# Topic Modeling AI Blueprint - deprecated from 11/2024
# Batch-Predict
Topic modeling uses a trained model to analyze and classify textual data and organize similar words and phrases over a set of paragraphs or documents to identify related text chunks or topics. The model can also be trained to determine whether text is relevant to the identified topics. Topic modeling models scan large amounts of text, locate word and phrase patterns, and cluster similar words, related expressions, and abstract topics that best represent the textual data.
# Blueprint Purpose
Use this batch blueprint to predict topics from custom textual data by using the vectorizer and model files from earlier training runs. For more information on training topic-prediction models, see this counterpart’s training blueprint.
To use this blueprint, provide one folder in the S3 Connector containing the files on which to predict topics.
# Deep Dive
The following flow diagram illustrates this batch-predict blueprint’s pipeline:
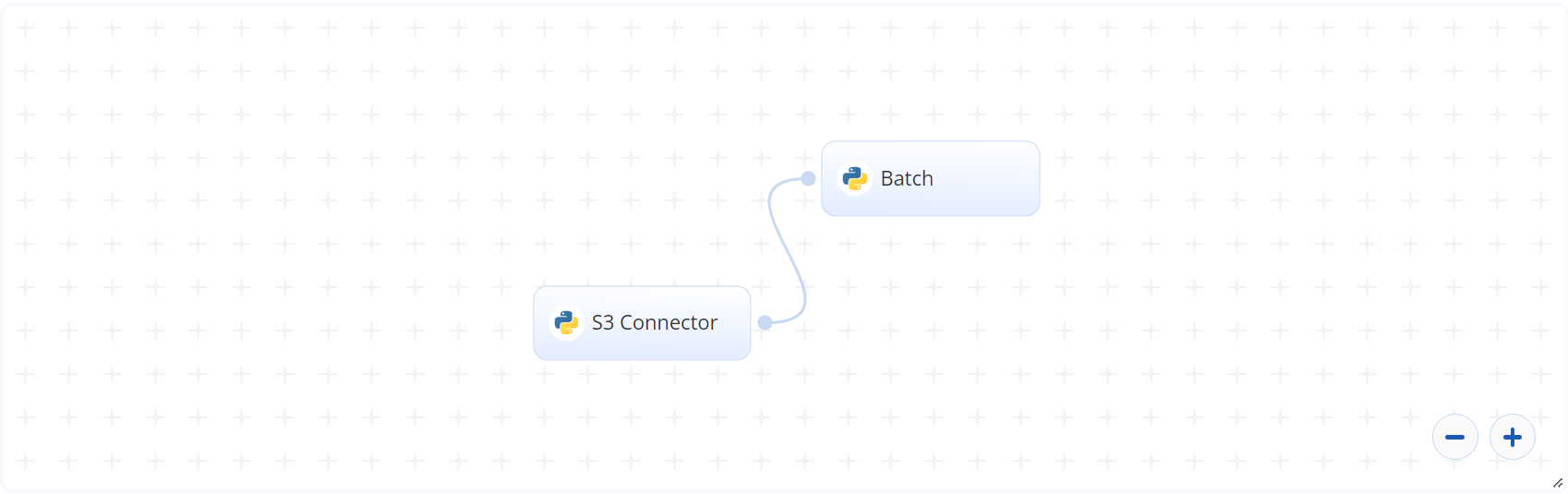
# Flow
The following list provides a high-level flow of this blueprint’s run:
- In the S3 Connector, the user uploads the CSV file containing custom text stored row-wise within the file.
- The user also downloads the number of topics, the model, and the vectorizer from a previous experiment and uploads them to the S3 Connector.
- In the Batch task, the user provides locations for
--input_file,--modelpath,--vectorizer, and--topic_df. - The blueprint outputs a single CSV file with the topics and their probabilities of custom text fitting to them.
# Arguments/Artifacts
For more information on this blueprint’s tasks, its inputs, and outputs, click here.
