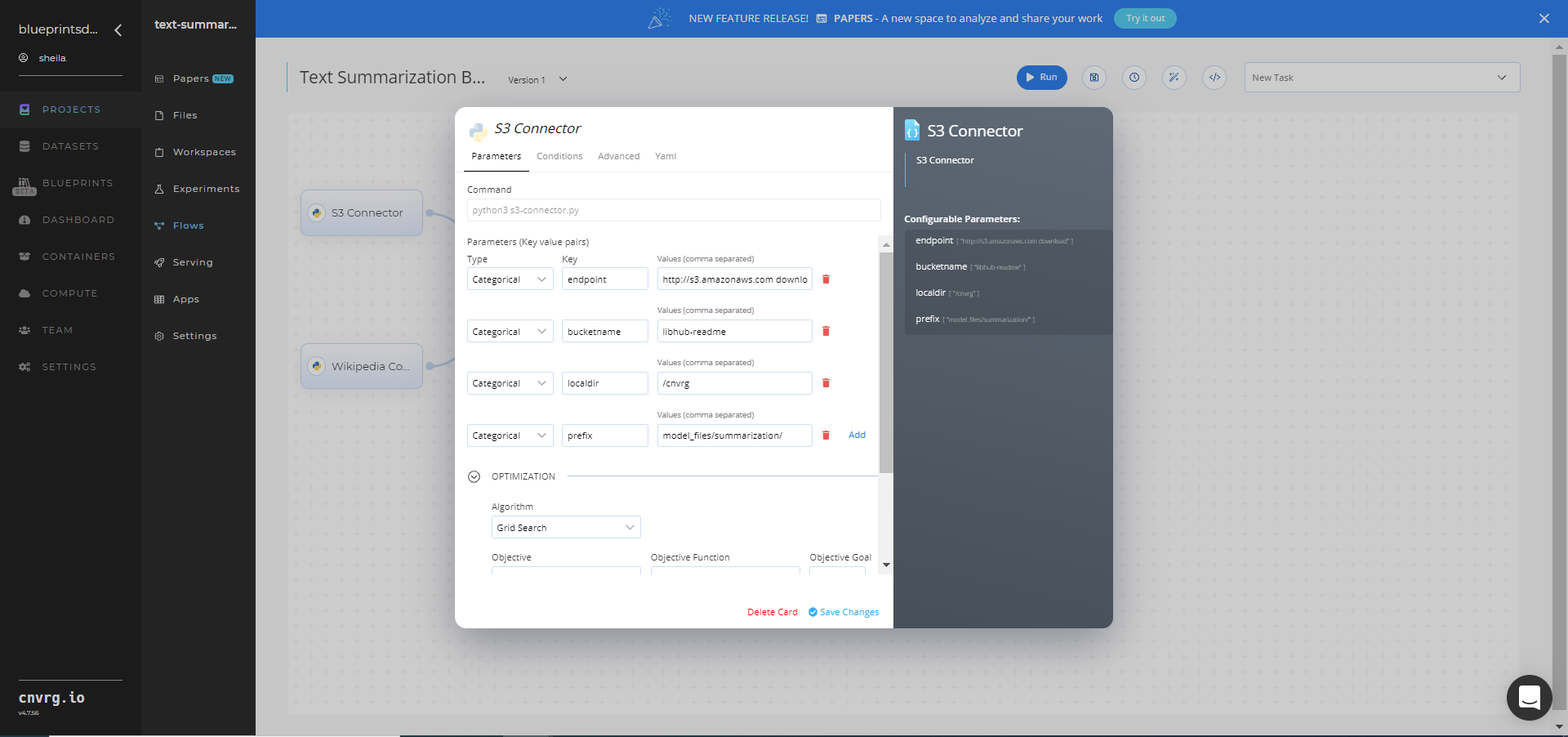
- Key:
bucketname− Value: provide the data bucket name - Key:
prefix− Value: provide the main path to the articles folder
- Key:
Click the Advanced tab to change resources to run the blueprint, as required.
Click the Wikipedia Connector task to display its dialog, and within the Parameters tab, provide the following Key-Value pair information:
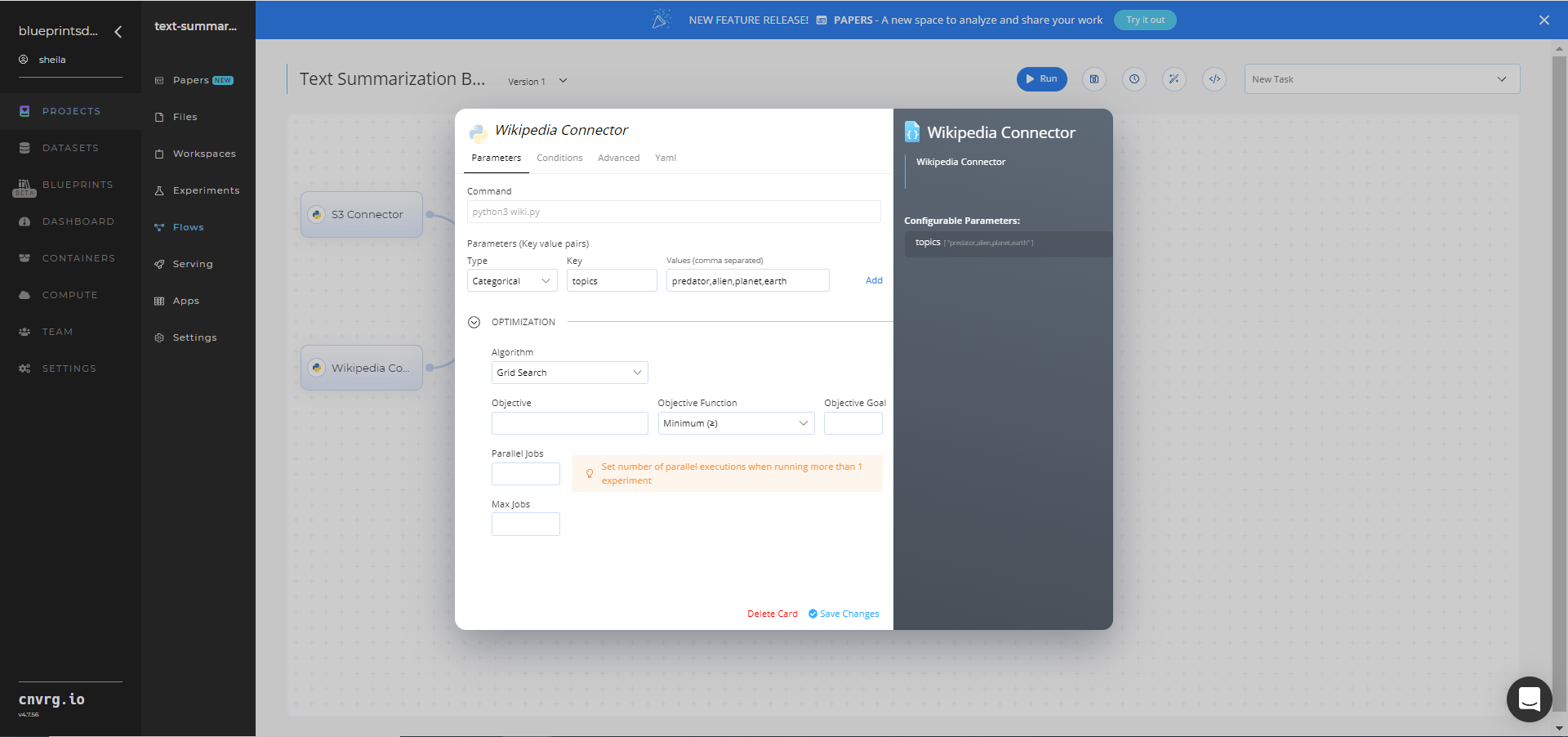
- Key:
topics− Value: provide the topics to extract from Wikipedia - Format − the flexible format can be in either comma-separated text (shown), tabular CSV, or URL link
- Key:
Click the Advanced tab to change resources to run the blueprint, as required.
