# Simple Flow with Two Tasks
cnvrg provides you with an easy way to build machine learning pipelines called flows). With cnvrg flows, you can build DAG pipelines where artifacts and parameters automatically move between tasks.
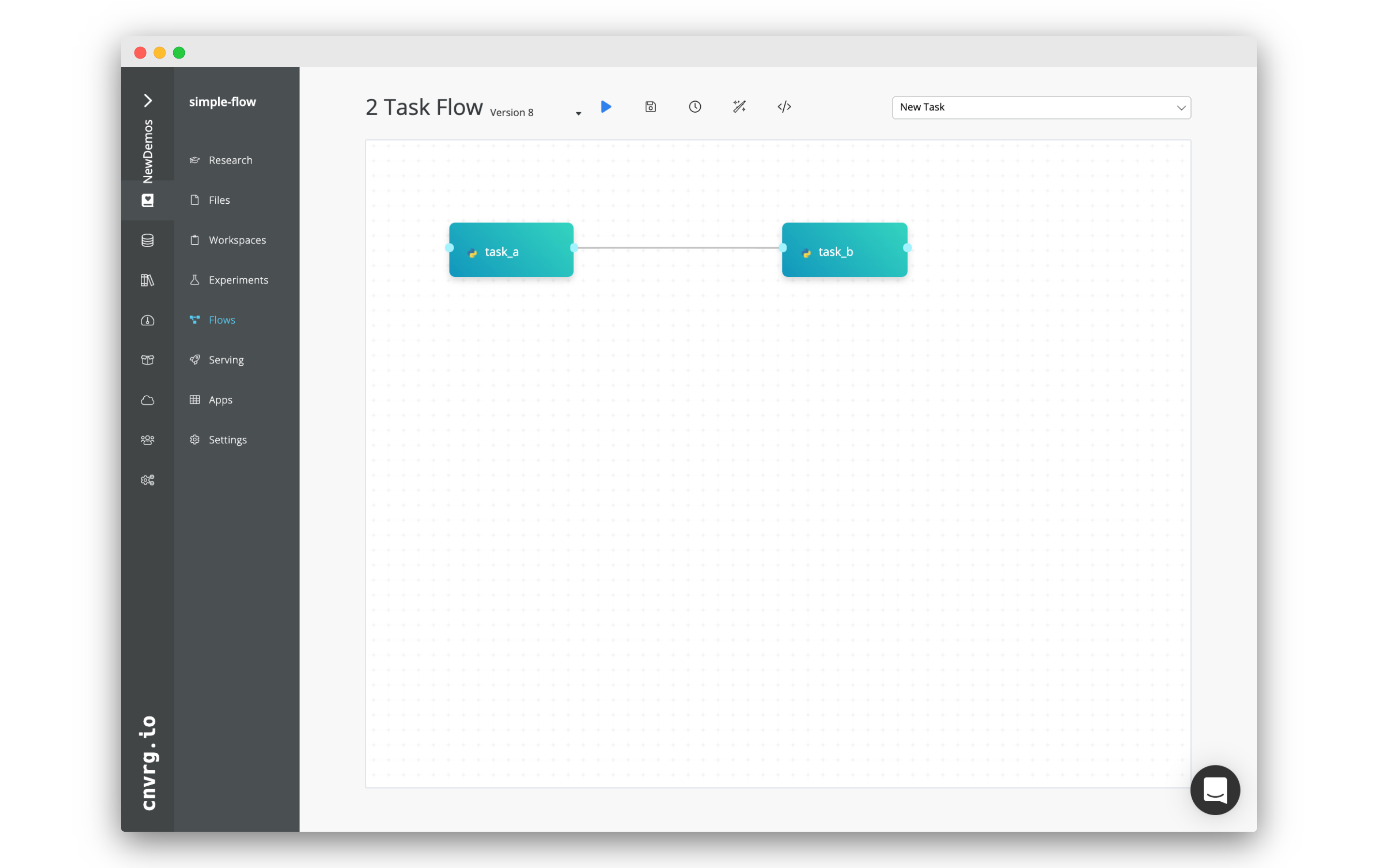
In this tutorial, we will create a simple flow with two tasks (Task A and Task B). We will build the pipeline such that artifacts and parameters from Task A will be automatically available in Task B.
# Create Project and the Two Tasks
Flows exist as part of a project in cnvrg. To get started, create a new project:
- Go to Projects.
- Click Start Project.
- Set the title as "Simple Flow"
- Click Create The new project will be created.
Now, we will create the two tasks scripts, and upload them to cnvrg
# Task A: Python script that creates artifacts, parameters and metrics
Task A represents a simple Python script that once executed, simulates the creating of a few artifacts, parameters and metrics. We will use the Python SDK to create the parameters and metrics.
Parameters and Metrics:
random_accuracy- we will use thelog_paramPython SDK method to track a random value.partition- when a user sets a parameter when running a task or experiment, cnvrg automatically logs it.random-chart- a chart created with 100 random metrics using the Python SDK.