# Inputs
--input_fileis the name of the path of the directory that stores the files requiring classification.--modelpathis the S3 location containing the pretrained-NMF model. Click here for more information.--vectorizeris the S3 location containing the pretrained vectorizer.--topic_dfis the S3 location containing the CSV file with the various topics within the model.
# Outputs
--batch_topic_output.csv is the name of the output file that lists the documents, their topics, and their probabilities. An example output.csv file can be found here.
# Instructions
NOTE
The minimum resource recommendations to run this blueprint are 3.5 CPU and 8 GB RAM.
Complete the following steps to run the topic-modeling blueprint in batch mode:
- Click the Use Blueprint button. The cnvrg Blueprint Flow page displays.
- Click the S3 Connector task to display its dialog.
- Within the Parameters tab, provide the following Key-Value pair information:
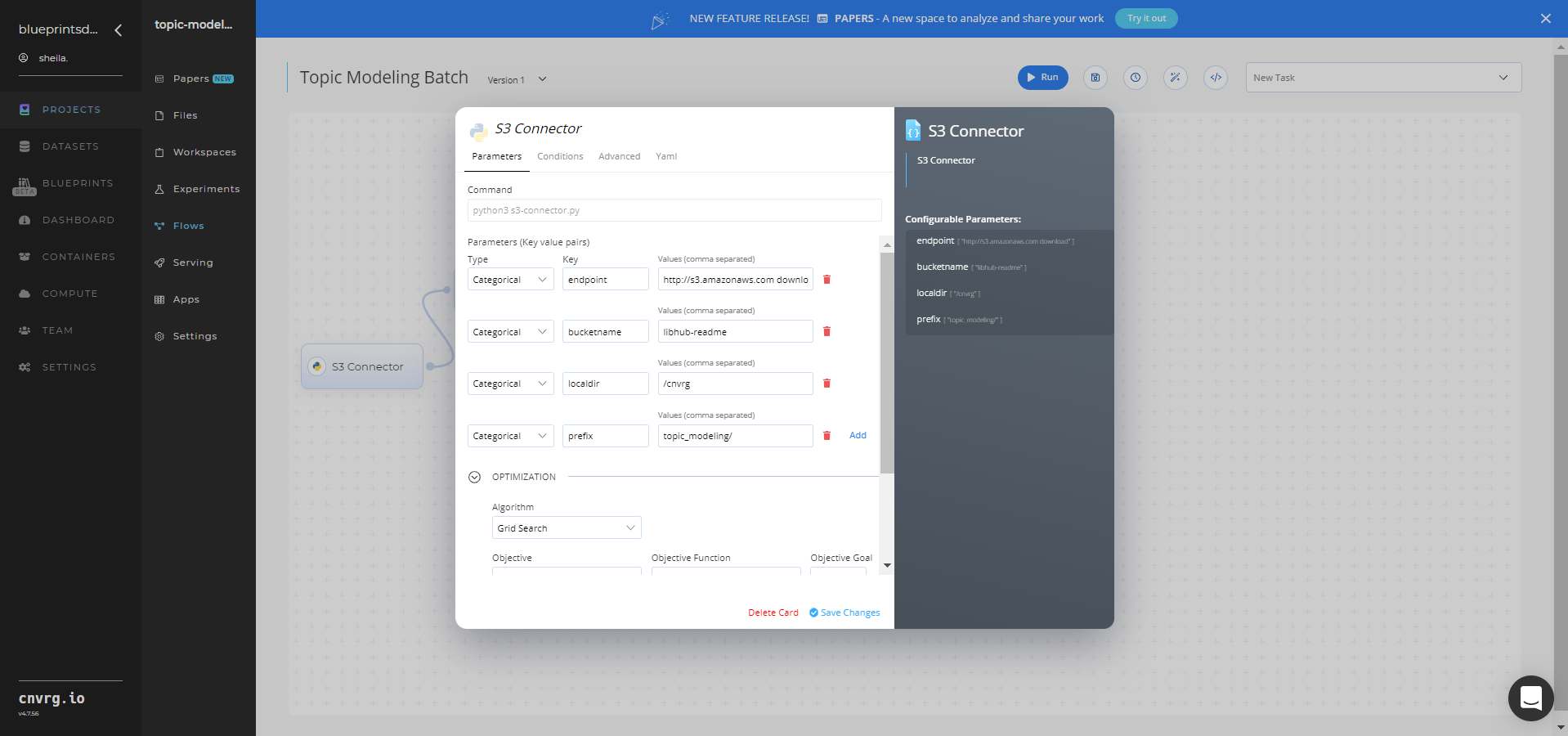
- Key:
bucketname− Value: provide the data bucket name - Key:
prefix− Value: provide the main path to the files folder
- Key:
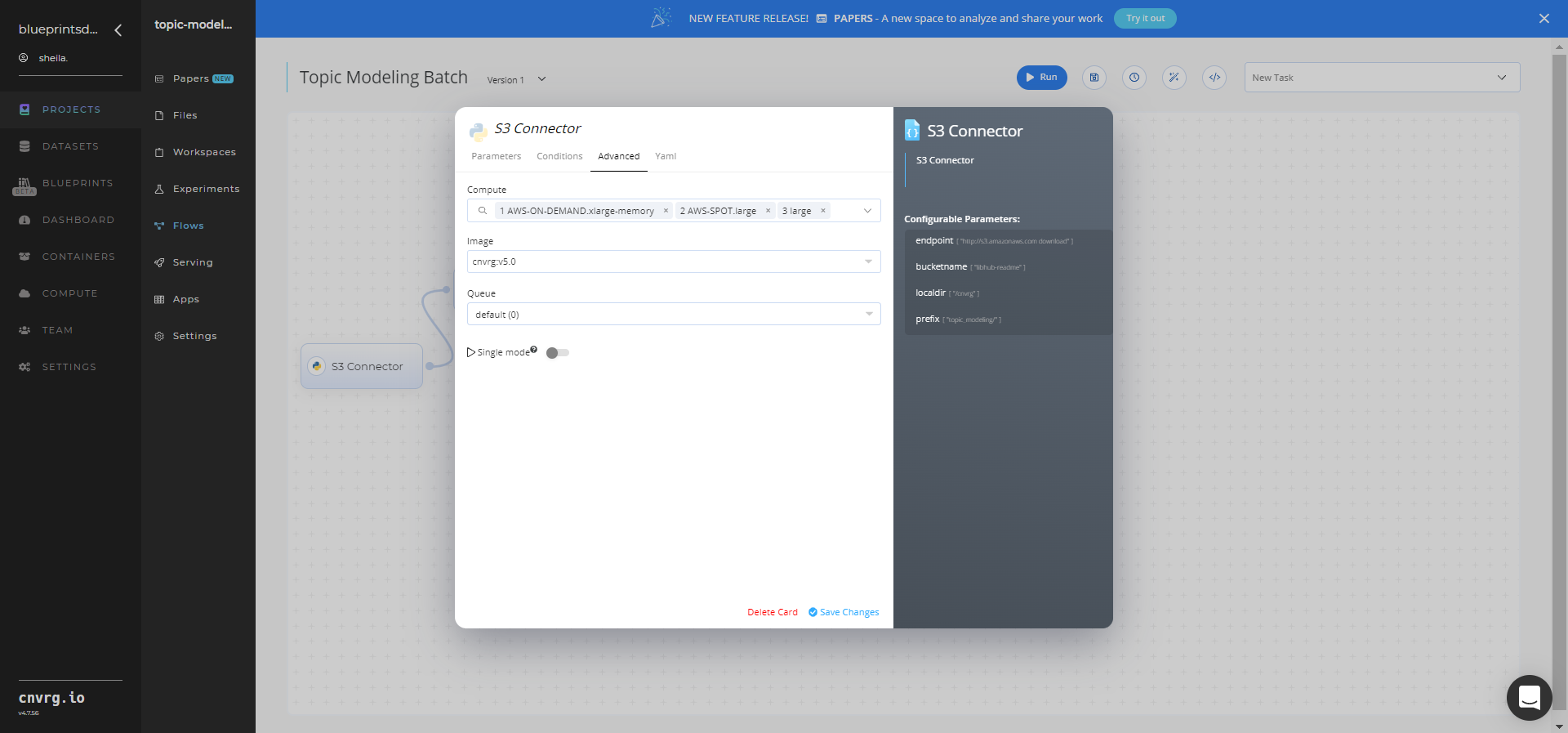
- Click the Advanced tab to change resources to run the blueprint, as required.
- Within the Parameters tab, provide the following Key-Value pair information:
- Click the Batch task to display its dialog.
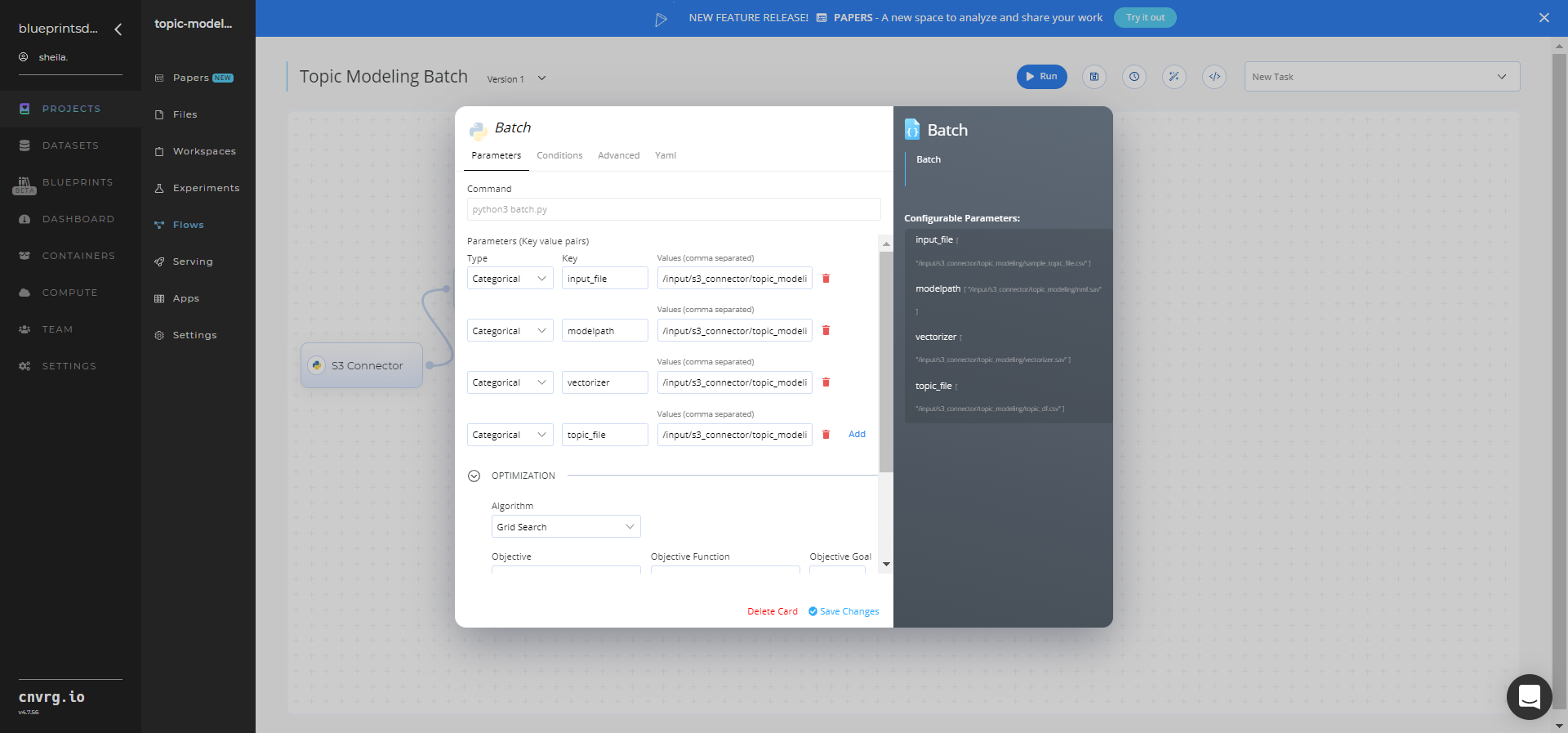
Within the Parameters tab, provide the following Key-Value pair information:
- Key:
--input_file− Value: provide the path to the directory storing the files requiring classification - Key:
--modelpath− Value: provide the S3 location containing the pretrained NMF model - Key:
--vectorizer− Value: provide the S3 location containing the pretrained vectorizer - Key:
--topic_df− Value: provide the S3 location containing the CSV file with the model’s topics
NOTE
You can use prebuilt data example paths provided.
- Key:
Click the Advanced tab to change resources to run the blueprint, as required.