Click the Batch-Predict task to display its dialog, and within the Parameters tab, provide the following Key-Value pair information:
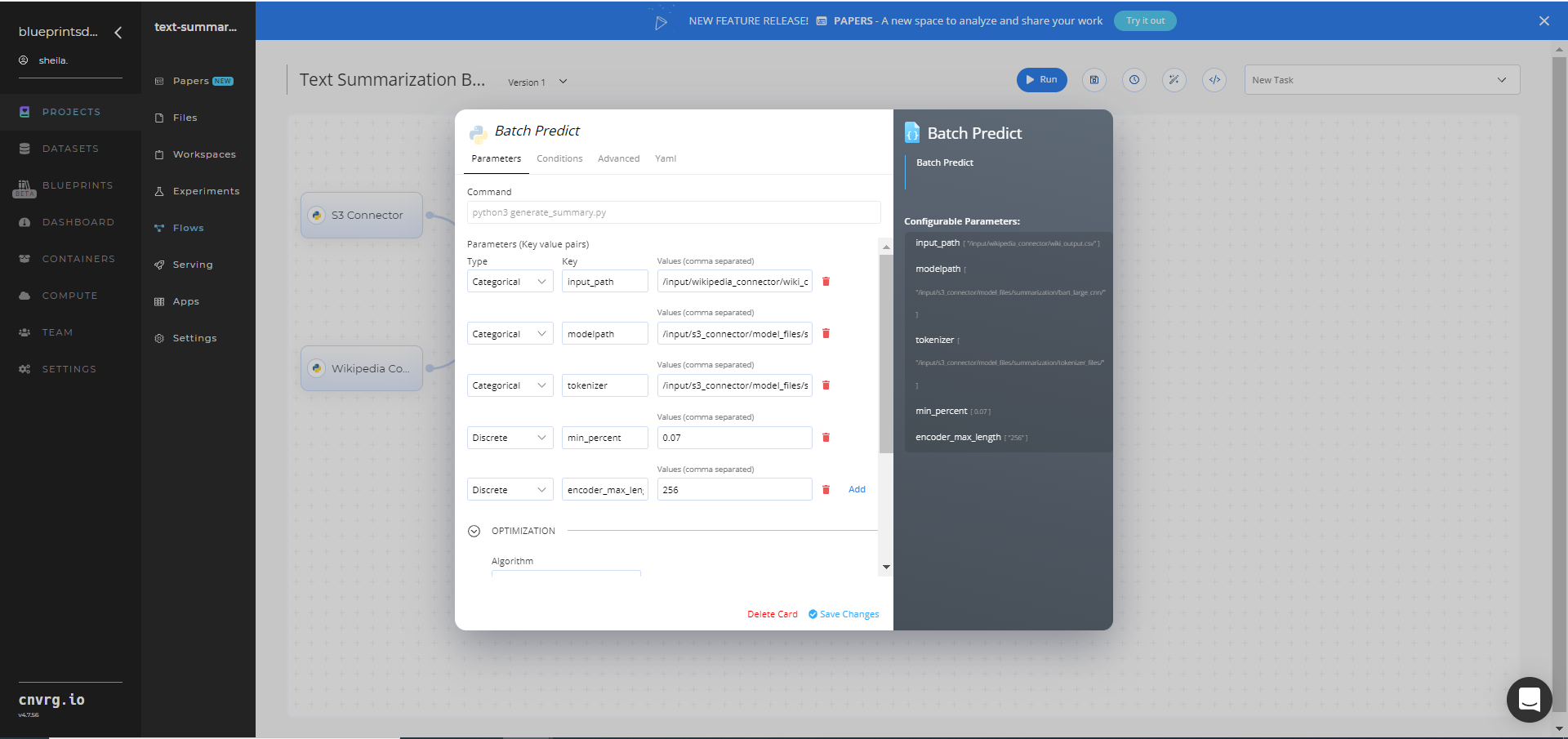
- Key:
input_path− Value: provide the path to the training file including the Wikipedia prefix in the following format:/input/wikipedia_connector/wiki_output.csv - Key:
modelpath− Value: provide the path to the model including the S3 prefix in the following format:/input/s3_connector/model_files/summarization/bart_large_cnn/ - Key:
tokenizer− Value: provide the path to the tokenizer files including the S3 prefix in the following format:/input/s3_connector/model_files/summarization/tokenizer_files/
NOTE
You can use the prebuilt example data paths provided.
- Key:
Click the Advanced tab to change resources to run the blueprint, as required.
Click the Run button.


Depending on the blueprint run, the cnvrg software deploys a text-summarization model that summarizes PubMed papers or custom text and Wikipedia articles and downloads CSV files containing the summaries.
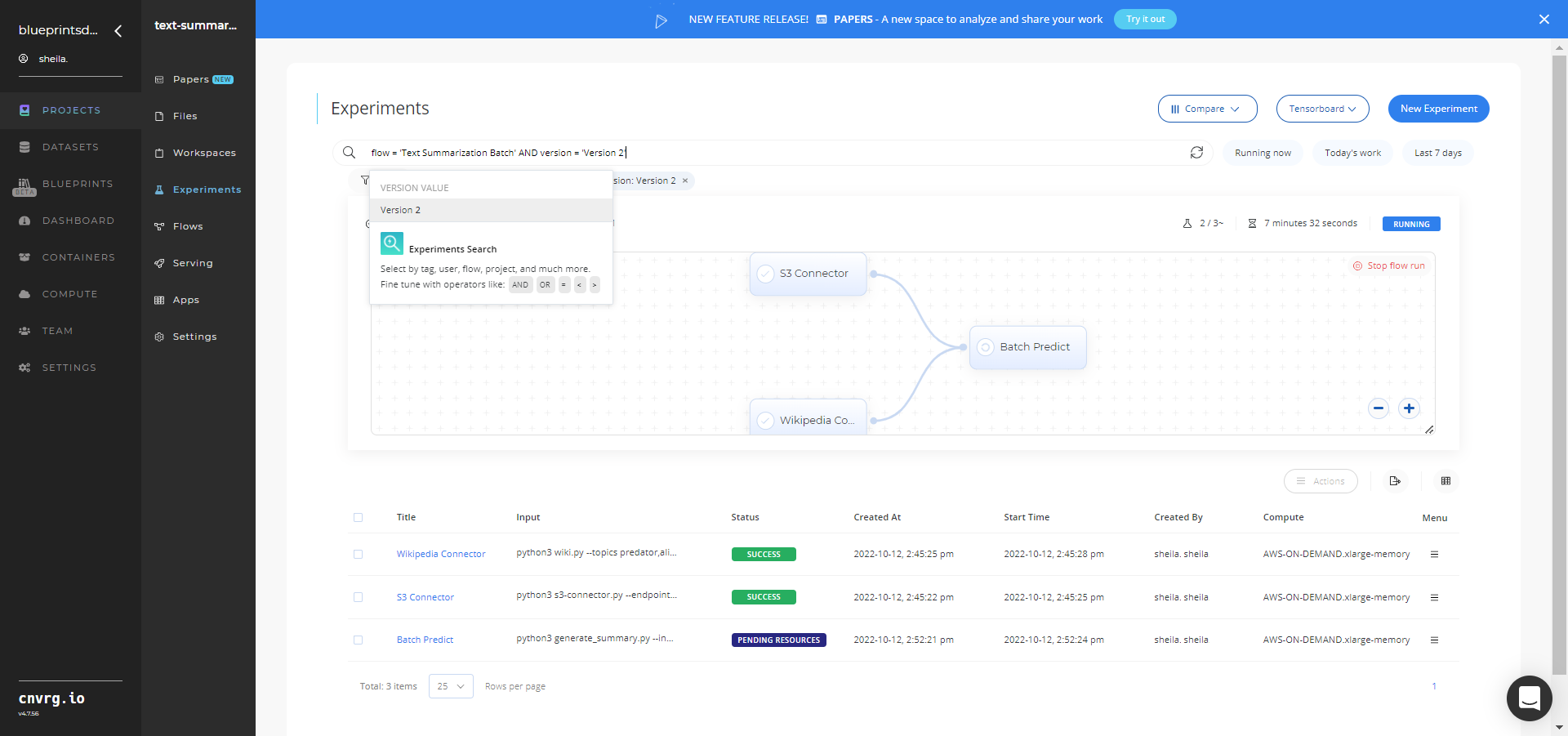
Track the blueprint’s real-time progress in its Experiments page, which displays artifacts such as logs, metrics, hyperparameters, and algorithms. The Text Summarization Batch Experiments page is shown.
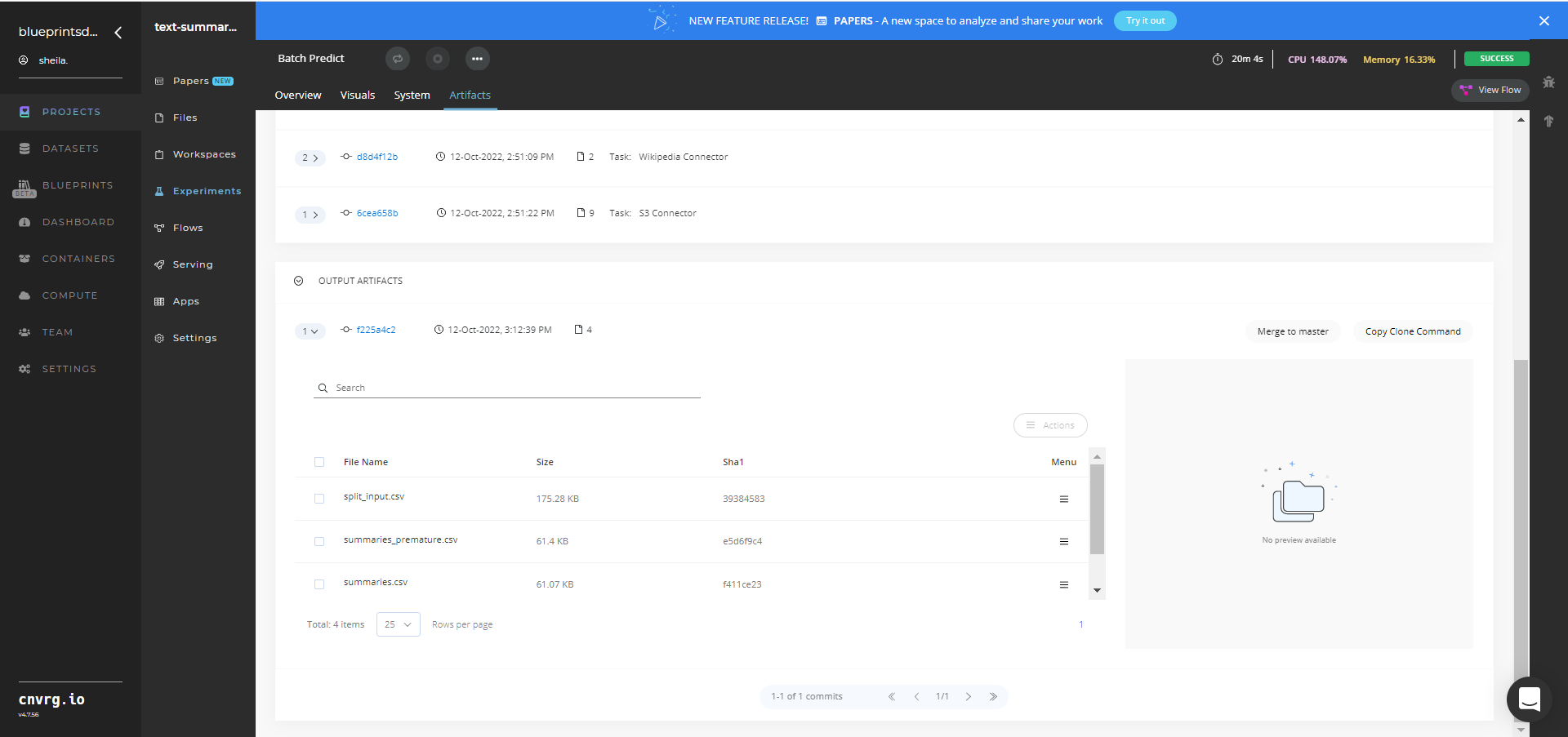
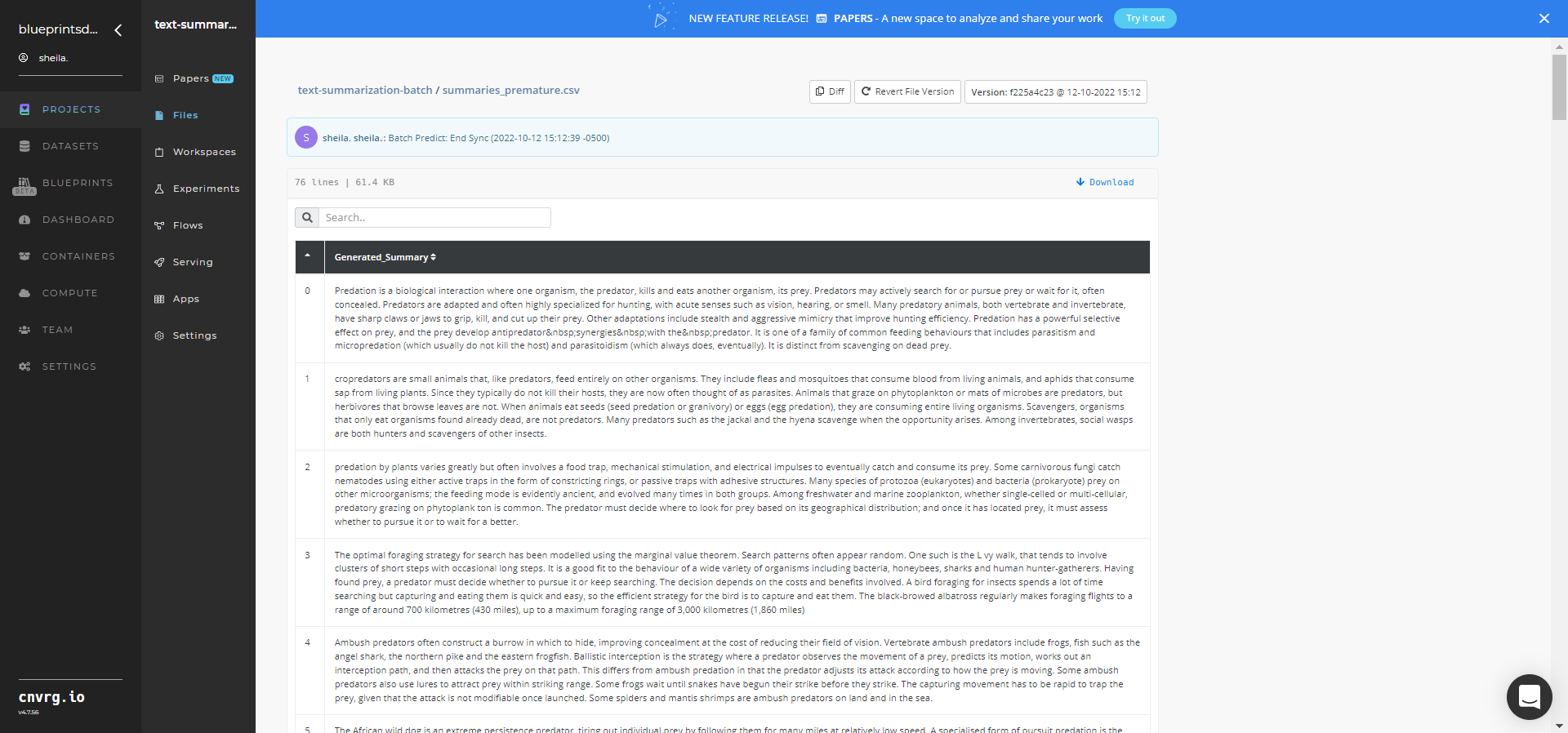
Select Batch Predict > Experiments > Artifacts and locate the output CSV files. The Text Summarization Batch Artifacts are shown below.
Select the desired CSV File Name, click the right Menu icon, and click Open File to view the output CSV file. An output CSV file from the Text Summarization Batch blueprint is shown below.