Artifacts:
task-a-image-artifact.png- a simple image created using the Pillow Python library.task-a-text-artifact.txt- a text file containing the value of thepartitionparameter.
To create the file for Task A:
- Go to the Files tab of your project.
- Click New File.
- Name the file
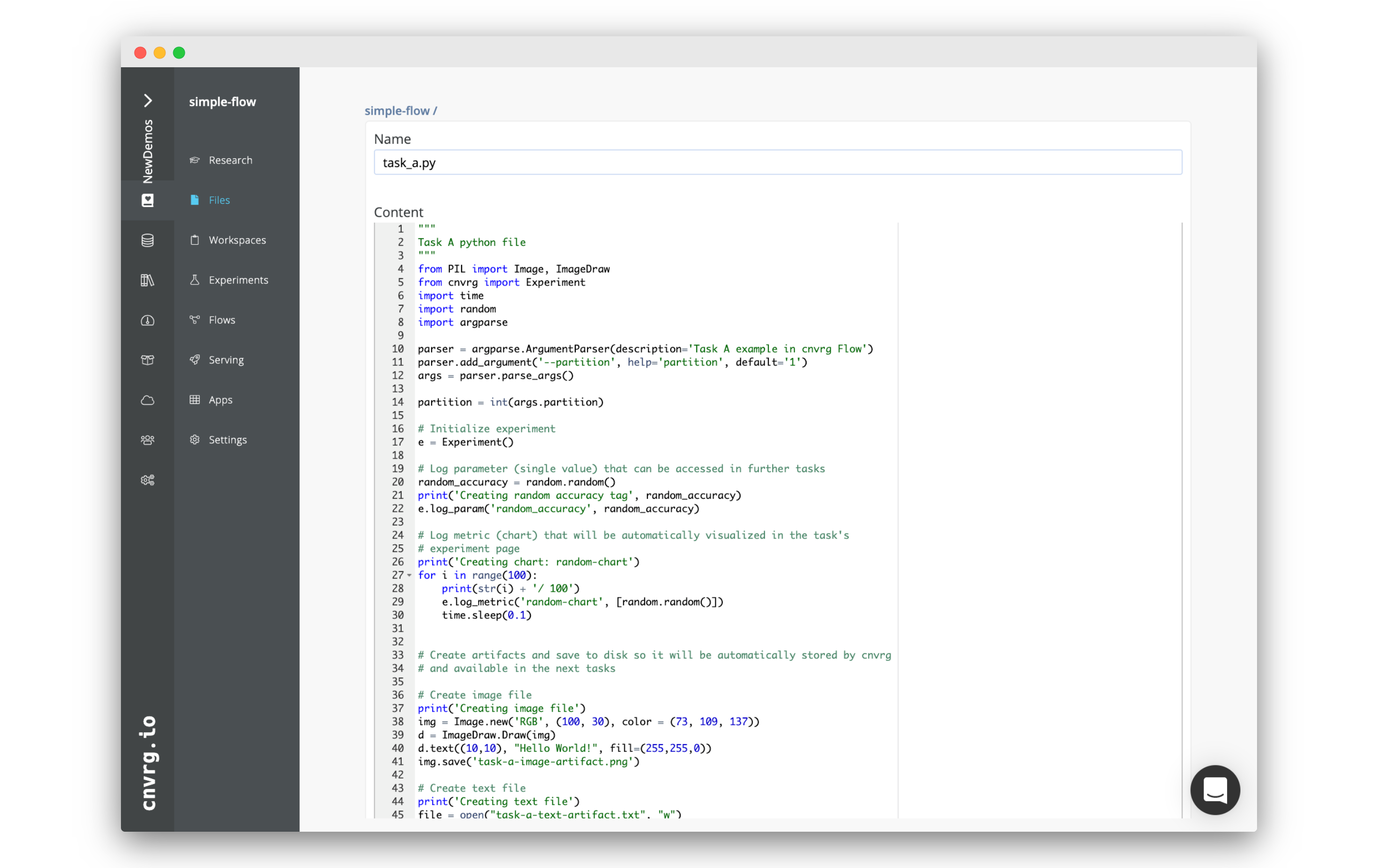
task_a.py. - In the code editor, paste the following code, and then click Submit:
"""
Task A python file
"""
from PIL import Image, ImageDraw
from cnvrg import Experiment
import time
import random
import argparse
parser = argparse.ArgumentParser(description='Task A example in cnvrg Flow')
parser.add_argument('--partition', help='partition', default='1')
args = parser.parse_args()
partition = int(args.partition)
# Initialize experiment
e = Experiment()
# Log parameter (single value) that can be accessed in further tasks
random_accuracy = random.random()
print('Creating random accuracy tag', random_accuracy)
e.log_param('random_accuracy', random_accuracy)
# Log metric (chart) that will be automatically visualized in the task's
# experiment page
print('Creating chart: random-chart')
for i in range(100):
print(str(i) + '/ 100')
e.log_metric('random-chart', [random.random()])
time.sleep(0.1)
# Create artifacts and save to disk so it will be automatically stored by cnvrg
# and available in the next tasks
# Create image file
print('Creating image file')
img = Image.new('RGB', (100, 30), color = (73, 109, 137))
d = ImageDraw.Draw(img)
d.text((10,10), "Hello World!", fill=(255,255,0))
img.save('task-a-image-artifact.png')
# Create text file
print('Creating text file')
file = open("task-a-text-artifact.txt", "w")
file.write("Text file generated in Task\nPartition: " + str(partition))
file.close()
# Task B: Python script that reads artifacts & parameters from Task A
Task B represents a simple Python script that during execution, reads the artifacts and parameters from Task A.
Using parameters as inputs
Task B expects an input argument task_a_accuracy. When defining the flow, we will pass
a
{{ task_a.random_accuracy }}
to the parameter task_a_accuracy. cnvrg will parse this
template tag and convert it to a value automatically.
Using parameters as environment variables
Task B will read the partition parameter created in Task A using the
environment variable task_a_partition that was generated automatically by cnvrg during the flow
execution.
Accessing artifacts
Task B will read and print the contents the artifact task-a-text-artifact.txt
that was created during Task A, and was automatically made available locally in the workdir of Task B.
To create the file for Task B:
- Go to the Files tab of your project.
- Click New File.
- Name the file
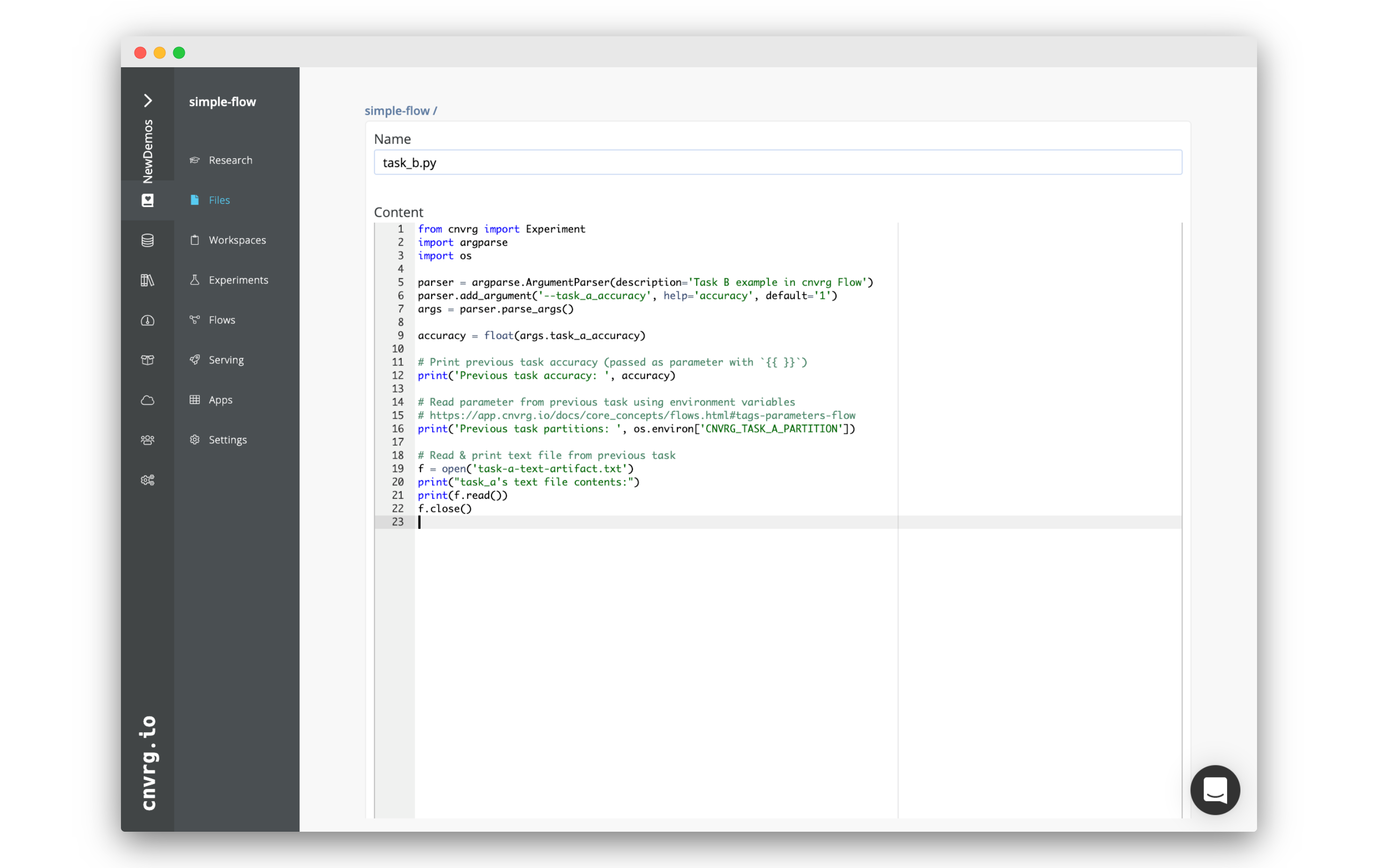
task_b.py. - In the code editor, paste the following code, and then click Submit:
from cnvrg import Experiment
import argparse
import os
parser = argparse.ArgumentParser(description='Task B example in cnvrg Flow')
parser.add_argument('--task_a_accuracy', help='accuracy', default='1')
args = parser.parse_args()
accuracy = float(args.task_a_accuracy)
# Print previous task accuracy (passed as parameter with `{{ }}`)
print('Previous task accuracy: ', accuracy)
# Read parameter from previous task using environment variables
# https://app.cnvrg.io/docs/core_concepts/flows.html#tags-parameters-flow
print('Previous task partitions: ', os.environ['CNVRG_TASK_A_PARTITION'])
# Read & print text file from previous task
f = open('/input/task_a/task-a-text-artifact.txt')
print("task_a's text file contents:")
print(f.read())
f.close()
# Creating the Flow
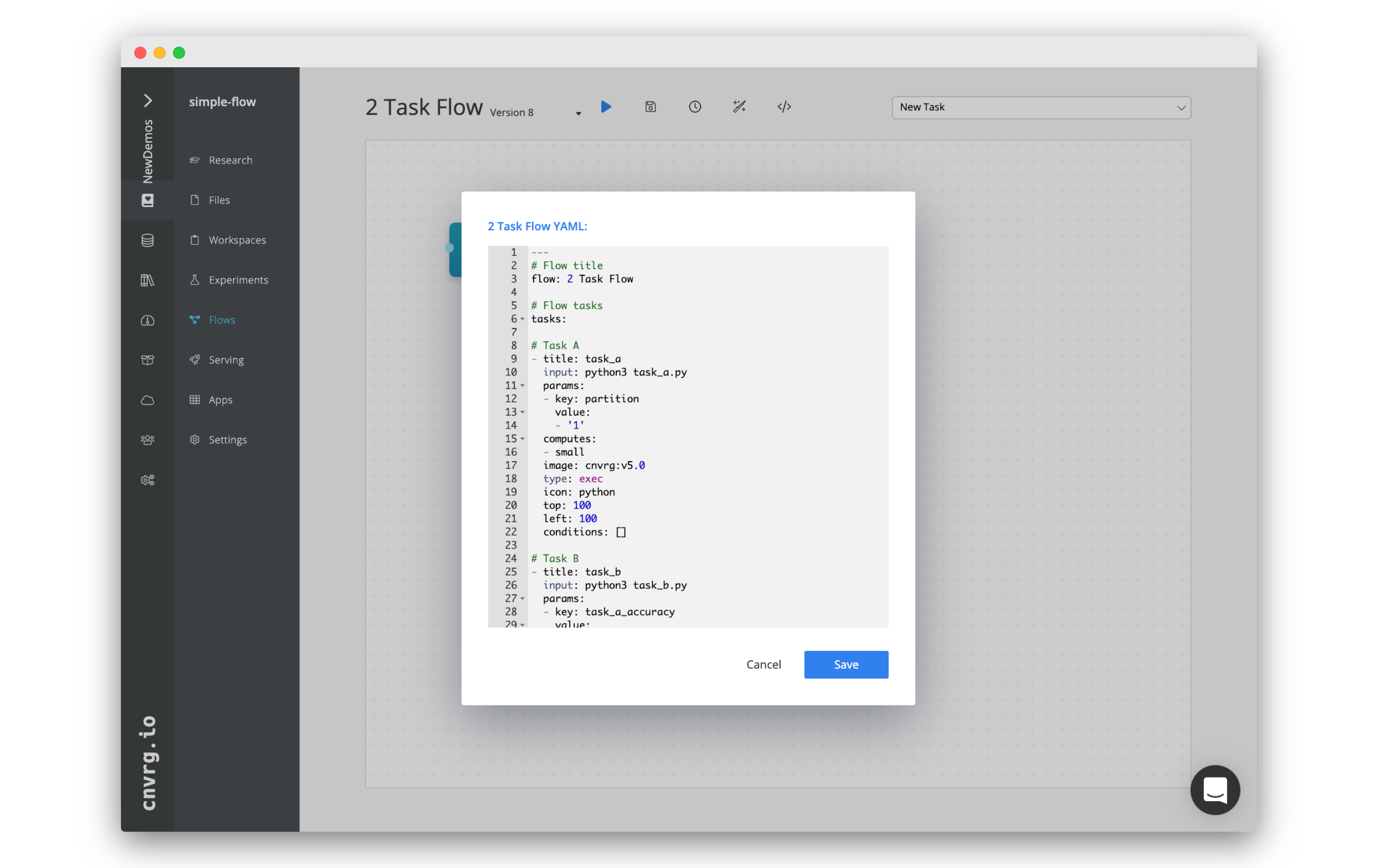
Now that we have created the tasks scripts, we can create the flow.
To make it even easier, we've prepared a flow YAML that
can just copy paste to get your flow ready.
We recommend reviewing the YAML beforehand.
To create the flow:
- Go to the Flows tab of your project.
- Click New Flow.
- Click the
YAMLbutton in the upper header of the Flow window.
- Copy and paste the following snippet in the YAML editor.
- Click Save.
---
# Flow title
flow: 2 Task Flow
# Flow tasks
tasks:
# Task A
- title: task_a
input: python3 task_a.py
params:
- key: partition
value:
- '1'
computes:
- small
image: cnvrg:v5.0
type: exec
icon: python
top: 100
left: 100
conditions: []
# Task B
- title: task_b
input: python3 task_b.py
params:
- key: task_a_accuracy
value:
- "{{ task_a.random_accuracy }}"
computes:
- small
image: cnvrg:v5.0
type: exec
icon: python
top: 100
left: 500
conditions: []
# Links between tasks
relations:
- from: task_a
to: task_b
TIP
You can change the value for the partitions parameter in either the YAML or by clicking on the task and editing it there. The value you choose will be passed into Task B!
Now your flow should be updated, and look like the image below:
# Running the Flow
We're all set to run the flow. Click the Play button (blue arrow). A popup should appear.
Confirm you want to run the flow by clicking Run.
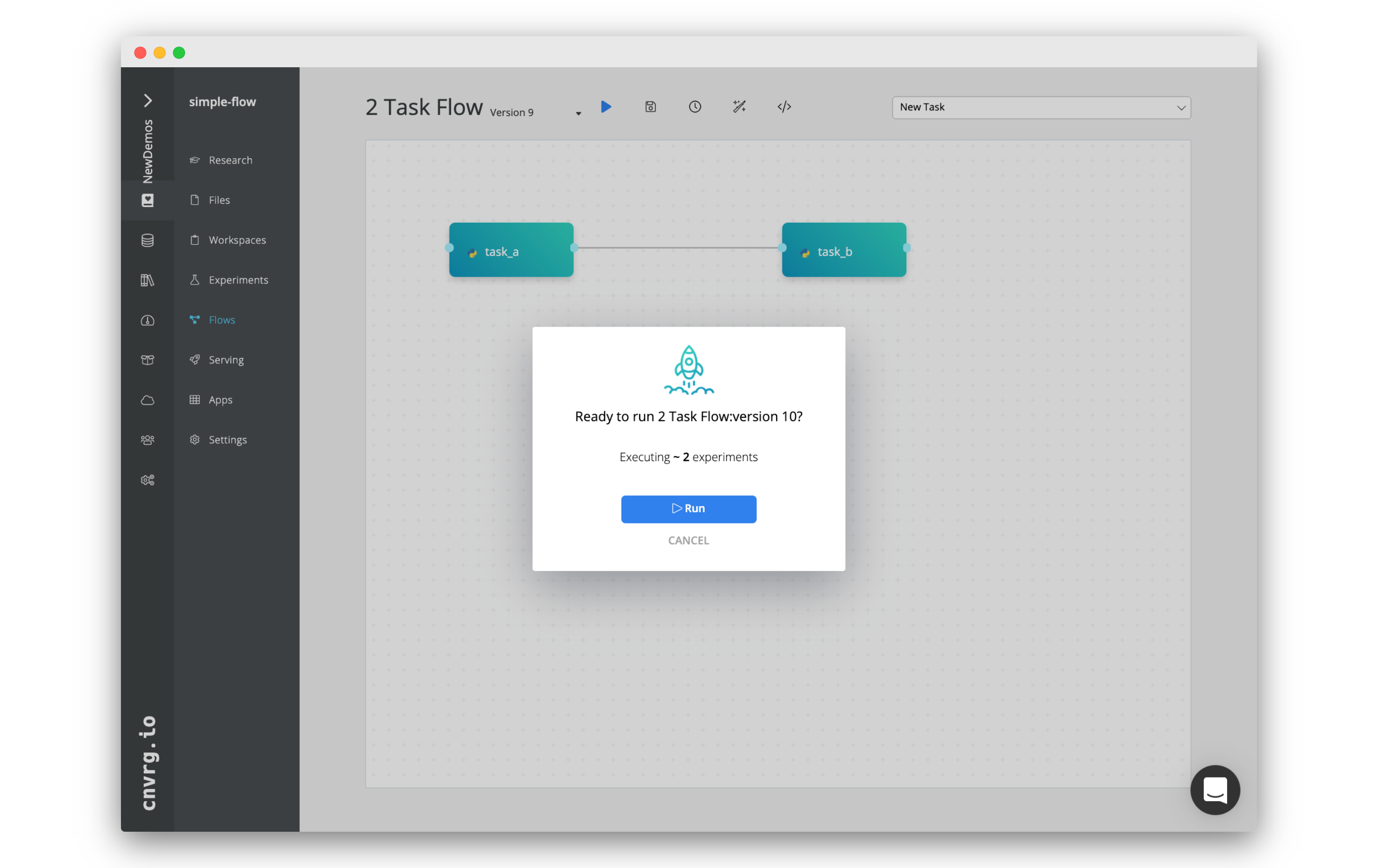
cnvrg will now run the flow and do all of the backend MLOps. Executing the code in the tasks and ensuring the data flows easily between Task A and Task B.
# Flow Runs (experiments)
To accommodate for grid searches and different execution paths, when a flow is run, each 'run' of the flow is tracked separately and can be found in the experiments table for the project.
In our case, there is only one flow run, as we had a single execution path, and did not run a grid search. When you clicked Run, you were redirected to the experiments page with a filter set so that only the runs for the flow are visible. Click on the name of our flow run: "task_a > task_b".
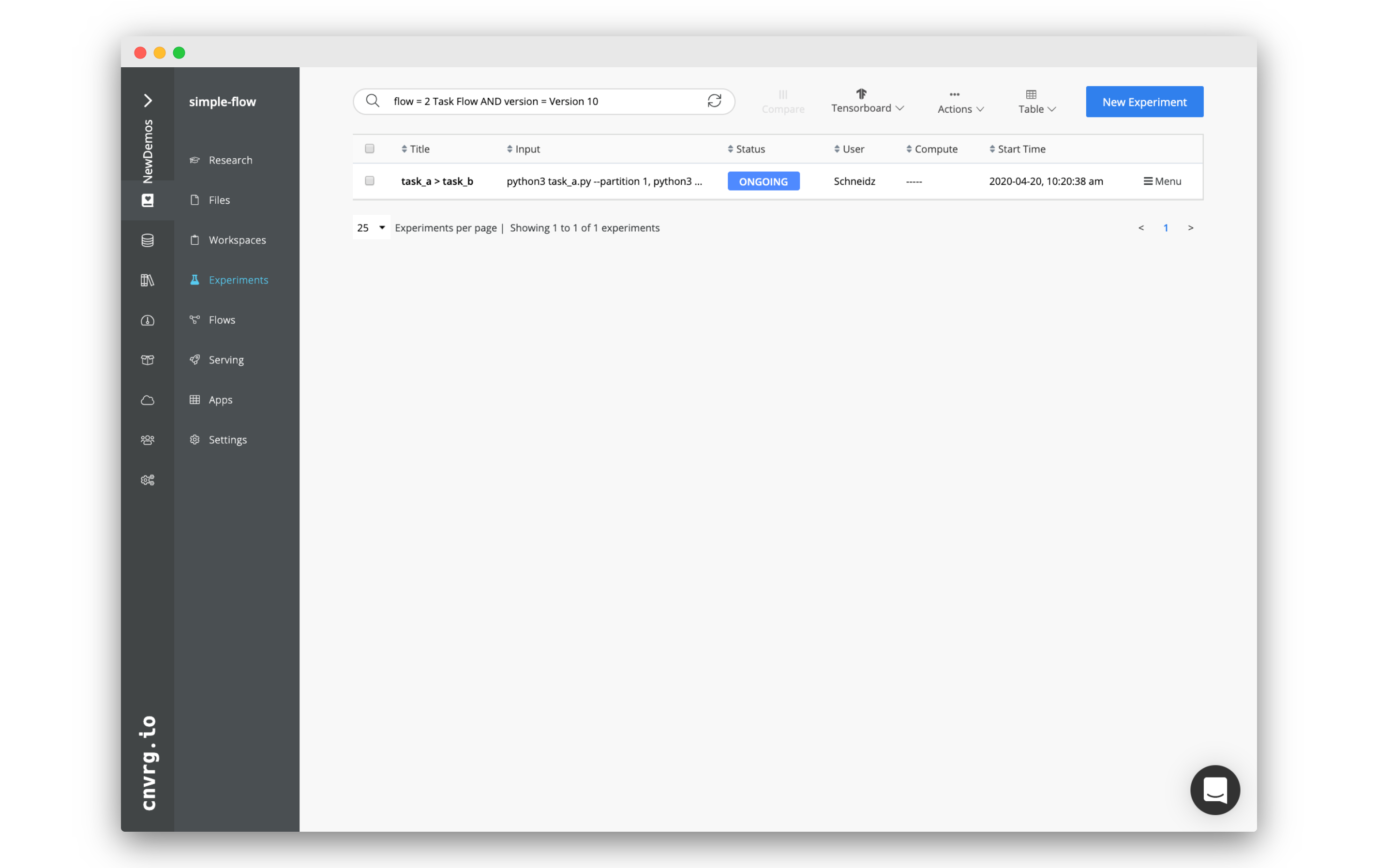
# The Flow Run Page
At the top of a flow run page are various pieces of information specific to the flow. For instance, if you wanted to abort the flow, or see the other experiments in the flow, you could find the necessary links and buttons along the top.
Each task in a flow run has its own page, accessible through the tabs along the top of the page. Note that there is one for task_a and task_b. Make sure you are on task_a.
# task_a's experiment page
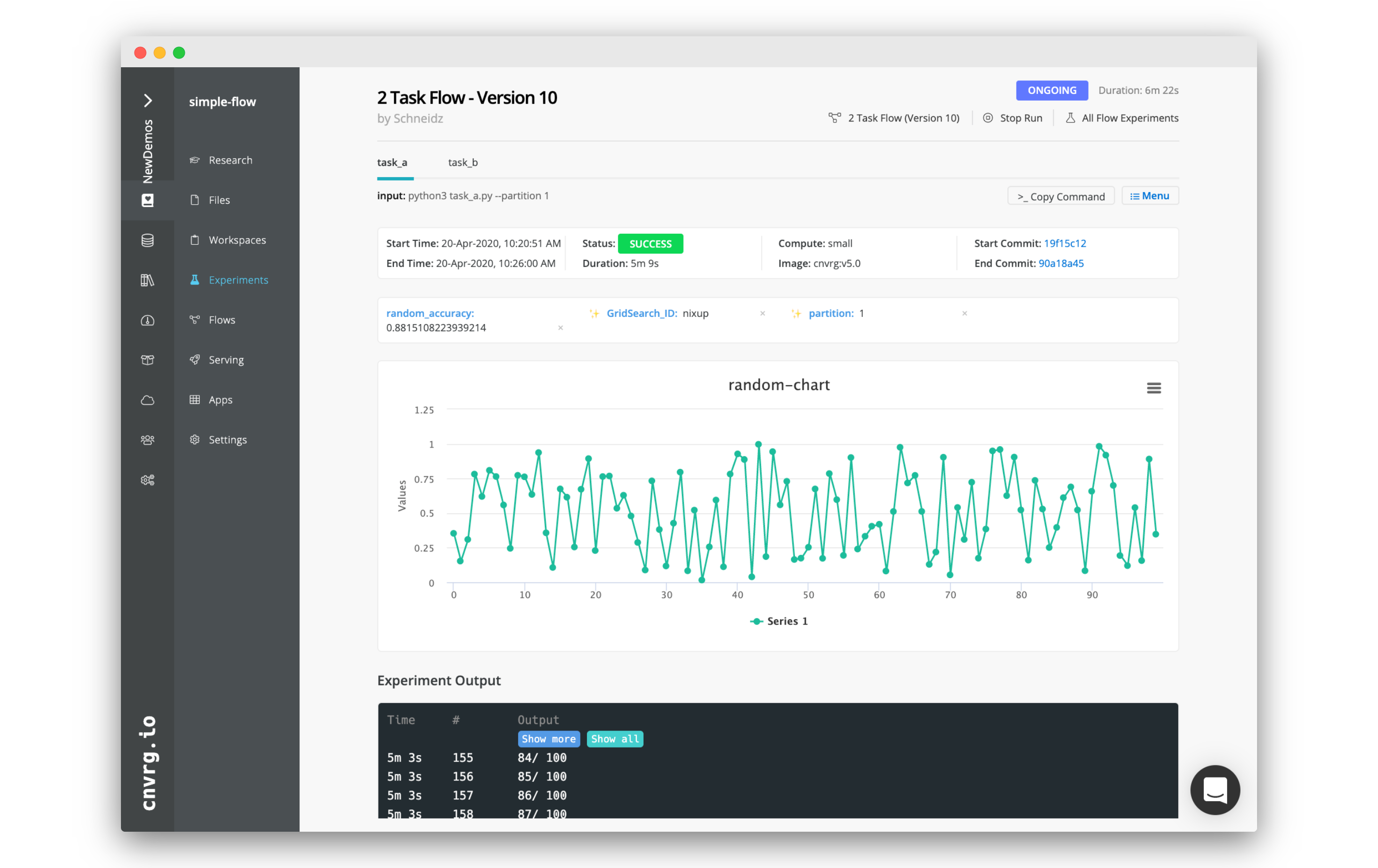
You should now be able to see everything that happened in task_a. For example, all of the information of the task is along the top.
You will alos find all the parameters/tags from the task. The important ones for this task being random_accuracy and partitions. Note both these values.
Below you can find the graph that we constructed using the Python SDk named random-chart.
Further down are the logs from the experiment.
Finally, below the logs, you can find the different artifacts we created: task-a-text-artifact.txt and task-a-image-artifact.png. Click on ask-a-image-artifact.png to check out the image you made! Finally, check task-a-text-artifact.txt to see the contents of the text file.
When task_a finished running, task_b started. All of the metrics and artifacts that we just observed will be made available in task_b automatically. Let's check out task_b to make sure everything worked.
# task_b's experiment page
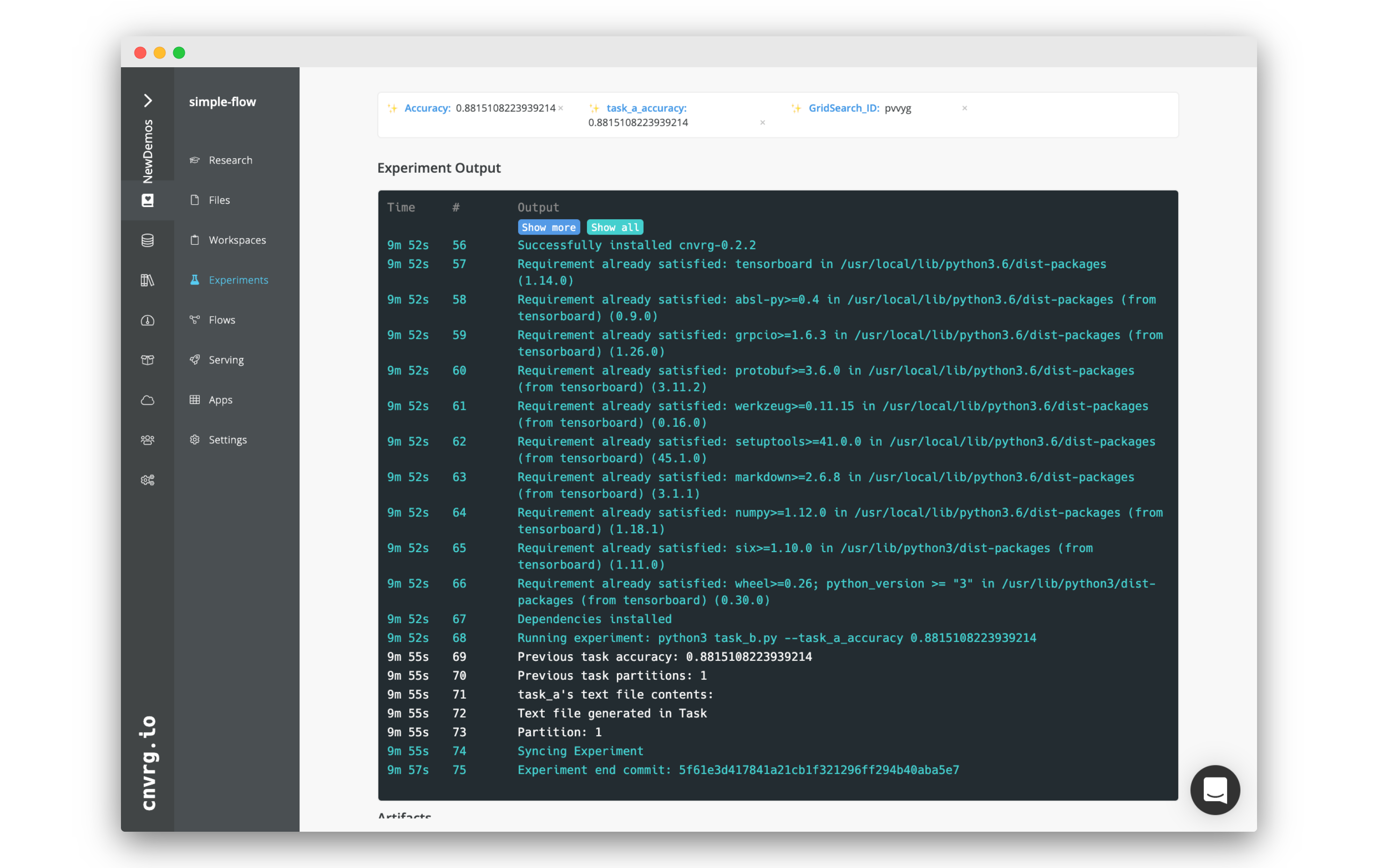
Click the task_b tab on the top of the flow run page.
The page is very similar to task_a's page with some key differences.
Note that in the metrics box, the task_a_accuracy tag will have the value of the random_accuracy tag from task_a.
In the logs, you should also be able to see the line that reads: Previous task partitions: X, where X is the amount of partitions you set in task_a (1 by default).
The logs should also have a copy of the contents of the text file that was created in task_a. It will match what we saw on task_a's page.
# Conclusion
Flows allow you to create DAGs where all of the backend, data flow and MLOps are fully handled by cnvrg. This example showed how you can access information and artifacts from preceding tasks.
This was just a simple example, demonstrating the basic principles of flows. Of course, the possibilities are limitless! You can build from this simple example into truly complex end-to-end machine learning pipelines, incorporating code, data, production services and AI Library's components.
For more information, consult the flows docs page.