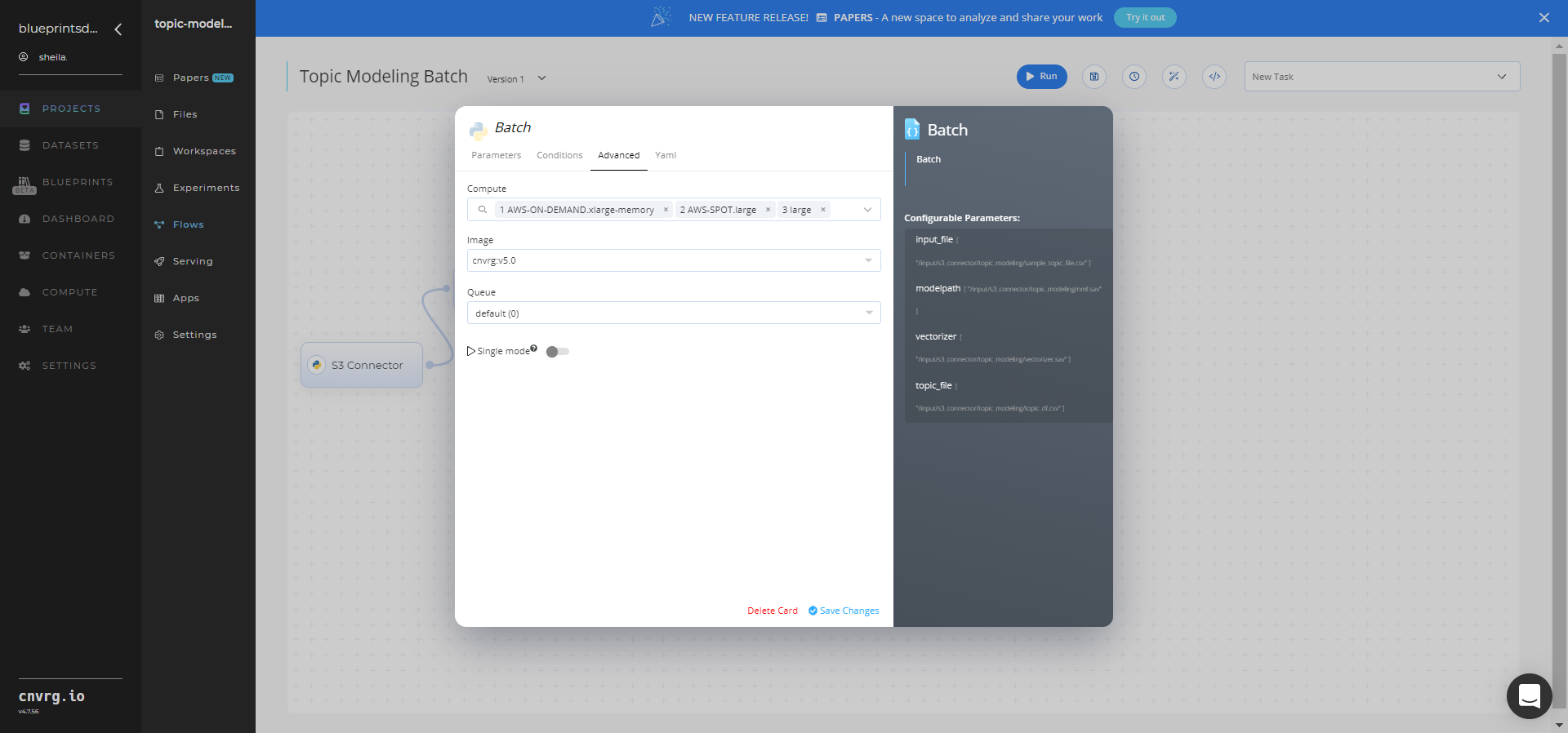
- Click the Run button.
 The cnvrg software deploys topic-modeling model that predicts topics from custom textual data.
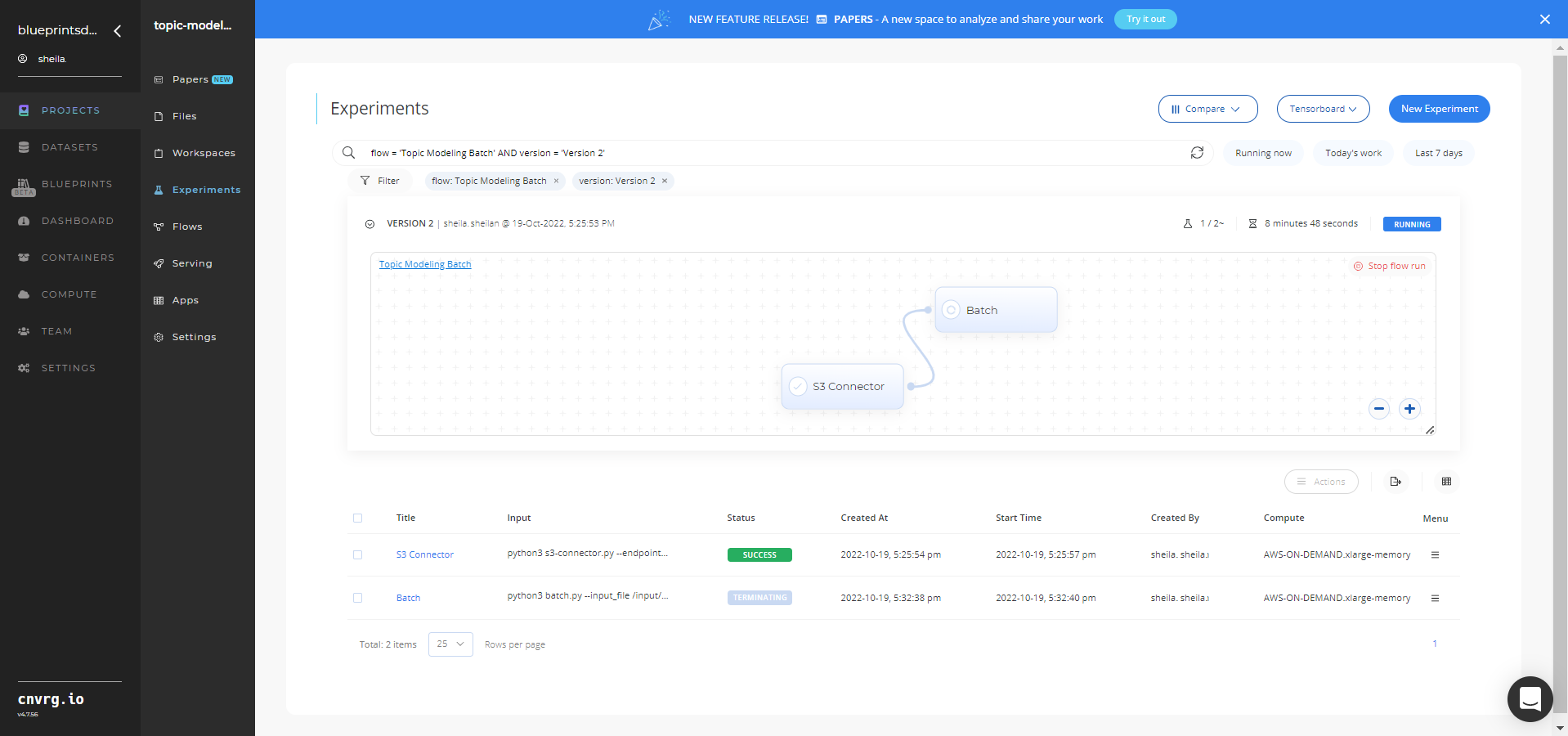
The cnvrg software deploys topic-modeling model that predicts topics from custom textual data. - Track the blueprint’s real-time progress in its Experiments page, which displays artifacts such as logs, metrics, hyperparameters, and algorithms.
- Select Batch > Experiments > Artifacts and locate the batch output CSV file.
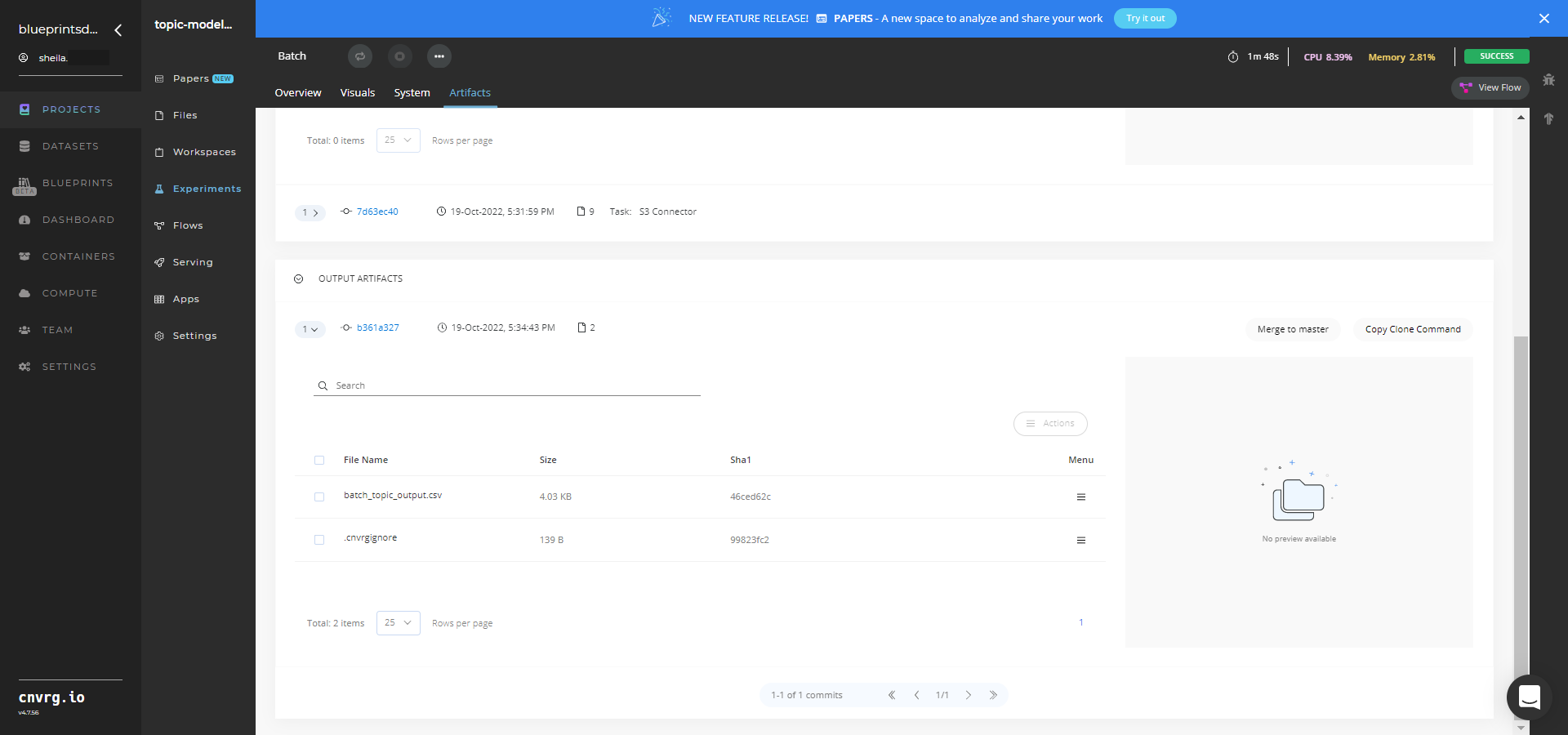
- Select the batch_topic_output.csv File Name, click the right Menu icon, and select Open File to view the output CSV file.