Depending on the blueprint run, a custom text-summarizer model that summarizes PubMed papers or custom text and Wikipedia articles has now been deployed in batch mode. For information on a blueprint's software version and release details, click here or click here.
# Connected Libraries
Refer to the following libraries connected to this blueprint:
# Related Blueprints
Refer to the following blueprints related to this batch blueprint:
- Text Summarization Inference
- Text Summarization Train
- Topic Modeling Batch
- Text Extraction Inference
- Text Detection Batch
# Inference
Text summarization is a process of creating a fluent, concise, and continuous summary from large textual paragraphs and passages while preserving main ideas, key points, and important information.
# Purpose
Use this inference blueprint to immediately summarize English text to short sentences. To use this pretrained text-summarization model, create a ready-to-use API-endpoint that can be quickly integrated with your data and application.
This inference blueprint’s model was trained using the WikiLingua Multilingual Abstractive Summarization dataset. To use custom data according to your specific business, run this counterpart’s training blueprint, which trains the model and establishes an endpoint based on the newly trained model.
# Instructions
NOTE
The minimum resource recommendations to run this blueprint are 3.5 CPU and 8 GB RAM.
NOTE
This blueprint’s performance can benefit from using GPU as its compute.
Complete the following steps to deploy a text-summarization API endpoint:
- Click the Use Blueprint button.
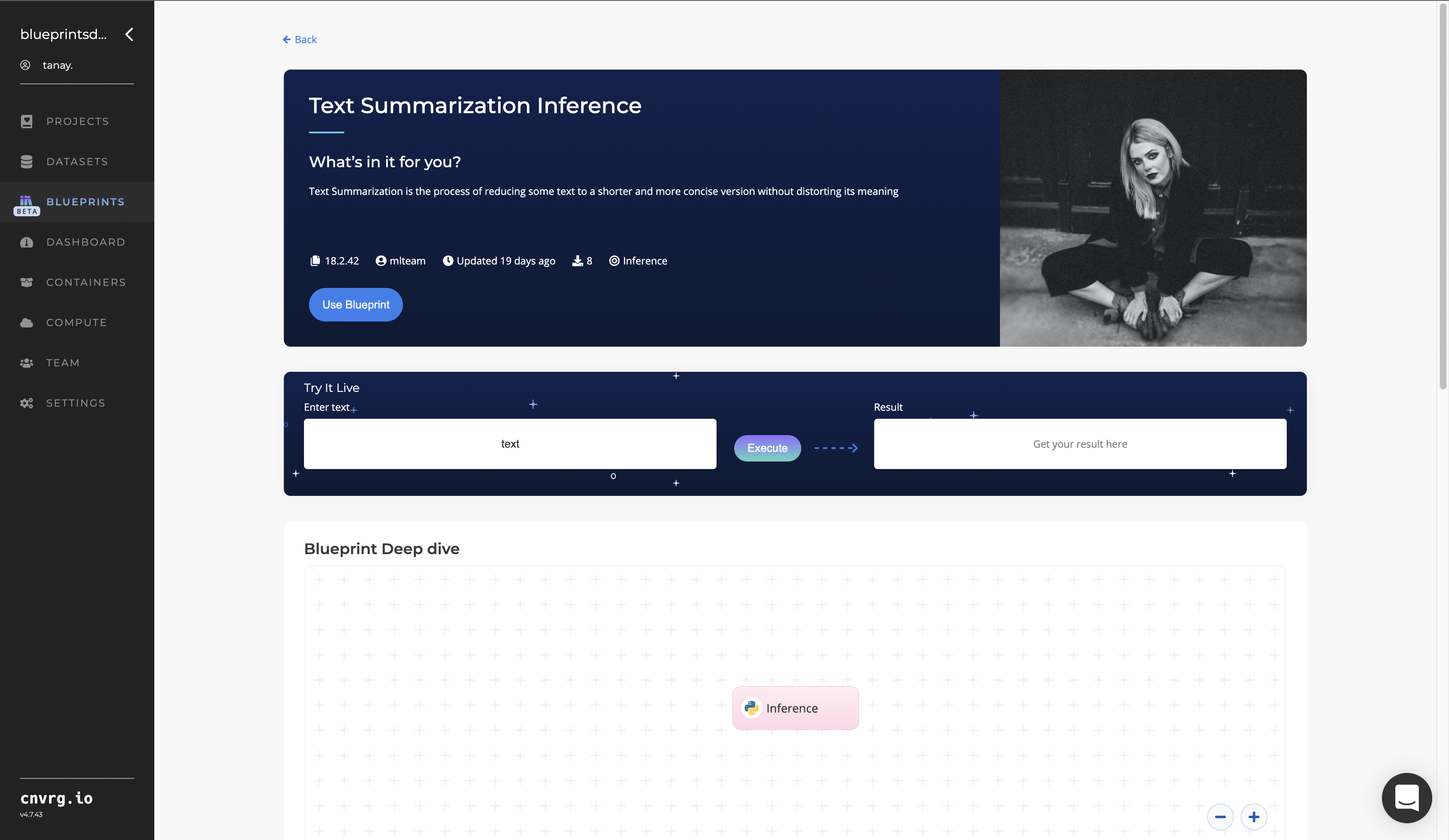
- In the dialog, select the relevant compute to deploy the API endpoint and click the Start button.
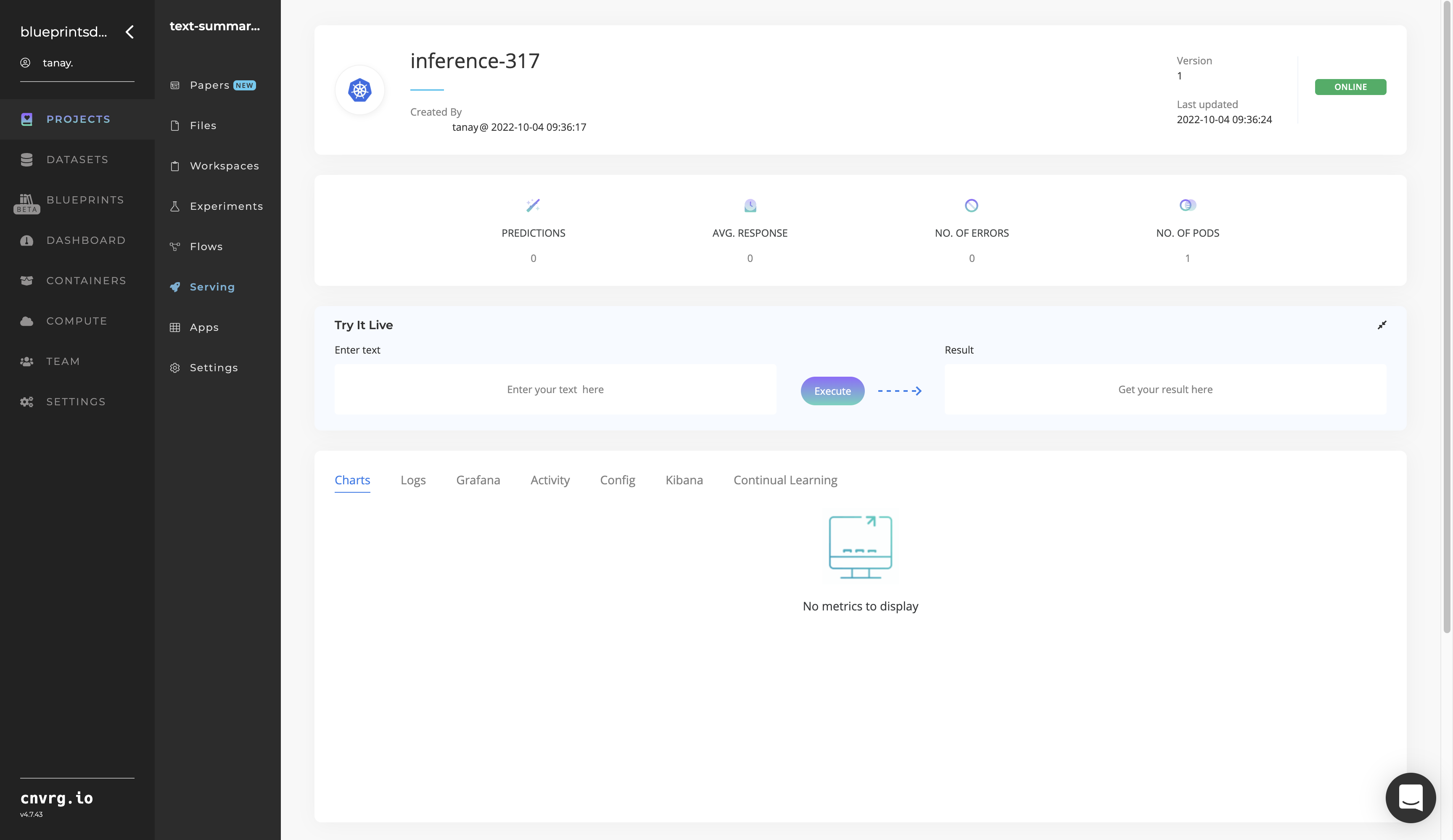
- The cnvrg software redirects to your endpoint. Complete one or both of the following options:
- Use the Try it Live section with any text to check your model.
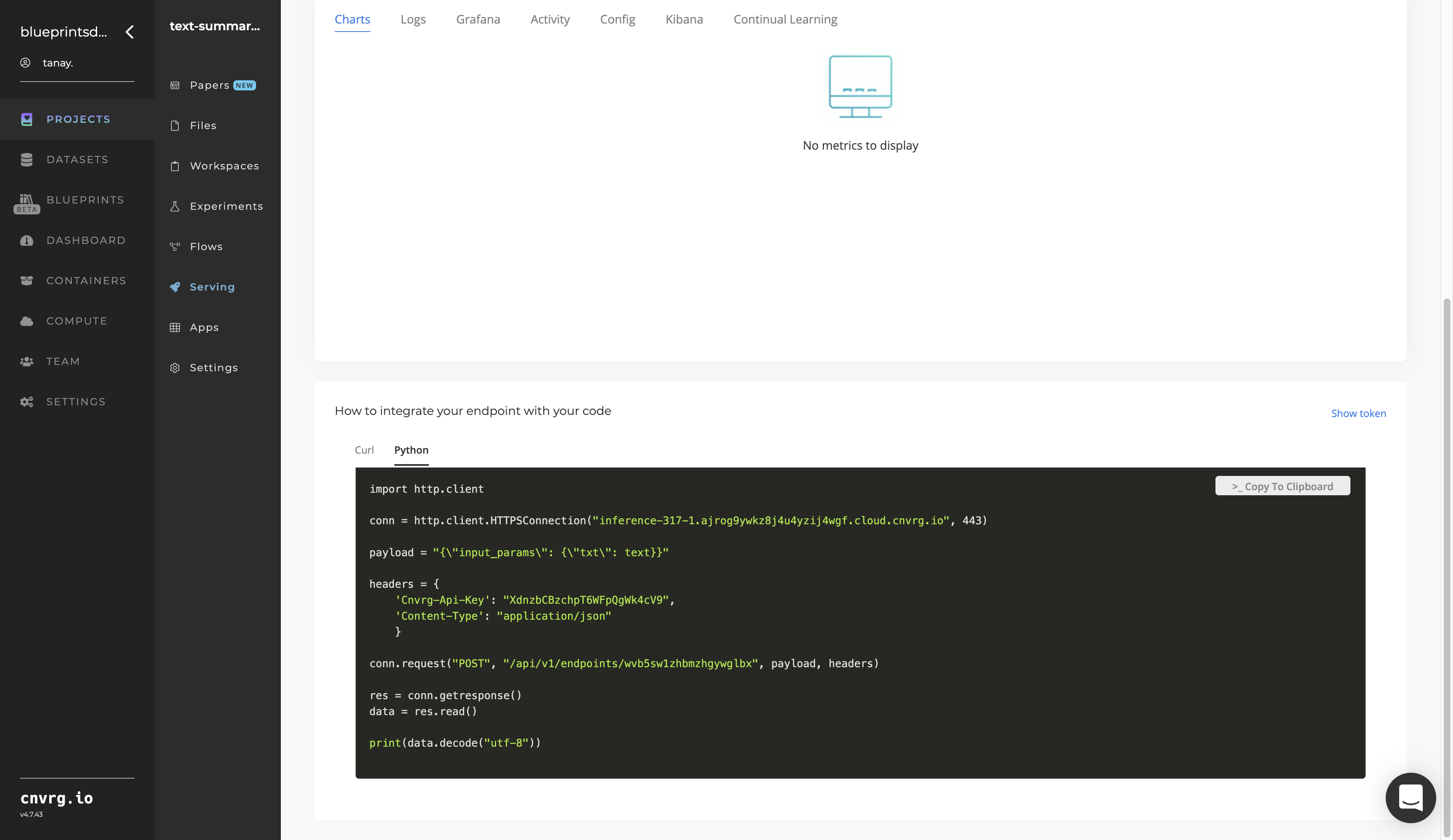
- Use the bottom integration panel to integrate your API with your code by copying in the code snippet.
- Use the Try it Live section with any text to check your model.
An API endpoint that summarizes English text has now been deployed. For information on this blueprint's software version and release details, click here.
# Related Blueprints
Refer to the following blueprints related to this inference blueprint:
# Training
Text summarization is a process of creating a fluent, concise, and continuous summary from large textual paragraphs and passages while preserving main ideas, key points, and important information.
# Overview
The following diagram provides an overview of this blueprint’s inputs and outputs.
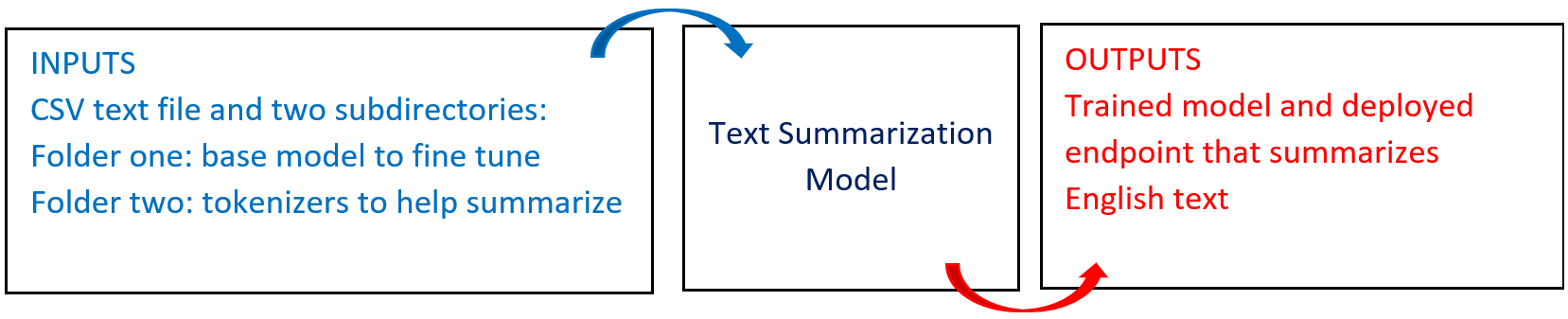
# Purpose
Use this training blueprint to train a custom model that can summarize Wikipedia articles and custom textual paragraphs to short sentences using the BERT model. This blueprint also establishes an endpoint that can be used to summarize paragraphs based on the newly trained model.
To train this model with your data, create a summarization folder in the S3 Connector that comprises the training file in CSV format containing text to be summarized (optional). Also, include two subdirectories that contain the model and tokenizer files, namely:
default_model− A folder with the base model to fine-tune to obtain the custom modeltokenizer− A folder with the tokenizer files to use to assist in text summarization
NOTE
This documentation uses the Wikipedia connection and subsequent summarization as an example. The users of this blueprint can select any source of text and input it to the Batch Predict task.
# Deep Dive
The following flow diagram illustrates this blueprint’s pipeline:
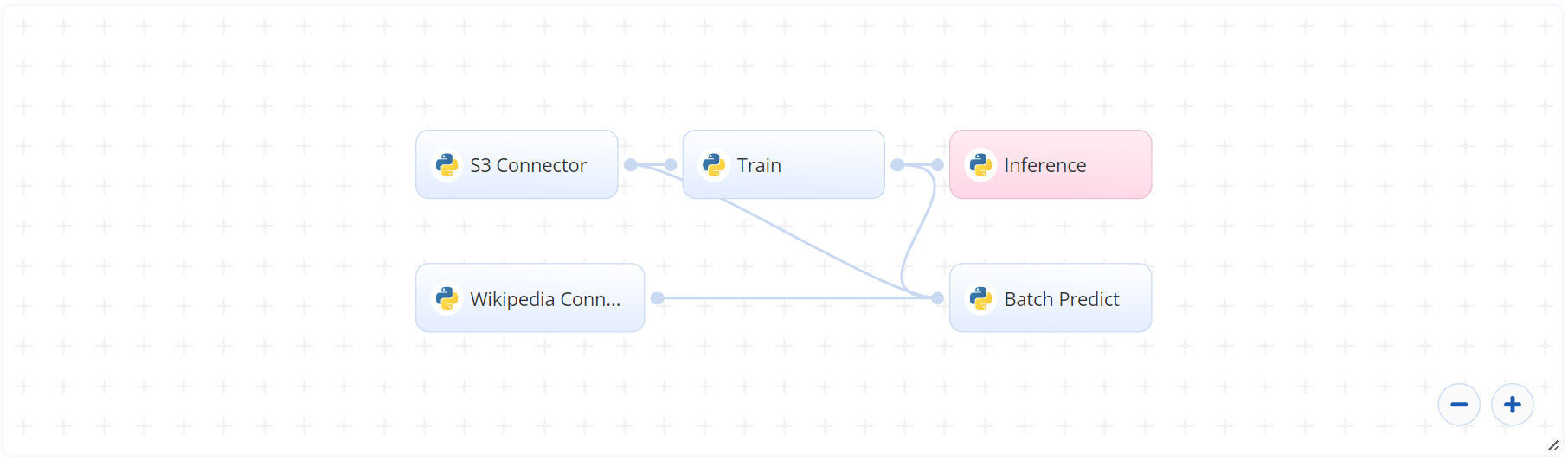
# Flow
The following list provides a high-level flow of this blueprint’s run:
- In the S3 Connector, provide the data bucket name and the path to the training data file and two subfolders, with one folder containing the base model and another containing the tokenizers.
- In the Train task, provide the
training_filepath and two subfolderdefault_modeland tokenizer paths, all with the same previous S3 prefix. - In the Wikipedia task, provide the Wikipedia
topicsto extract, in the format of text, tabular, or URL link. - In the Batch Predict task, provide the
input_path,modelpath, andtokenizerpaths to the Wikipedia Connector’s output CSV file, the Train task’s custom model (or user-specified custom model location), and the S3 Connector’s tokenizer files, respectively.
# Arguments/Artifacts
For more information and examples of this blueprint's tasks, its inputs, and outputs, click here.
# Train Inputs
--training_fileis the name of the file and its path which contains the user’s model-training data or the customwiki_linguadataset. It looks like this:training_data/wiki_lingua_file.csv, wheretraining_datais the name of the dataset. This CSV file has two columns:- the first with a document header and cell(s) below containing the article (titled document)
- the second with a summary header and cell(s) below containing the summary
--train_rowsis the number of rows of either thewiki_linguadataset or the custom-user dataset on which the model is trained. NOTE: The cnvrg team recommends <500 rows for faster results.--tokenizerare the tokenizer files to be used to generate the summary, which can be trained alongside model, but isn't trained in this blueprint.--default_modelis the modelbart_large_cnnon which the training is performed.--encoder_max_lengthis the maximum length into which the data is encoded.--decoder_max_lengthis the maximum length into which the model decodes the encoded sequences.--label_smooth_factoris the factor that smooths the labels. Zero means no label smoothing. Otherwise, the underlying one-hot-encoded labels are changed from 0s and 1s,label_smoothing_factor/num_labelsandlabel_smoothing_factor + label_smoothing_factor/num_labels, respectively.--weight_decay_factoris the factor that regularizes and shrinks the weights during backpropagation to help prevent overfitting the training data and exploding the gradient problem.
# Train Outputs
my_custom_modelis the name of the folder that contains the files for the mode.
# Wikipedia Connector Inputs
topicsis a list of topics to extract from Wikipedia. Its input format is flexible, which can be either comma-separated text, a tabular CSV file format, or a URL link.
# Wikipedia Connector Outputs
--wiki_output.csvis the two-column output CSV file that contains the text in a text-title format.
# Instructions
NOTE
The minimum resource recommendations to run this blueprint are 3.5 CPU and 8 GB RAM.
NOTE
This blueprint’s performance can benefit from using GPU as its compute.
Complete the following steps to train the text-summarizer model:
Click the Use Blueprint button. The cnvrg Blueprint Flow page displays.
In the flow, click the S3 Connector task to display its dialog.
- Within the Parameters tab, provide the following Key-Value pair information:
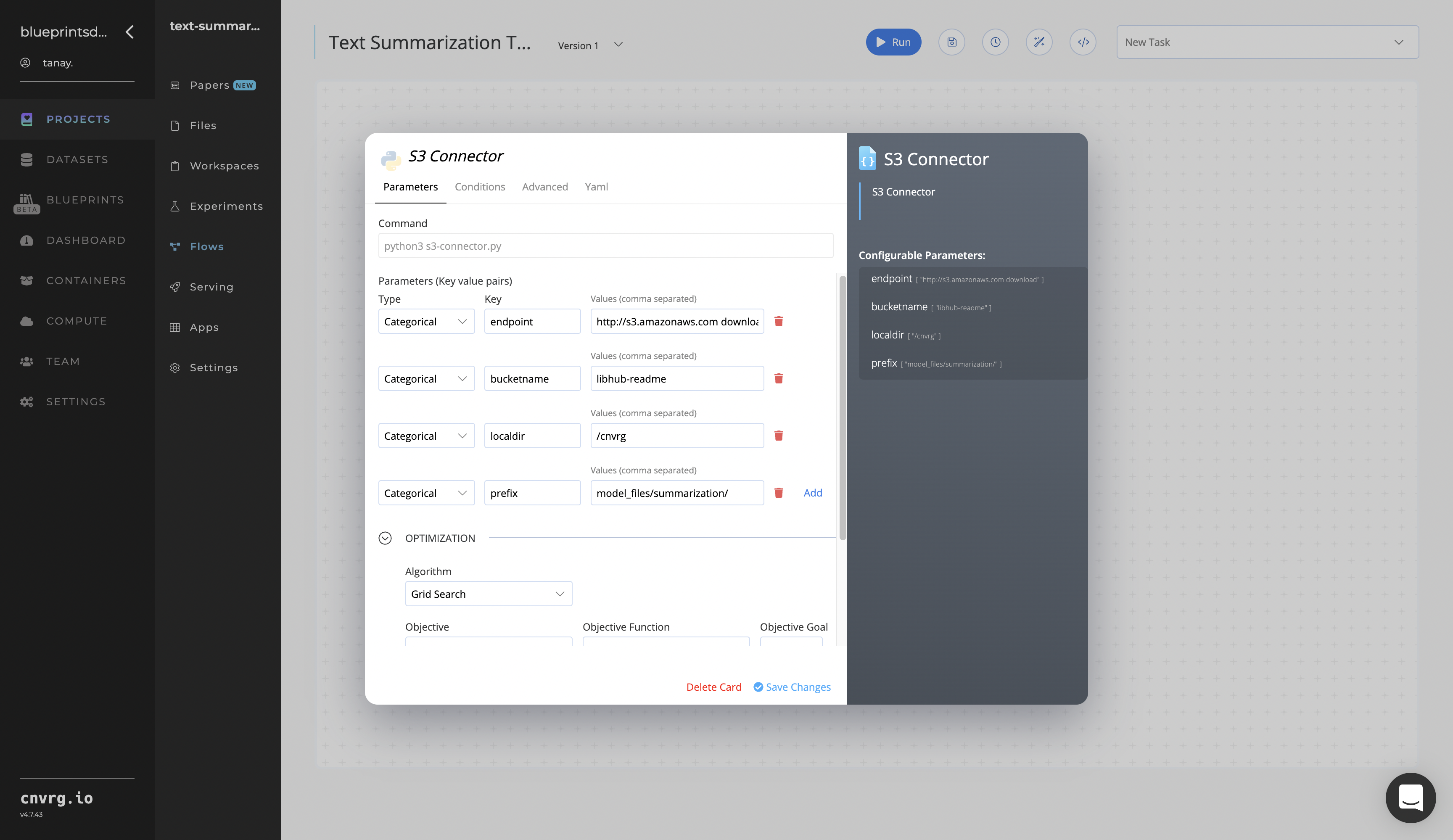
- Key:
bucketname− Value: enter the data bucket name - Key:
prefix− Value: provide the main path to the images folder
- Key:
- Click the Advanced tab to change resources to run the blueprint, as required.
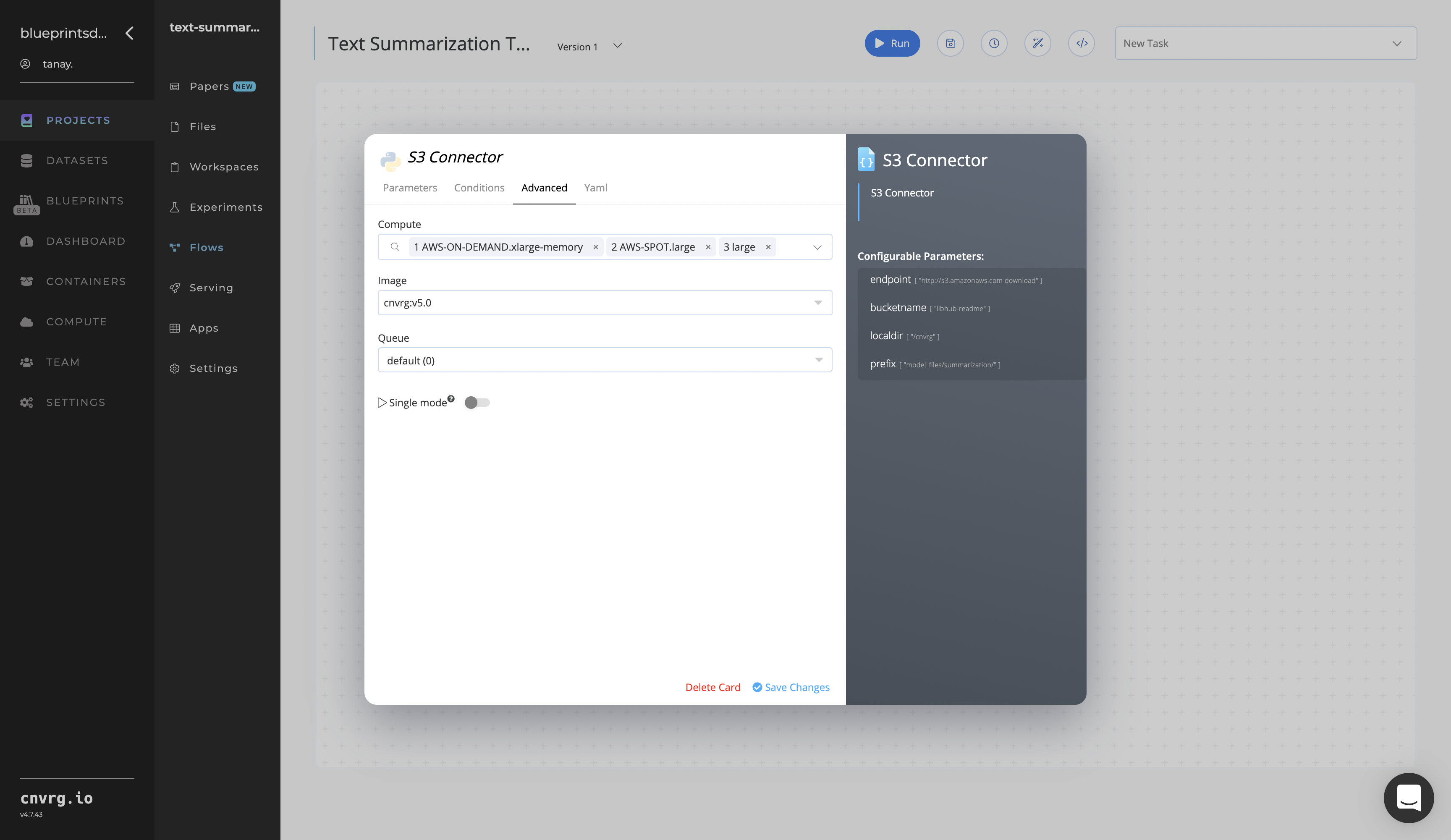
- Within the Parameters tab, provide the following Key-Value pair information:
Return to the flow and click the Train task to display its dialog.
Within the Parameters tab, provide the following Key-Value pair information:
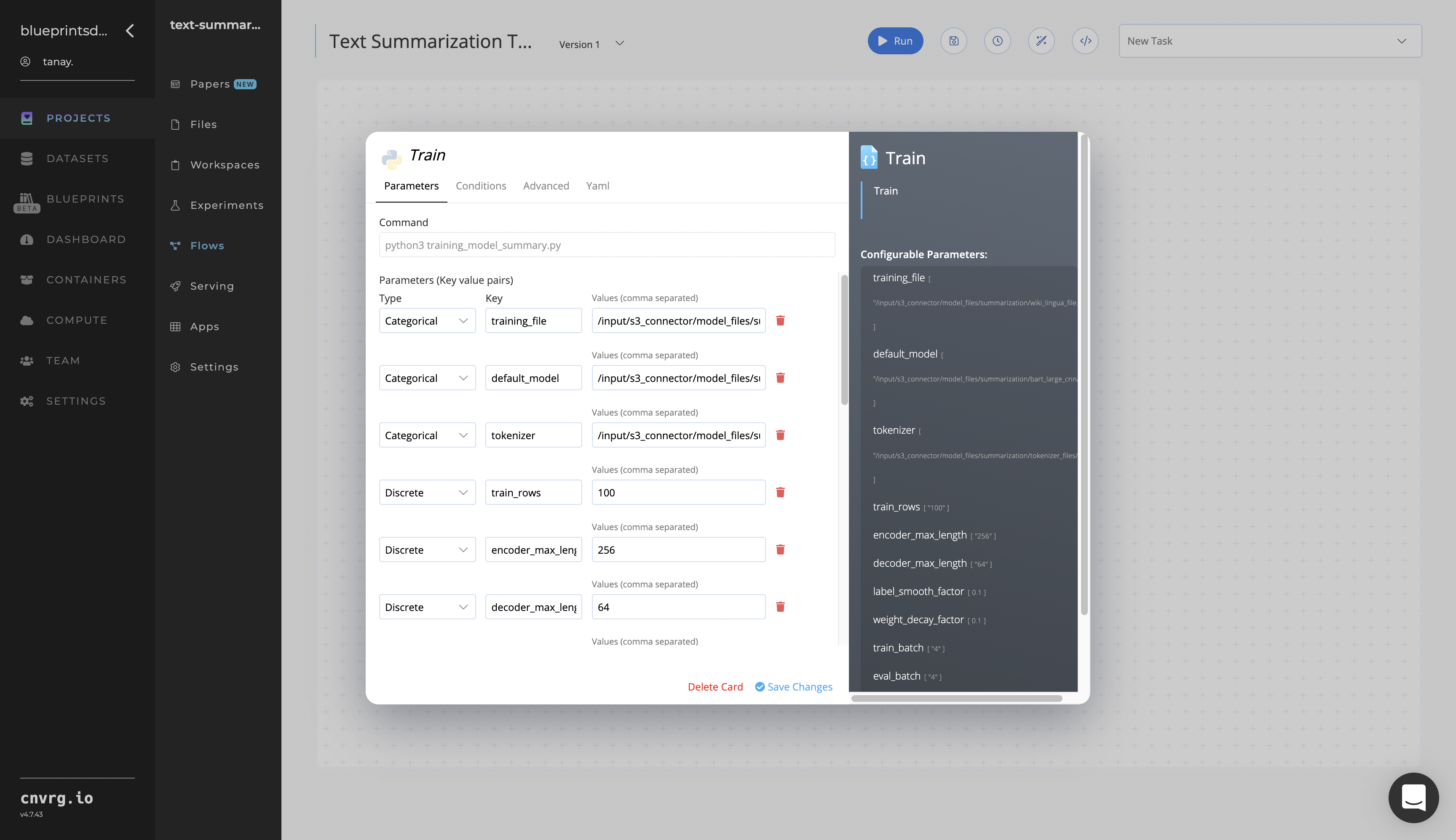
- Key:
training_file− Value: provide the path to the CSV file including the S3 prefix in the following format:/input/s3_connector/<prefix>/wiki_lingua_file.csv - Key:
default_model− Value: provide the path to the base model including the S3 prefix in the following format:/input/s3_connector/<prefix>/bart_large_cnn - Key:
tokenizer− Value: provide the path to the tokenizer files including the S3 prefix in the following format:/input/s3_connector/<prefix>/tokenizer_files
NOTE
You can use the prebuilt example data paths provided.
- Key:
Click the Advanced tab to change resources to run the blueprint, as required.
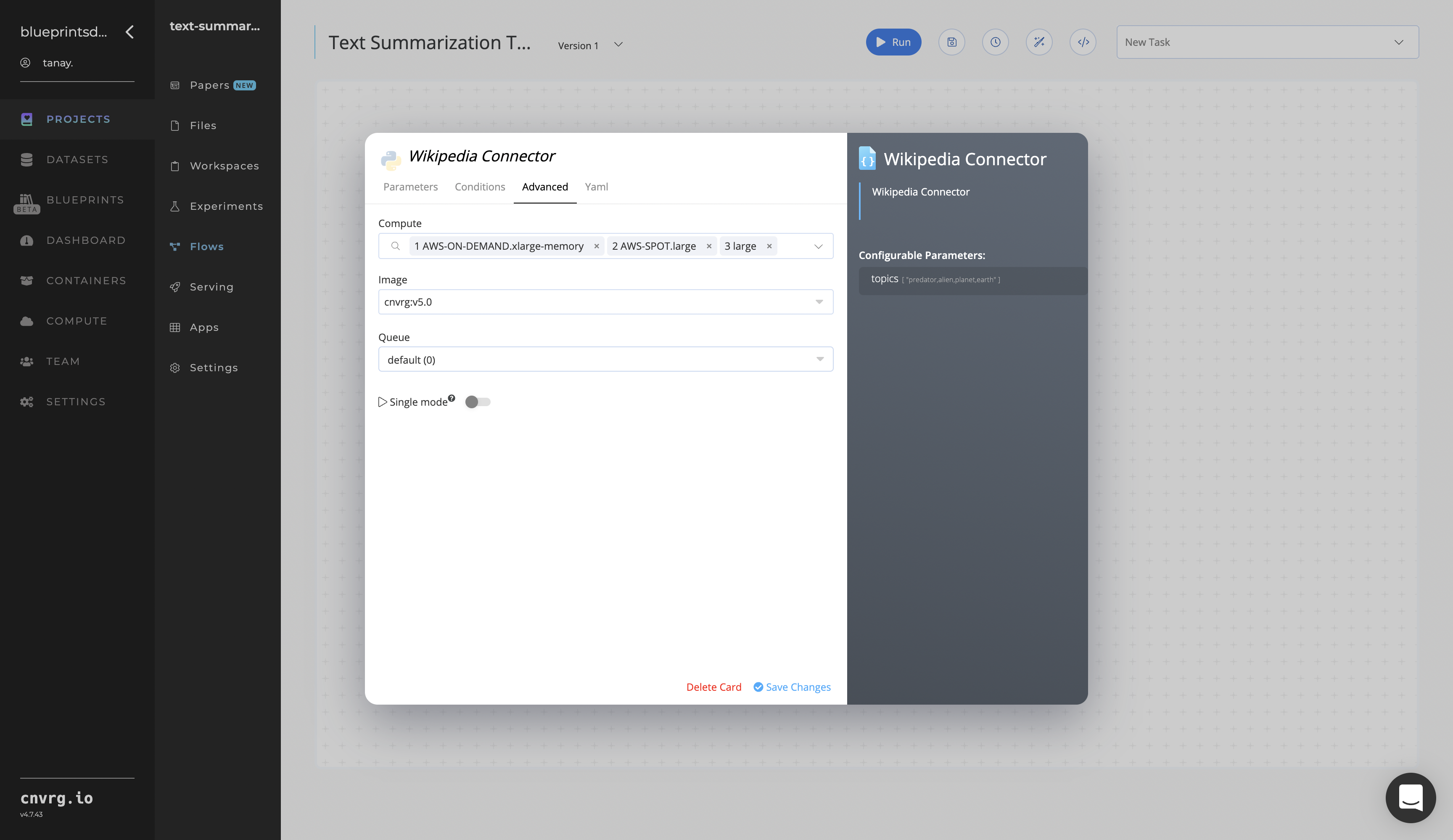
Click the Wikipedia Connector task to display its dialog.
- Within the Parameters tab, provide the following Key-Value pair information:
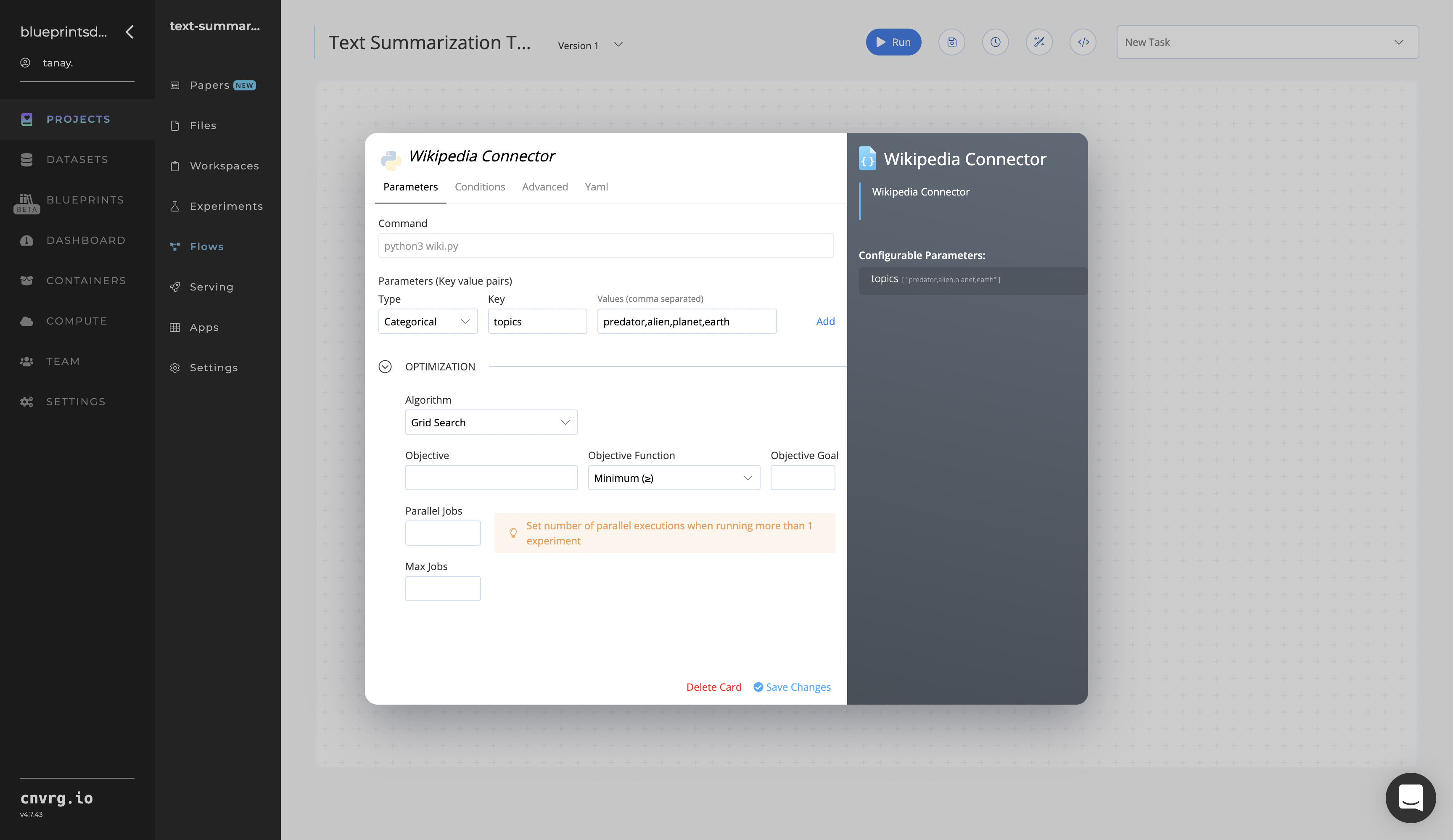
- Key:
topics− Value: provide the topics to extract from Wikipedia - Format − provide the
topicsvalue in one of the following three flexible formats: comma-separated text (shown), tabular CSV, or URL link
- Key:
- Click the Advanced tab to change resources to run the blueprint, as required.
- Within the Parameters tab, provide the following Key-Value pair information:
Click the Batch Predict task to display its dialog.
Within the Parameters tab, provide the following Key-Value pair information:
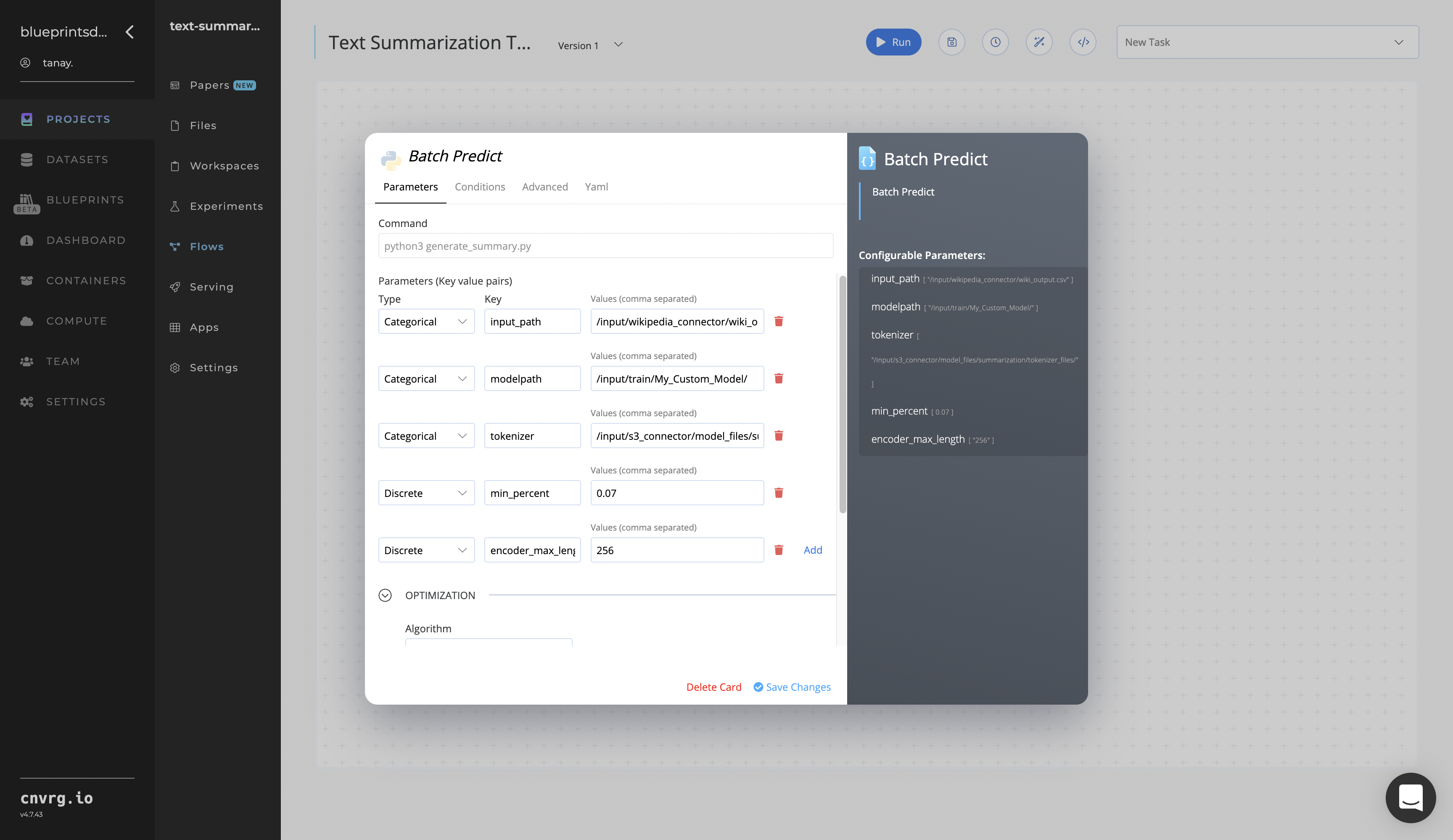
- Key:
input_path− Value: provide the path to the Wikipedia Connector’s output CSV file in the following format:/input/wikipedia_connector/wiki_ output.csv - Key:
modelpath− Value^: provide the path to the Train task’s custom model in the following format:/input/train/my_custom_model - Key:
tokenizer− Value: provide the path to the S3 Connector’s tokenizer files including in the following format:/input/s3_connector/model_files
^NOTE
The Value for the
modelpathKey can also point to a user-defined model, not just the one trained in the Train task.NOTE
You can use the prebuilt example data paths provided.
- Key:
Click the Advanced tab to change resources to run the blueprint, as required.
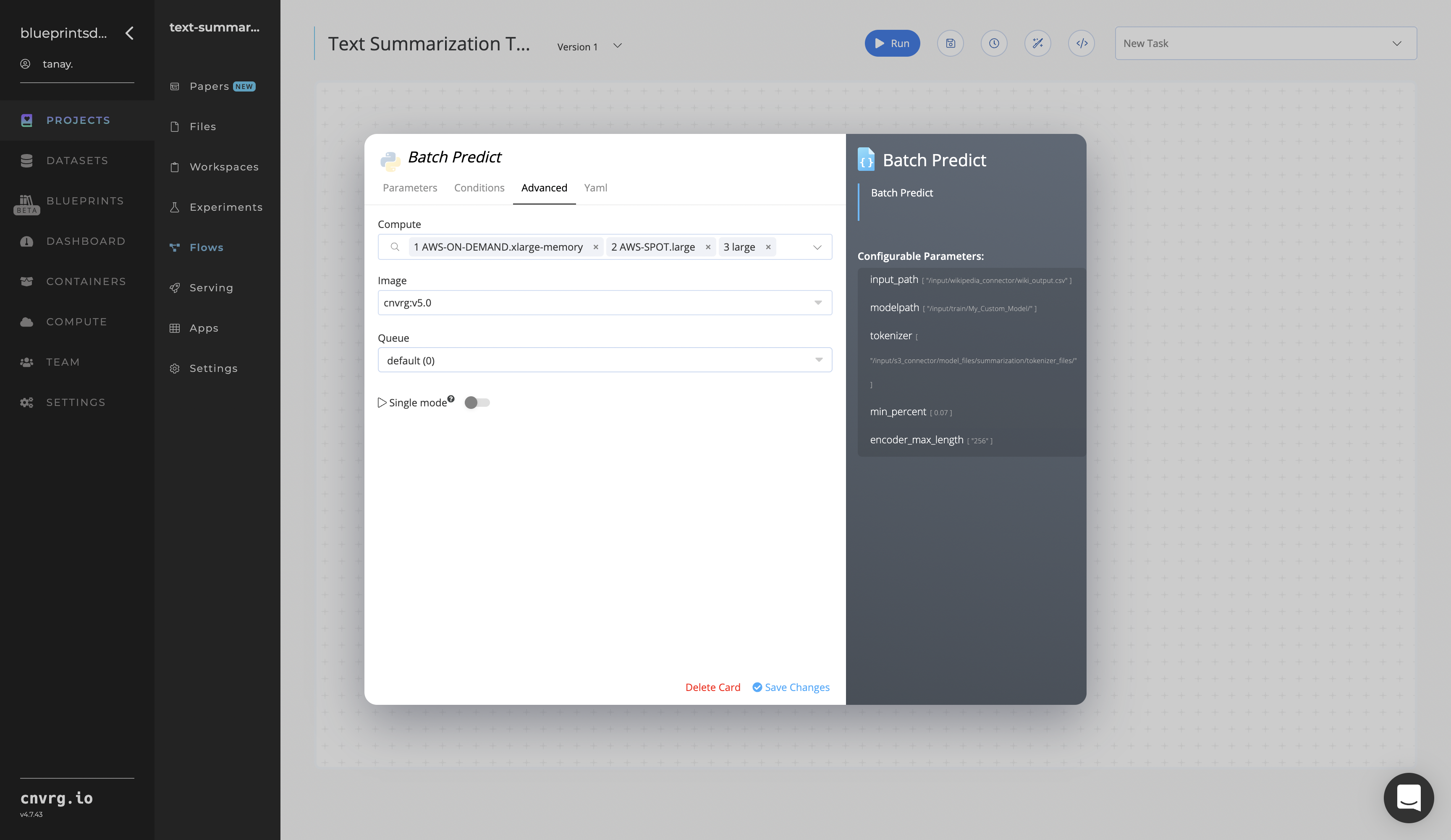
Click the Run button.
 The cnvrg software launches the training blueprint as set of experiments, generating a trained text-summarizer model and deploying it as a new API endpoint.
The cnvrg software launches the training blueprint as set of experiments, generating a trained text-summarizer model and deploying it as a new API endpoint.NOTE
The time required for model training and endpoint deployment depends on the size of the training data, the compute resources, and the training parameters.
For more information on cnvrg endpoint deployment capability, see cnvrg Serving.
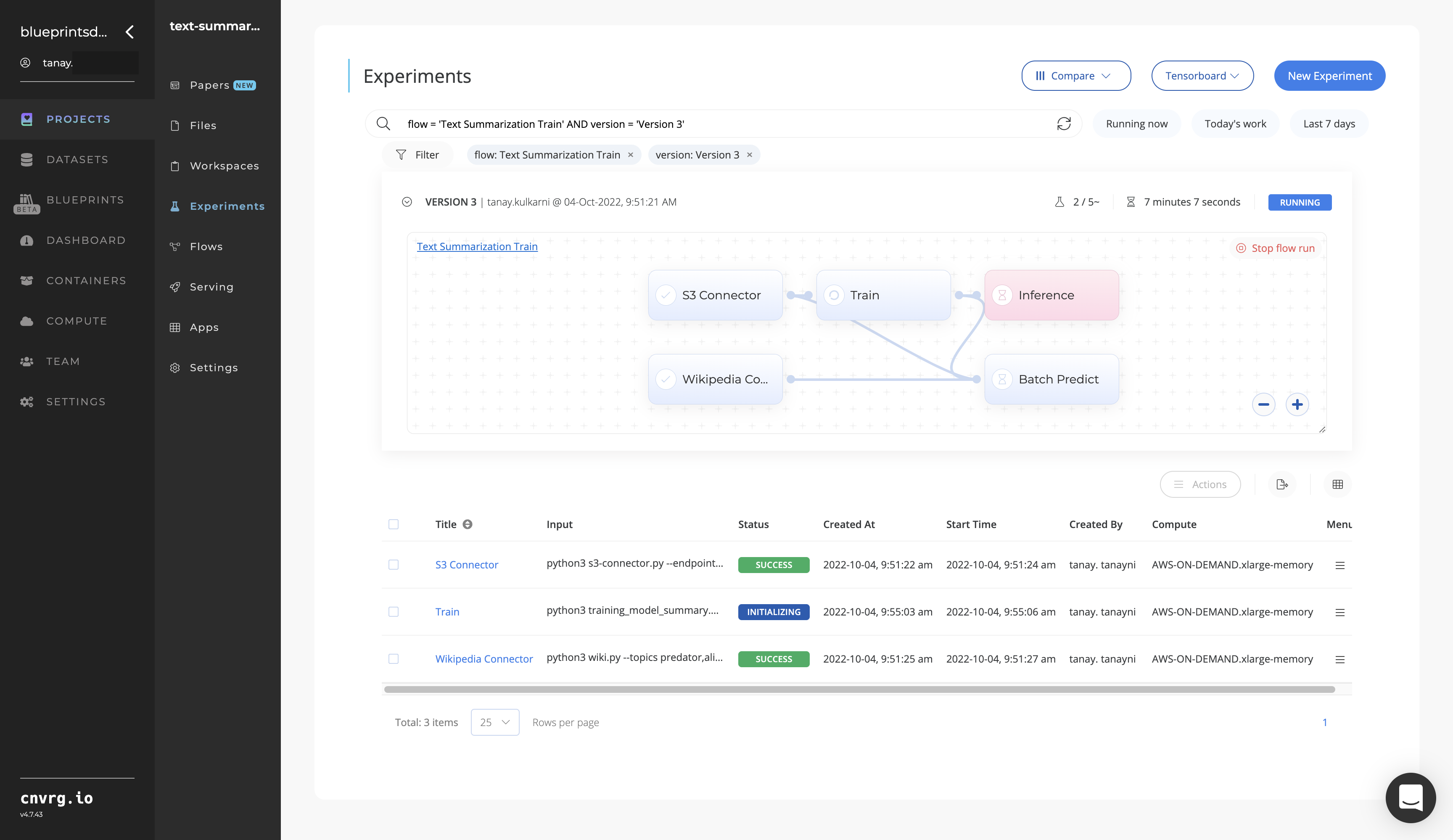
Track the blueprint's real-time progress in its Experiments page, which displays artifacts such as logs, metrics, hyperparameters, and algorithms.
Click the Serving tab in the project and locate your endpoint.
Complete one or both of the following options:
- Use the Try it Live section with any text to check the model’s ability to summarize.
- Use the bottom integration panel to integrate your API with your code by copying in your code snippet.
- Use the Try it Live section with any text to check the model’s ability to summarize.
A custom model and API endpoint, which can summarize text, have now been trained and deployed. If using the Batch Predict task, a custom text-summarizer model has now been deployed in batch mode. For information on this blueprint's software version and release details, click here.
# Connected Libraries
Refer to the following libraries connected to this blueprint:
- S3 Connector
- Wikipedia Connector
- Text Summarization Train
- Text Summarization Batch
- Text Summarization Inference
# Related Blueprints
Refer to the following blueprints related to this training blueprint: