# MetaGPU Overview - deprecated from 08/2024
- Architecture
- Processor Review for Managing Compute
- Other Considerations
- How it works
- Known Limitations
- Memory Enforcement
# Architecture
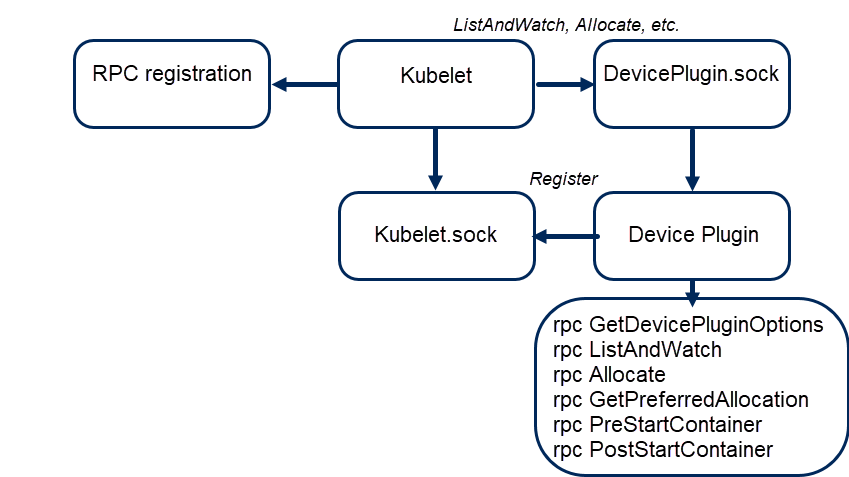
- Kubernetes Device Plugin Framework
- gRPC based service
- Communicate through unix socket
- Required to implement the gRPC service
- Required to implement the gRPC client registration call
# Processor Review for Managing Compute
GPU stands for Graphics Processing Unit. It is a specialized processor designed for parallel computing tasks. GPUs can perform many calculations simultaneously, making them ideal for tasks that involve large amounts of data and complex mathematical operations.
When working with a GPU machine for data science, keep in mind how processor and memory allocation impact performance:
| Component | Description |
|---|---|
| Number of GPUs | The more GPUs you have, the more parallel processing power you will have, which can significantly speed up training times for large machine learning models |
| Memory of GPUs | The amount of memory on your GPUs will determine how much data you can load onto them at once. If your models require a lot of data, you may need to use multiple GPUs with large amounts of memory. |
| CPU | he CPU (Central Processing Unit) is responsible for managing the overall operation of the system, including loading data onto the GPU, performing preprocessing, and running other applications. |
| Memory RAM | The RAM (Random Access Memory) on your system is also important because it determines how much data you can hold in memory at once. If you are working with very large datasets, you may need a system with a lot of RAM to avoid running out of memory during training. |
# Other Considerations
- When working with a GPU machine, you will typically use a framework such as TensorFlow or PyTorch to develop and train your machine learning models.
- These frameworks are designed to take advantage of the parallel processing capabilities of GPUs, allowing you to train large models much more quickly than would be possible on a CPU-based system.
# How it works
The MetaGPU Device Plugin (MGDP) is a tool that allows for efficient utilization of GPU resources in Kubernetes. It is built on top of Nvidia Container Runtime and
go-nvml(Nvidia Management Library written in go).MGDP works by detecting all available GPU device IDs and generating meta-device IDs based on them.
When a user requests a specific fraction of a GPU, for example, 0.5 GPU, MGDP will allocate, 50 meta-device IDs that are bound to 1 real device ID. This real device ID is then injected into the container. By using fractions, a data scientist can slice GPU allocation and quickly learn the minimum viable configuration for most any machine learning workload.In contrast to the
nvidia-smi, each metagpu container will have themgctlbinary. Themgctlbinary offers better security and integration with Kubernetes.From the command line in the container, use these
mgctlcommands:List gpu processes and their metadata.
mgctl get process

Get GPU devices. View the runtime container's UUID, MEMORY, SHARES , and SIZE.
mgctl get devices

# Known limitations
- Once MetaGPU is enabled in your environment, allocating GPU resources will by the device
cnvrg.io/metagpu(instead ofnvidia.com/gpu).
Since the request for MetaGPU is for a device which cloud providers aren’t familiar with, it will not trigger scale up of a GPU node when all nodes are scaled down (0 nodes available). if at least 1 node is active, scale up for more nodes will be triggered as needed. - GPU memory is divided relatively to the amount of GPU requested. For example requesting 0.5 GPU will also allocate 50% of the GPU memory of the unit.
In case of different GPU cards within the cluster, the sharing units will not equal (0.5 a100 != 0.5 v100) Workaround: compute templates should be created relatively to the machine, using node taints/labels that represent the type of machine - Memory enforcement is disabled by default, if enabled (through the cluster's configmap) it will affect all processes and terminate processes that over commit
Workaround: Using environment variables to specify a memory limit to the execution on the code level. for more info, see Memory allcation guide - No support for GPU processing time (GPU throttling)
- No support in MIG
# Memory Enforcement
Memory Enforcement refers to the amount of gpu memory that is guaranteed to be available for a container when using the MetaGPU. It is enabled by default, which means that the container will not be allowed to use more gpu memory than the amount specified as enforcement memory, even if more memory is available on the host machine. any process that over commits will be killed.
This can be useful for ensuring that a program does not exceed the available GPU memory and cause crashes or other issues.
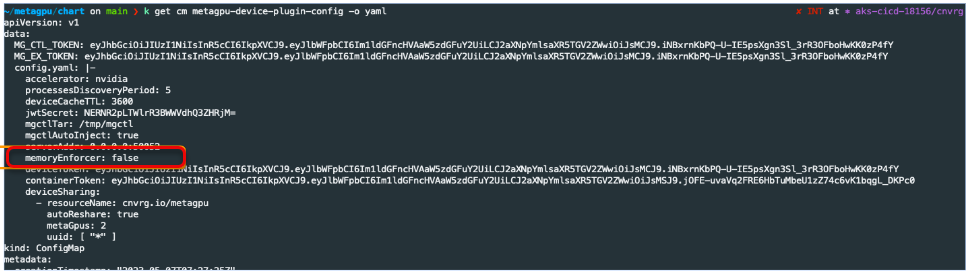
memory enforcement can be disabled on the cluster level through the device plugin configmap.
kubectl -n cnvrg edit cm metagpu-device-plugin-config
#### navigate to 'memoryEnforcer', change to 'false'
memoryEnforcer: false