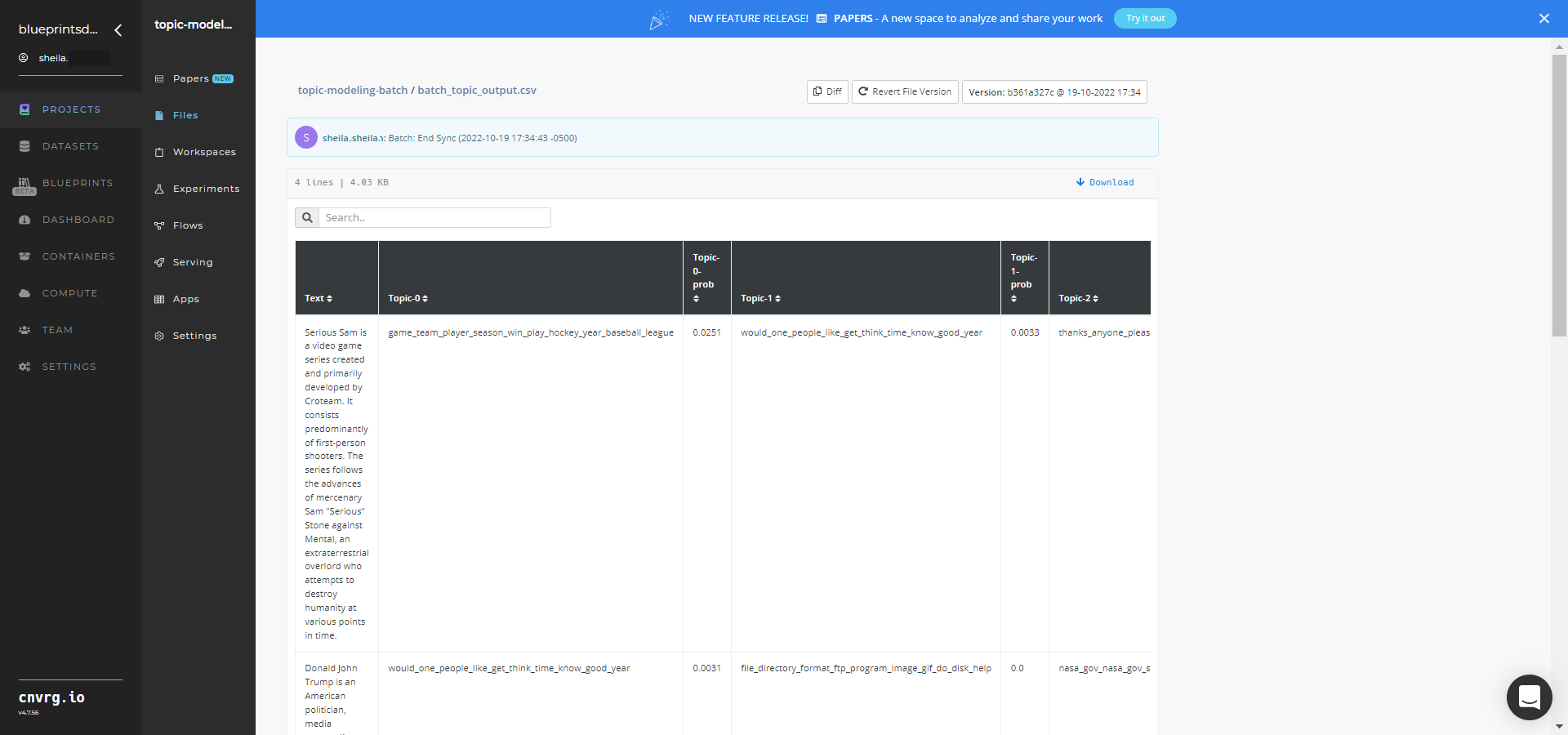
A custom pretrained model that predicts topics from textual data has now been deployed in batch mode. For information on this blueprint's software version and release details, click here.
# Connected Libraries
Refer to the following libraries connected to this blueprint:
# Related Blueprints
Refer to the following blueprints related to this batch blueprint:
- Topic Modeling Inference
- Topic Modeling Train
- Text Summarization Training
- Text Summarization Batch
- Text Summarization Inference
# Inference
Topic modeling uses a trained model to analyze and classify textual data and organize similar words and phrases over a set of paragraphs or documents to identify related text chunks or topics. The model can also be trained to determine whether text is relevant to the identified topics. Topic modeling models scan large amounts of text, locate word and phrase patterns, and cluster similar words, related expressions, and abstract topics that best represent the textual data.
# Purpose
Use this inference blueprint to identify topics that occur in textual data. To use this pretrained topic-extractor model, create a ready-to-use API endpoint that can be quickly integrated with your data and application.
This inference blueprint’s model was trained using data from Scikit 20 newsgroups dataset. To use custom data according to your specific business, run this counterpart’s training blueprint, which trains the model and establishes an endpoint based on the newly trained model.
# Instructions
NOTE
The minimum resource recommendations to run this blueprint are 3.5 CPU and 8 GB RAM.
Complete the following steps to deploy a topic-extractor API endpoint:
Click the Use Blueprint button.
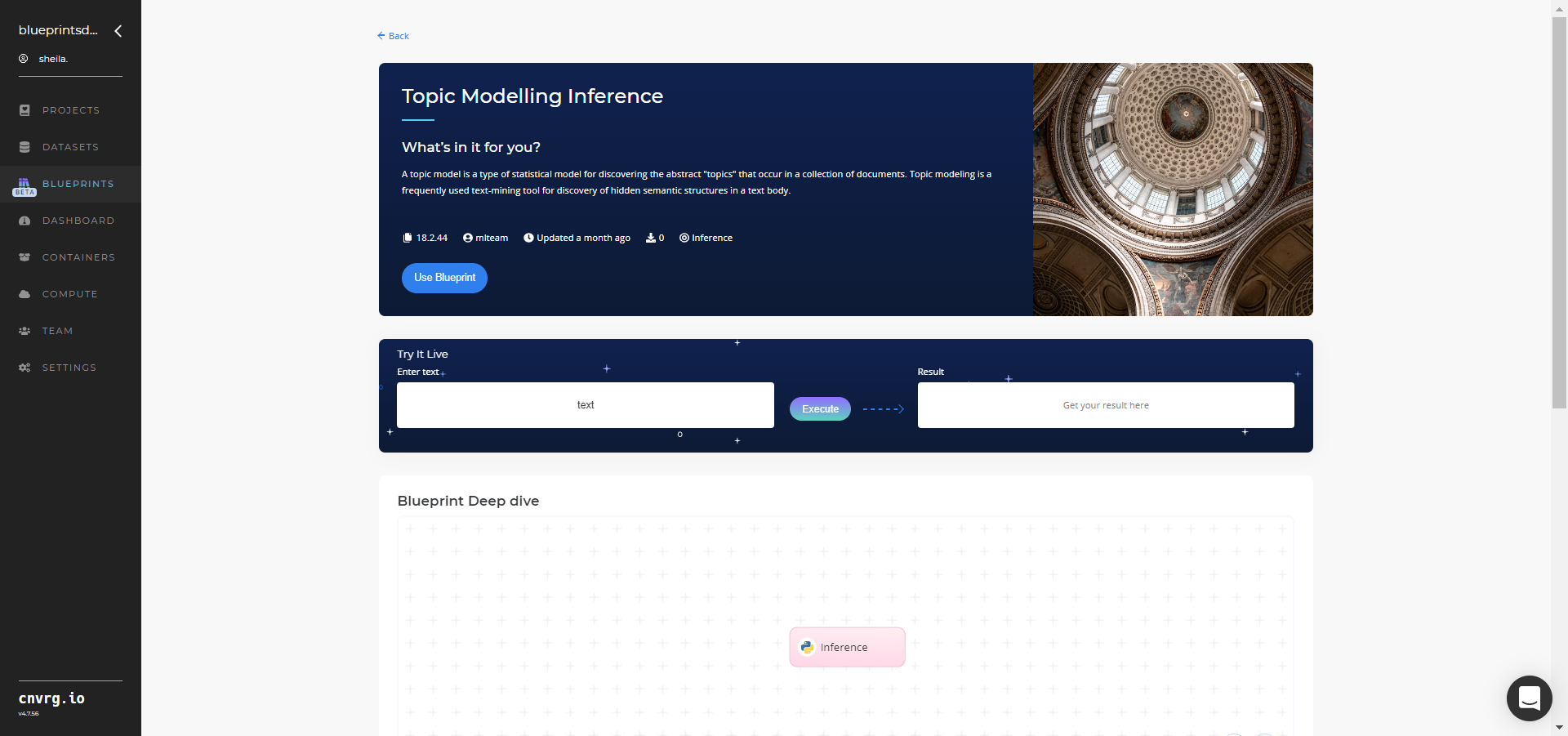
In the dialog, select the relevant compute to deploy the API endpoint and click the Start button.
The cnvrg software redirects to your endpoint. Complete one or both of the following options:
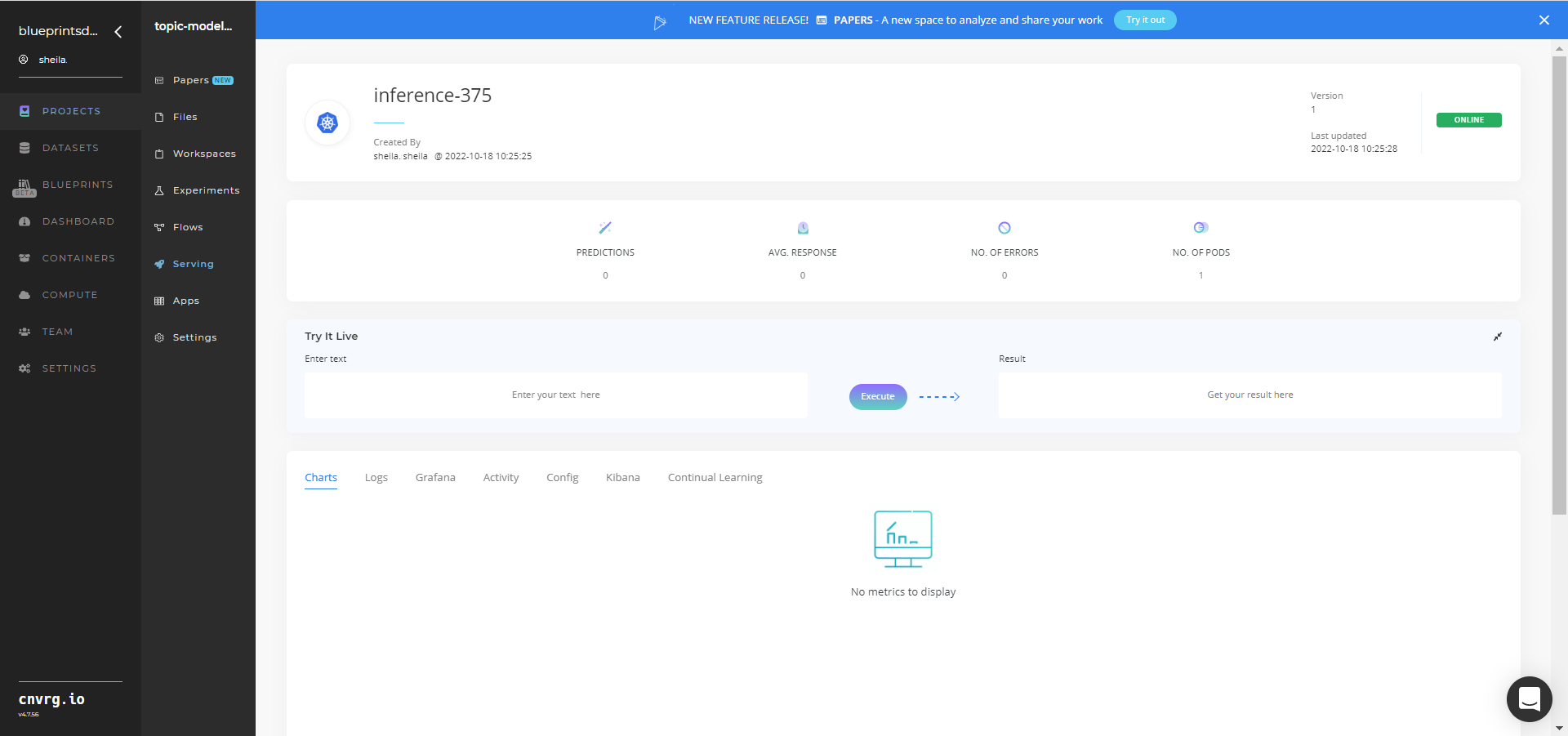
- Use the Try it Live section with any text to check the model.
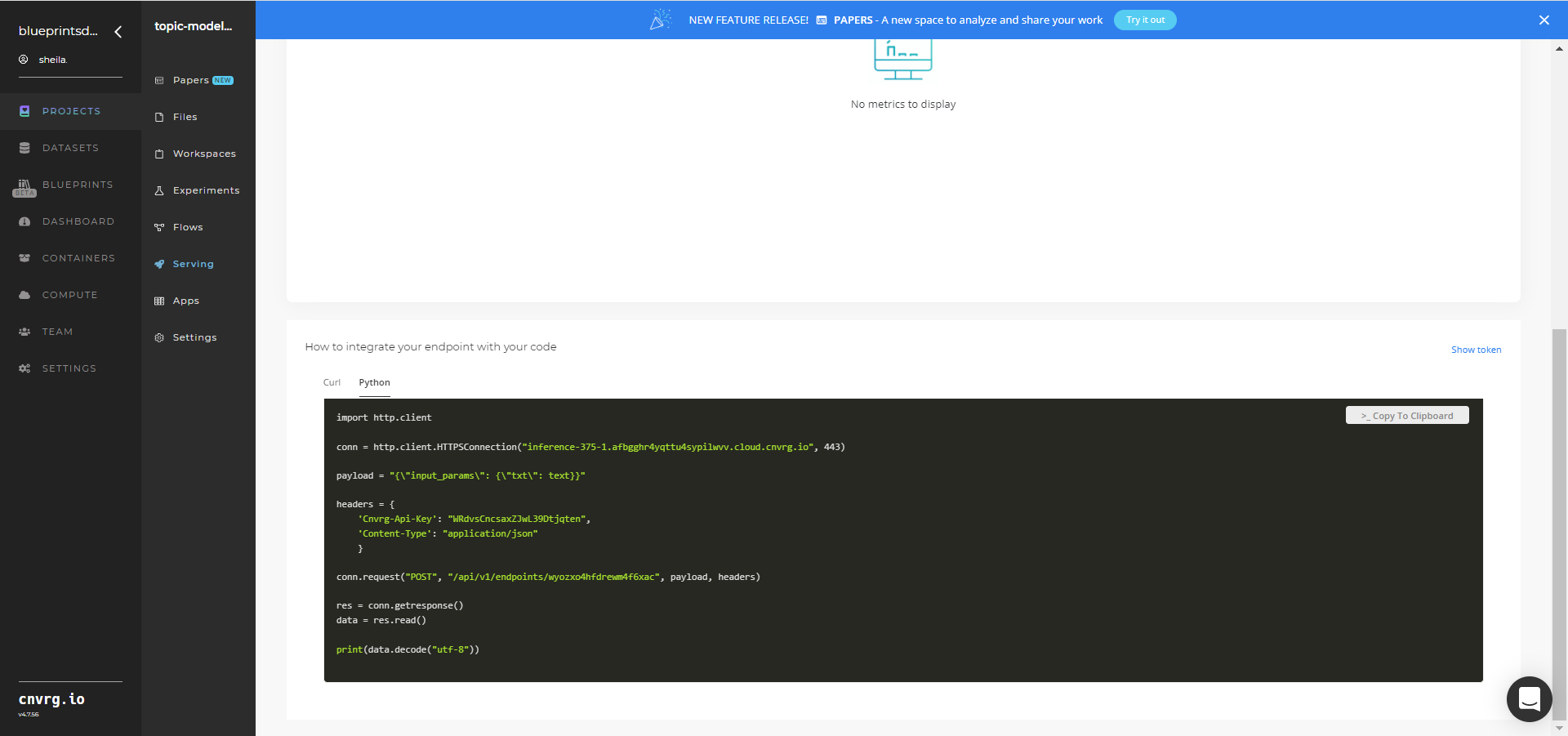
- Use the bottom integration panel to integrate your API with your code by copying in the code snippet.
- Use the Try it Live section with any text to check the model.
An API endpoint that can extract text topics has now been deployed. For information on this blueprint's software version and release details, click here.
# Related Blueprints
Refer to the following blueprints related to this inference blueprint:
- Topic Modeling Training
- Topic Modeling Batch
- Text Summarization Training
- Text Summarization Batch
- Text Summarization Inference
# Training
Topic modeling uses a trained model to analyze and classify textual data and organize similar words and phrases over a set of paragraphs or documents to identify related text chunks or topics. The model can also be trained to determine whether text is relevant to the identified topics. Topic-modeling models scan large amounts of text, locate word and phrase patterns, and cluster similar words, related expressions, and abstract topics that best represent the textual data.
# Overview
The following diagram provides an overview of this blueprint’s inputs and outputs.
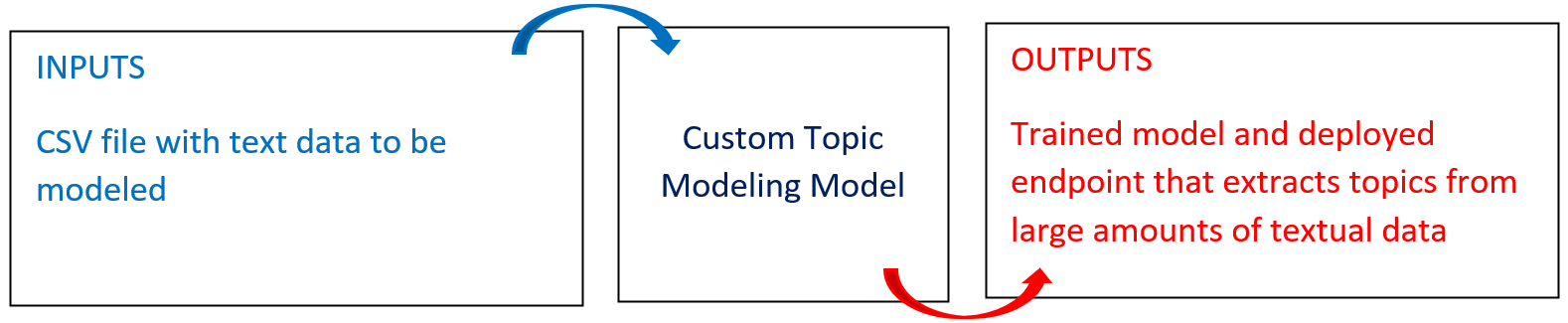
# Purpose
Use this training blueprint with custom data to train a topic-extractor model that extracts key topics out of any paragraph or document. To train this model with your data, create a folder located in the S3 Connector that contains the topic_modeling file, which stores the text to be decomposed (modeled). This blueprint also establishes an endpoint that can be used to extract topics from textual data based on the newly trained model.
# Deep Dive
The following flow diagram illustrates this blueprint’s pipeline:
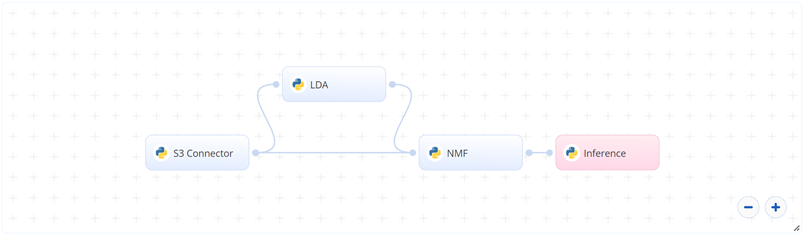
# Flow
The following list provides a high-level flow of this blueprint’s run:
- In the S3 Connector, the user provides the data bucket name and the directory path to the CSV file.
- In the LDA task, the user provides the path to the CSV file including the S3 prefix.
- In the NMF task, the user provides the path to the CSV file including the S3 prefix.
- The blueprint trains the model with the user-provided custom data to extract topics from textual data.
- The user uses the newly deployed endpoint to extract text topics using the newly trained model.
# Arguments/Artifacts
For more information on this blueprint’s tasks, its inputs, and outputs, click here.
# LDA Inputs
For more information on this latent Dirichlet allocation (LDA) task, its inputs, and outputs, click here.
--input_fileis the name of the path of the directory storing the files to be classified.--topic_sizeis a string of three comma-separated values of topic sizes, on which to test the LDA algorithm. The minimum, maximum, and step-size increment the minimum value for testing. The string8,15,2means the values tested are8,10,12,14. It is recommended to use larger step sizes for faster execution.--chunk_sizeis the number of documents to be used in each training chunk. For example, 100 means 100 documents are considered at a time.--passesis the number of times the algorithm is to pass over the whole corpus.--alphasets to an explicit user-defined array. It also supports special values ofasymmetricandauto, with the former using a fixed normalized asymmetric 1.0/topicno prior, and the latter learning an asymmetric prior directly from your data.--etasets to an explicit user-defined array. It also supports special values ofasymmetricandauto, with the former using a fixed normalized asymmetric 1.0/topicno prior, and the latter learning an asymmetric prior directly from your data.
# LDA Outputs
--topics_cnt_file.csv is the two-column (topics_count and coherence) file that contains the mapping of each topic count (such as 6,7,10) with a coherence score. It is sorted so the top count of topics is the one having the highest coherence score.
# NMF Inputs
For more information on this non-negative matrix factorization (NMF) task, its inputs, and outputs, click here.
--input_fileis the name of the path of the directory storing the files to be classified (documents and labels).--topic_cntis number of topics shown for one input data point (some text the user inputs in endpoint), in case the default number isn't needed. This is for purely for inference output.--topic_cnt_ratio(user choice) is the ratio that modifies the optimum number of topics that come from LDA. If the ratio is 0.5, and the optimum number of topics is 10, then the actual number of topics is 5. This is also purely for inference.--topic_cnt_fileis the file containing the optimum number of topics from LDA algorithm. It has only one row and one column.--num_wordsis number of words within a particular topic the user desires.--solveris the numerical solver to use:cdis a coordinate descent andmuis a multiplicative update.--max_iteris the maximum number of iterations before timing out.--alphais a constant that multiplies the regularization terms. Set it to zero to have no regularization. When using alpha instead of alpha_W and alpha_H, the regularization terms are not scaled by the n_features (resp. n_samples) factors for W (resp. H).--|1_ratiois the regularization mixing parameter, with 0 ≤ l1_ratio ≤ 1. For l1_ratio = 0 the penalty is an elementwise L2 penalty (aka Frobenius Norm). For l1_ratio = 1 it is an elementwise L1 penalty. For 0 < l1_ratio < 1, the penalty is a combination of L1 and L2.
# NMF Outputs
--final_df.csvis the file that contains the topics and probabilities.--topic_df.csvis the file that contains the mapping of each topic number with a coherence score.--vectorizer.sav tf-idfis a vectorizer that extracts features from text and is saved after being dumped in previous library.--nmf.sav nmfis a model file from sklearn decomposition library, trained with user's data.topics_cnt_final.csvis the file (ratio and number) containing the user-set number of topics in the output and/or the ratio by which the ideal count of topics (taken from optimizing coherence score) is modified and displayed in the output.
# Instructions
NOTE
The minimum resource recommendations to run this blueprint are 3.5 CPU and 8 GB RAM.
Complete the following steps to train the topic-extractor model:
Click the Use Blueprint button. The cnvrg Blueprint Flow page displays.
In the flow, click the S3 Connector task to display its dialog.
- Within the Parameters tab, provide the following Key-Value pair information:
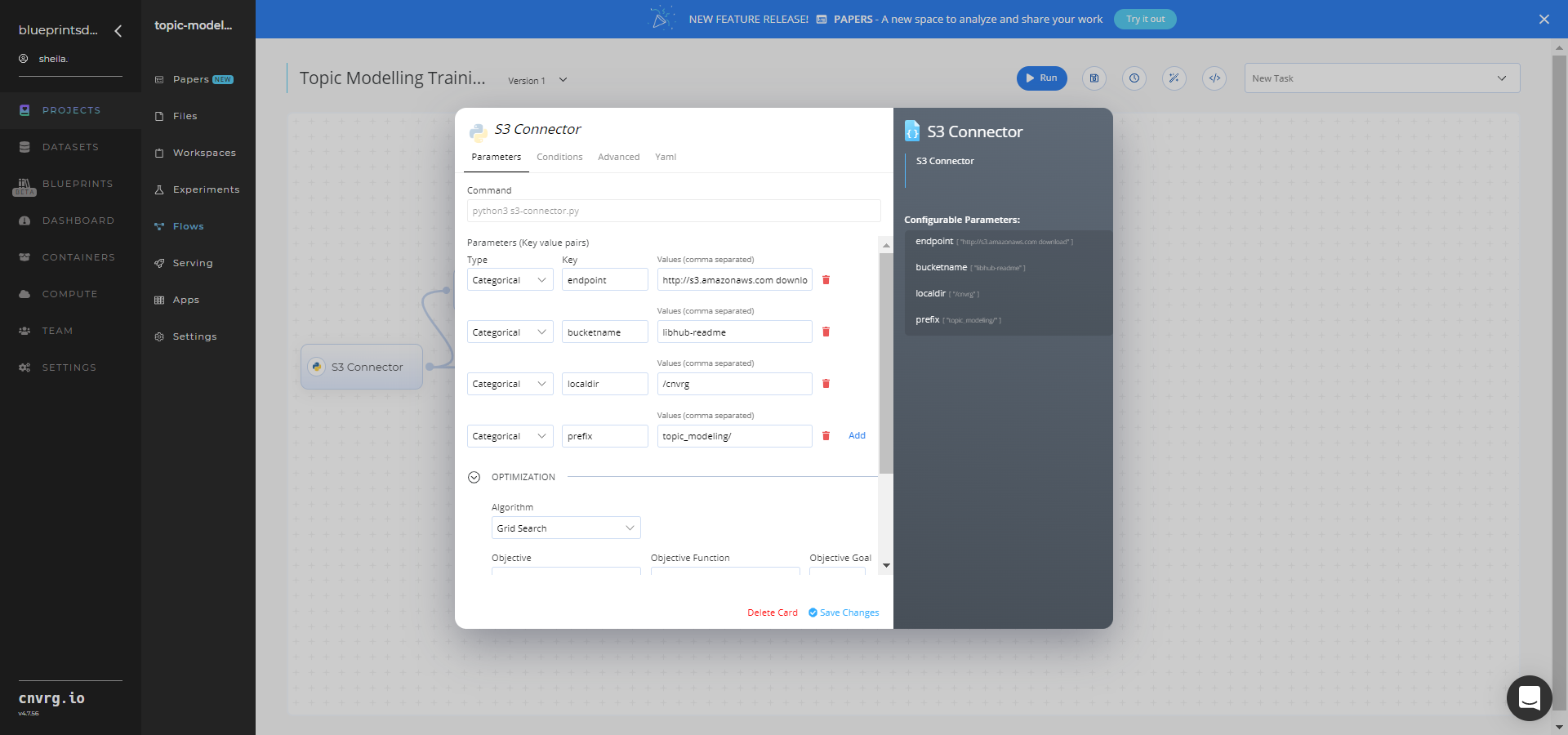
- Key:
bucketname− Value: enter the data bucket name - Key:
prefix− Value: provide the main path to the textual data folder
- Key:
- Click the Advanced tab to change resources to run the blueprint, as required.
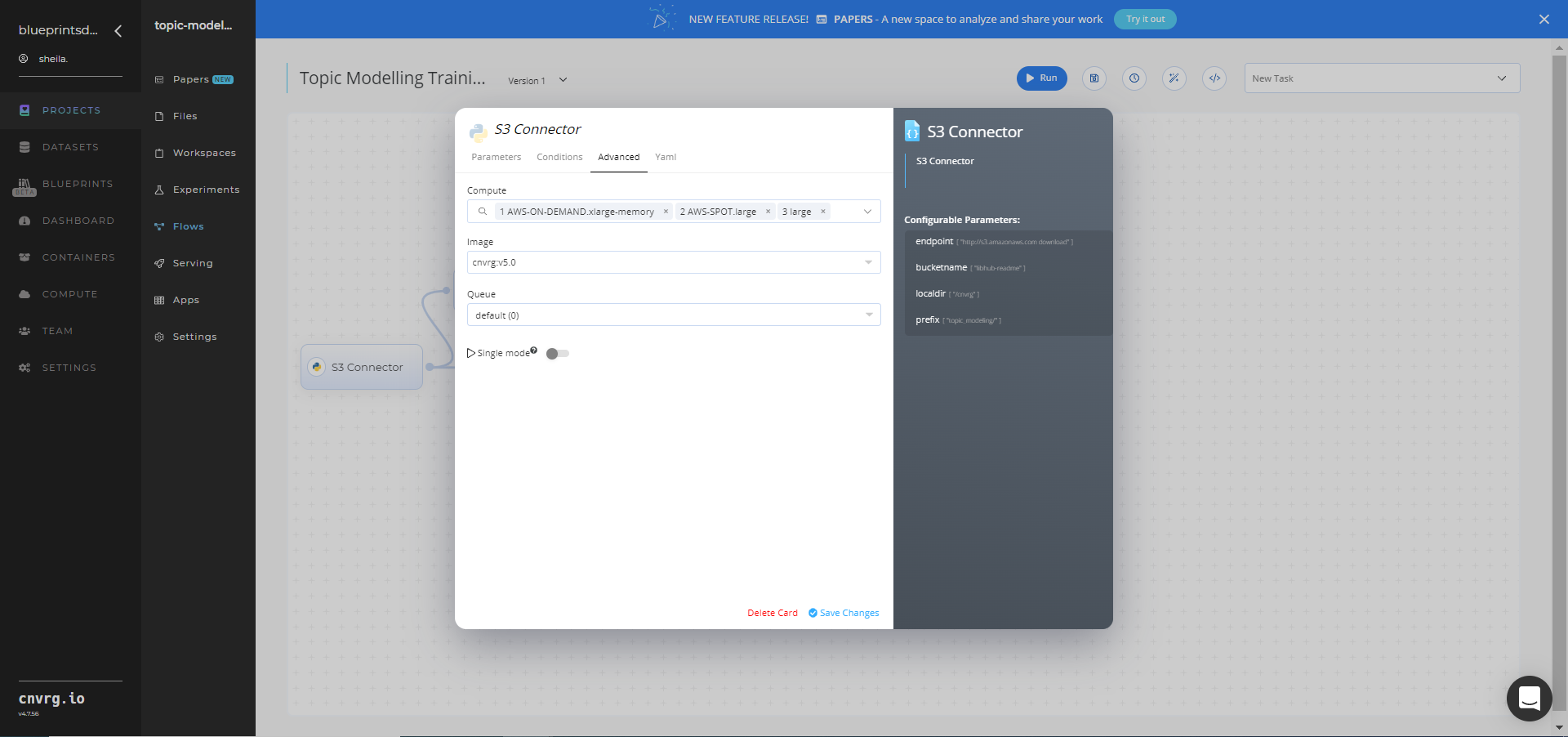
- Within the Parameters tab, provide the following Key-Value pair information:
Click the LDA task to display its dialog.
Within the Parameters tab, provide the following Key-Value pair information:
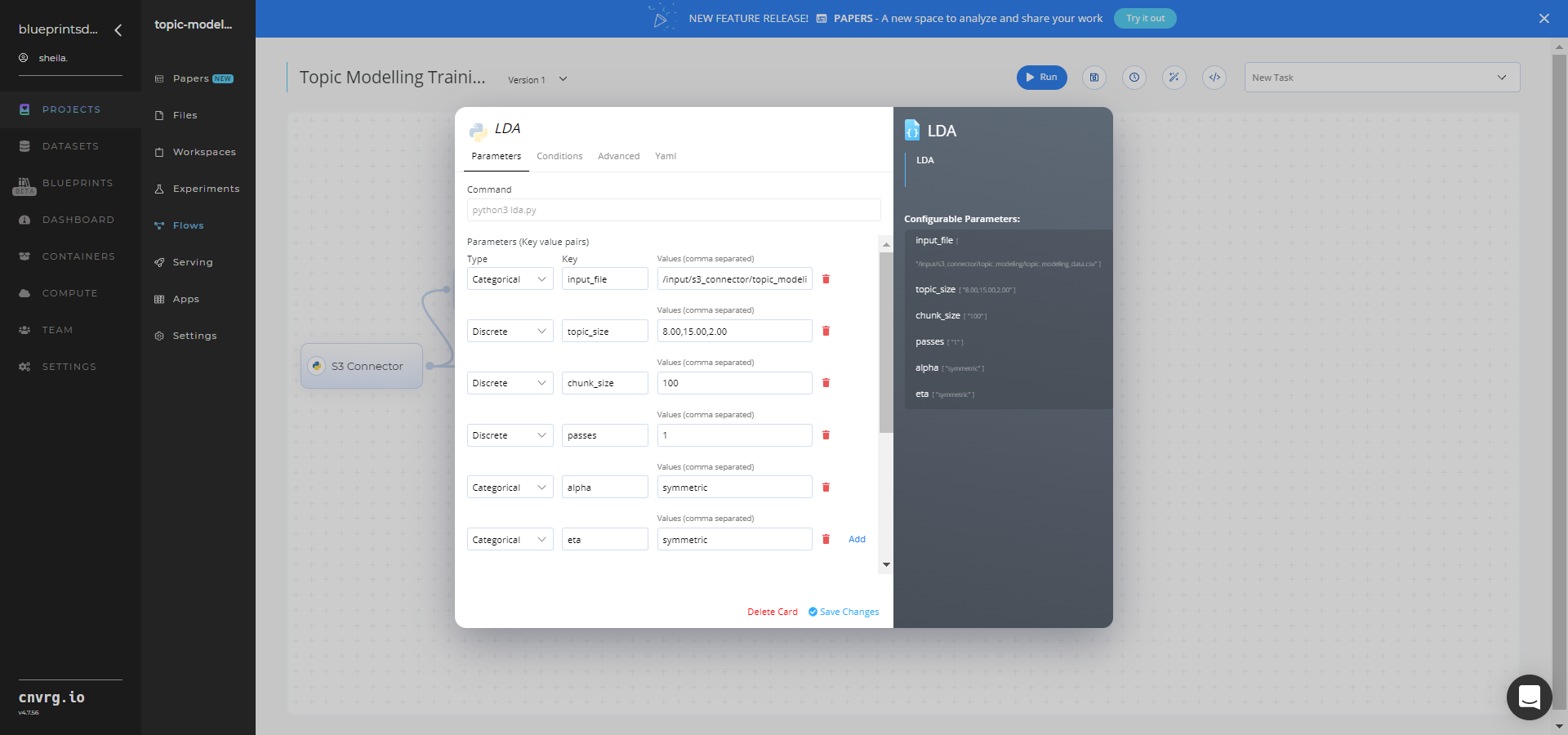
- Key:
input_file– Value: provide the path to the text data file including the S3 prefix /input/s3_connector/<prefix>/topic_modeling_data.csv− ensure the CSV file path adheres this format
NOTE
You can use the prebuilt example data paths provided.
- Key:
Click the Advanced tab to change resources to run the blueprint, as required.
Click the NMF task to display its dialog.
Within the Parameters tab, provide the following Key-Value pair information:
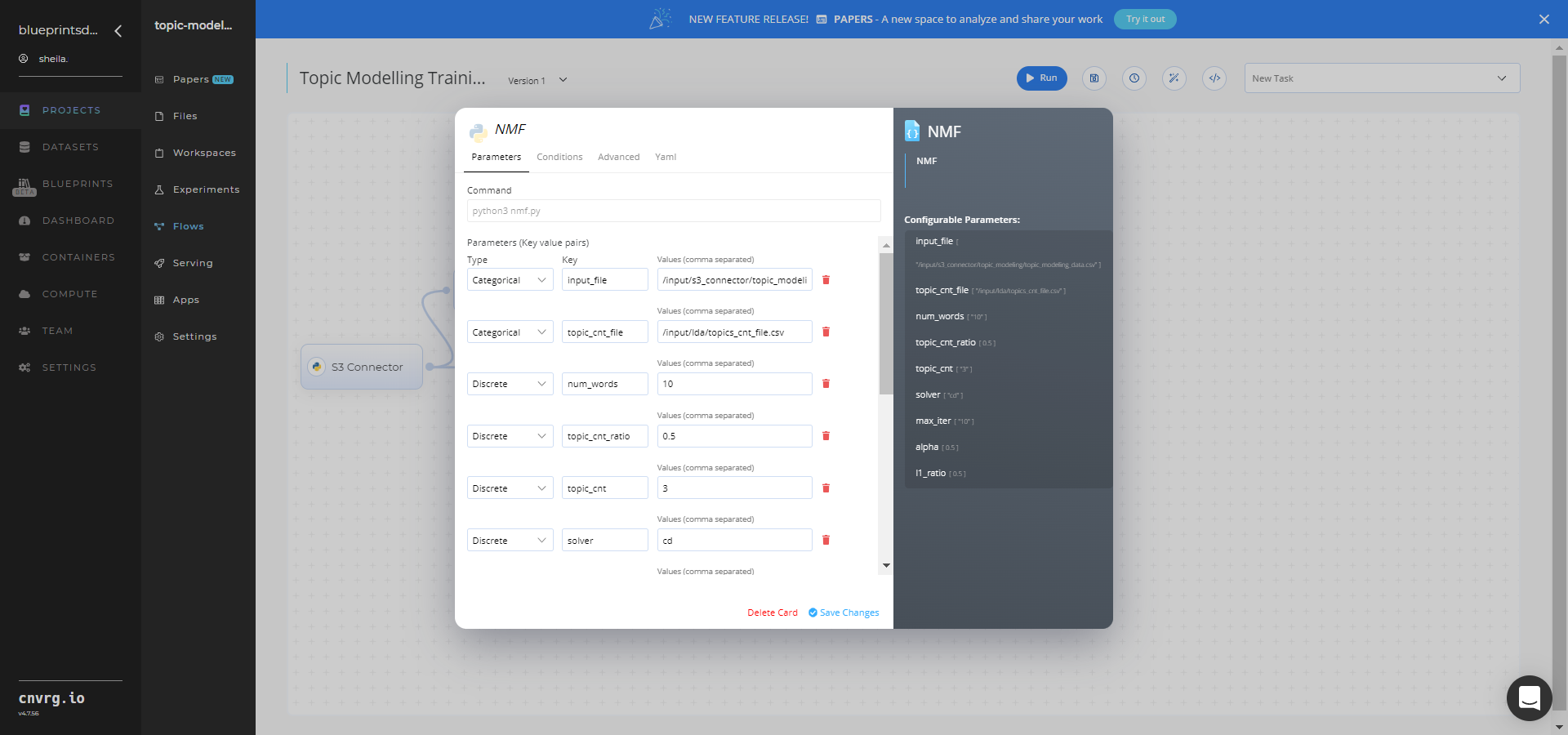
- Key:
input_file– Value: provide the path to the text data file including the S3 prefix /input/s3_connector/<prefix>/topic_modeling_data.csv− ensure the CSV file path adheres this format
NOTE
You can use the prebuilt example data paths provided.
- Key:
Click the Advanced tab to change resources to run the blueprint, as required.
Click the Run button.
 The cnvrg software launches the training blueprint as set of experiments, generating a trained topic-extractor model and deploying it as a new API endpoint.
The cnvrg software launches the training blueprint as set of experiments, generating a trained topic-extractor model and deploying it as a new API endpoint.NOTE
The time required for model training and endpoint deployment depends on the size of the training data, the compute resources, and the training parameters.
For more information on cnvrg endpoint deployment capability, see cnvrg Serving.
Track the blueprint's real-time progress in its Experiments page, which displays artifacts such as logs, metrics, hyperparameters, and algorithms.
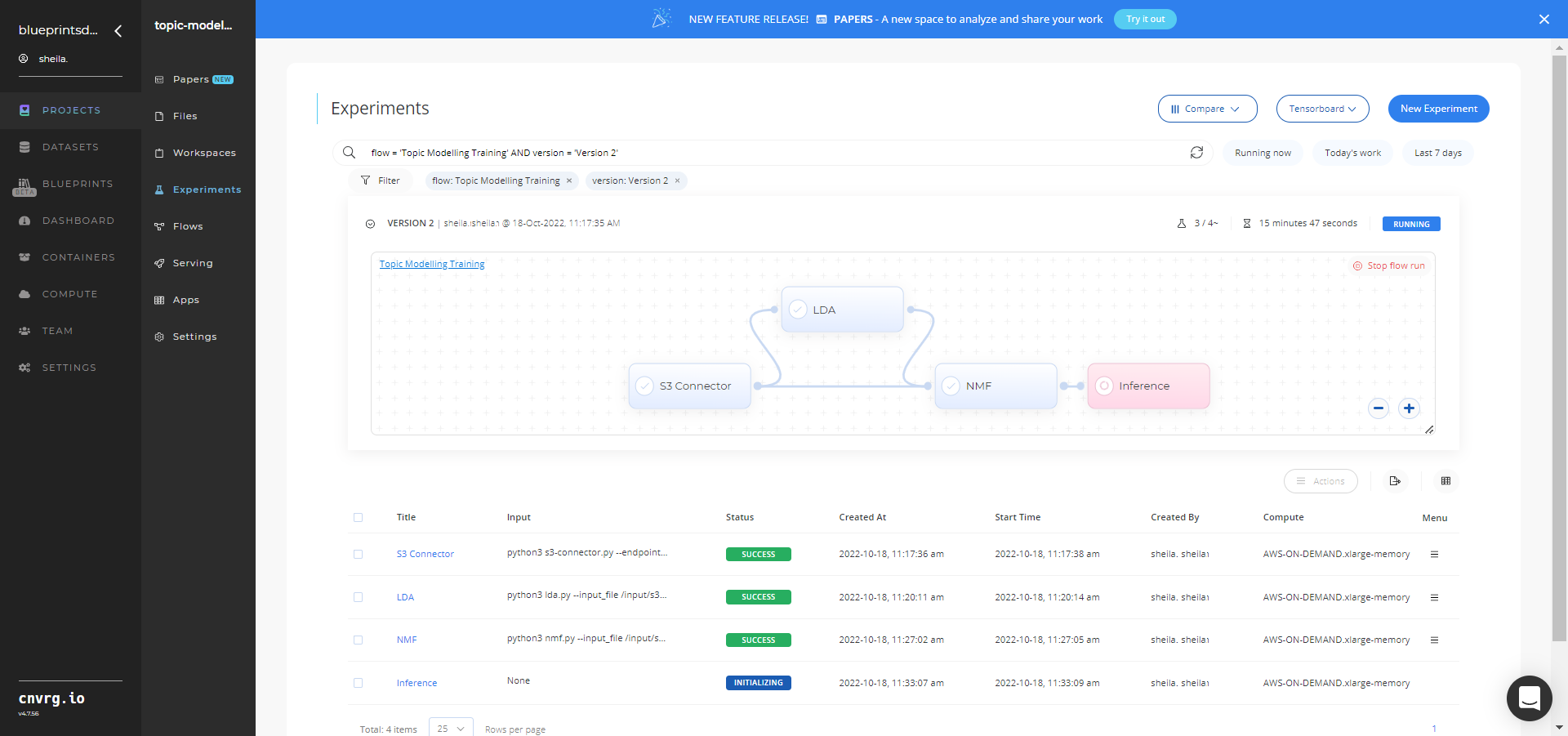
Click the Serving tab in the project and locate your endpoint.
Complete one or both of the following options:
- Use the Try it Live section with any text to check the model.
- Use the bottom integration panel to integrate your API with your code by copying in the code snippet.
- Use the Try it Live section with any text to check the model.
A custom model and an API endpoint, which can extract text topics, have now been trained and deployed. For information on this blueprint's software version and release details, click here.
# Connected Libraries
Refer to the following libraries connected to this blueprint:
# Related Blueprints
Refer to the following blueprints related to this training blueprint: